本章不仅是关于庆祝懒惰。它还通过实例和实验,教给大家用传统方式构建数据应用和用Spark构建数据应用之间的根本区别。
懒惰至少有两种:当你已经致力于做其他事情时,在树下睡觉;为了以最聪明的方式完成工作,提前思考。虽然在这个精确的时刻,我的脑海里想的是躺在树荫下,主要是受到科西嘉岛的Asterix的启发,但在这一章中,我将展示Spark是如何通过优化其工作量来让你的生活更轻松。你将了解转换(数据过程的每一步)和动作(完成工作的触发器)的基本作用。
你将在一个来自美国国家健康统计中心的真实数据集上工作。该应用程序旨在说明Spark在处理数据时所经历的推理。本章只关注一个应用程序,但它包含了三种执行模式,这三种模式对应着三个实验,你将通过运行这些实验来更好地了解Spark的 "思维方式"。
我从Java的角度涵盖了变换和动作。很多在线文档都是关于Scala的,在这里,我认为我改进了信息,以更好地覆盖Java。最后,你会对Spark的内置优化器Catalyst有一个更深入的了解。像RDBMS查询优化器一样,它可以转储查询计划,这对调试很有用。你将学习如何分析它的输出。
附录I是本章的参考指南,它包含了转换的列表和操作的列表。
LAB 本章的例子可以在GitHub上找到:https://github.com/jgperrin/net.jgp.books.spark.ch04。
一个高效懒惰的真实例子
大多数时候,懒惰是与一种消极的行为联系在一起的。当我提到懒惰的时候,你可能会立刻想到懒惰,在树下打盹儿,胡闹而不是工作。但还有更多的东西吗?在本节中,让我们来看看懒惰和聪明之间是否有联系。
我一直在想,聪明的人是不是比别人更懒。这个理论的基础是,聪明人在做一件事之前会多想一些。
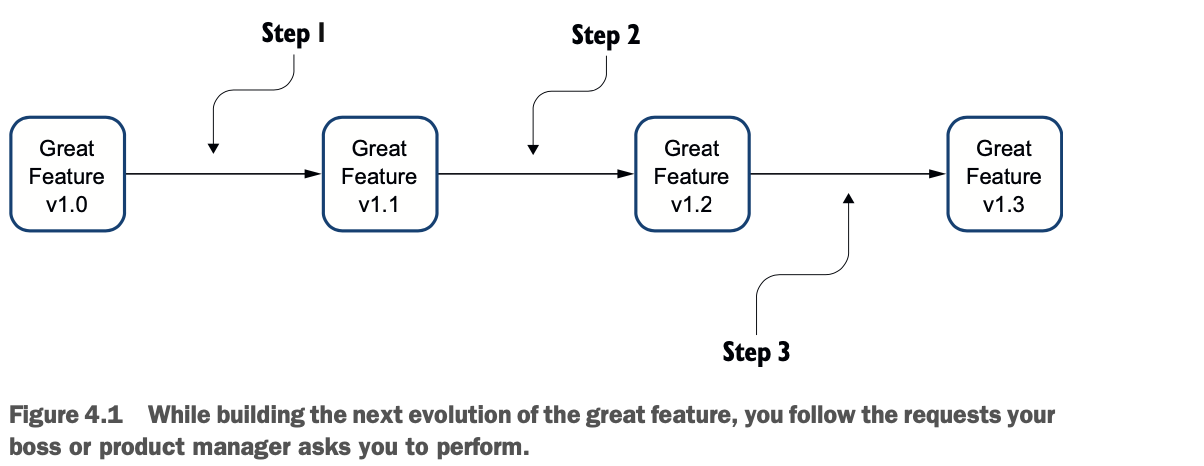
让我们用下面的方式来思考这个问题。你的老板(或产品经理)要求你构建你的伟大功能的1.1版本,然后他把他的要求修改为稍微不同的东西。现在你要构建1.2版本。最后,他要求你记住第一个版本,并对原来的版本功能做稍微的修改。这就是1.3版本。当然,这是一部虚构的作品。名字、企业、事件、敏捷的借口和功能都是我想象的产物。任何与真实的人,活着的或死去的人,或真实的事件的相似之处,纯属巧合。你也从来没有发生过,对吧?尽管如此,图4.1还是说明了这个思路。
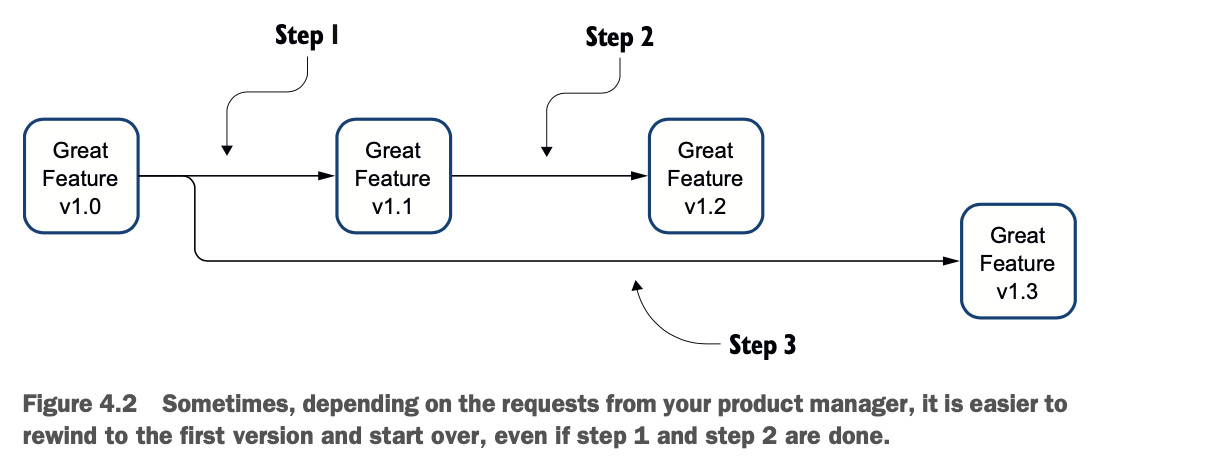 另一种方法是回到 1.0 版本,然后从那里进行修改,如图 4.2 所示。
另一种方法是回到 1.0 版本,然后从那里进行修改,如图 4.2 所示。
这可能就是为什么要发明Git(甚至是cvs或sccs)这样的源码控制工具。
如果你事先知道老板的修改要求,你会同意图4.2所示的第二种工作方式是首选吧?这是一种更懒惰,但又更聪明的工作方式。在下一节,你将看到如何将其应用到Spark中。实际上,即使你在开始之前不知道v1.3中的功能,你可能还是从v1.0开始更安全,只是为了确保你不会处理诱发的bug。
一个Spark高效懒惰的例子
在上一节中,你了解了日常生活中聪明的懒惰是什么样子的。本节通过一个具体的例子将其移植到Apache Spark中。
最重要的是,你将明白为什么Spark会偷懒,以及为什么这对你有好处。你还将做以下工作。
* 理解你将运行的实验来理解Spark的转换和动作。
* 观察几次变革和行动的结果。
* 看看实验背后的代码
* 仔细分析结果,看看时间都花在了什么地方
从转换和行动的结果看
变换和动作是Spark的面包和黄油。在本节中,你将为你将要执行的实验设置上下文(或者至少是走一遍)。在这个例子中,你将加载一个数据集并测量性能,以了解工作的进展情况。
在本书中,我以show()方法结束大多数例子。这是一种快速查看结果的有效方法,但它并不是真正典型的最终目标。一个集合操作(在你的代码中的collect())允许你以Java列表的形式检索整个数据框架,允许进一步的处理,如创建一个报告,发送电子邮件等等。这通常是最后的操作之一,因为你最终完成了你的应用程序。在Spark的词汇中,这被称为一个动作。
为了理解转换和动作的概念,并通过这个概念理解懒惰操作的概念,你将在实验室#200中执行三个实验。
* 实验1 - 加载一个数据集,并执行一个集合动作。
* 实验2- 加载一个数据集,执行转换(通过复制和数学运算创建三列),并执行收集操作。
* 实验3- 加载一个数据集,执行一个转换(通过复制和数学运算创建三列),丢弃新创建的列,并执行一个收集动作。这个实验将说明Spark的懒惰性。
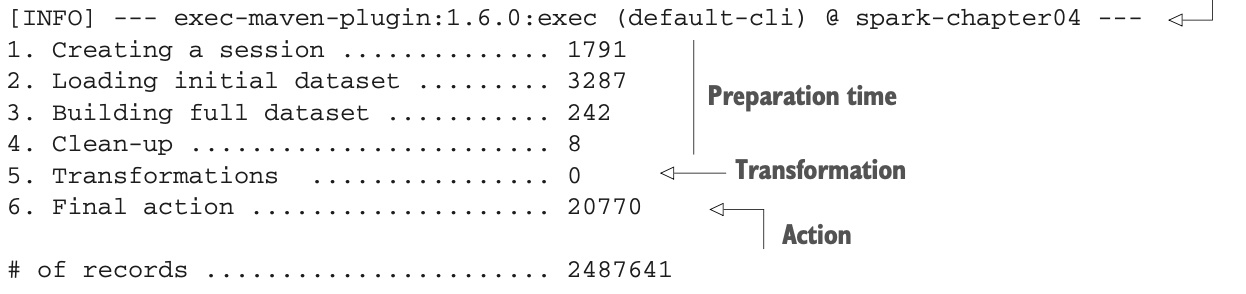
你的数据集包含大约250万条记录。详细结果见表4.1。
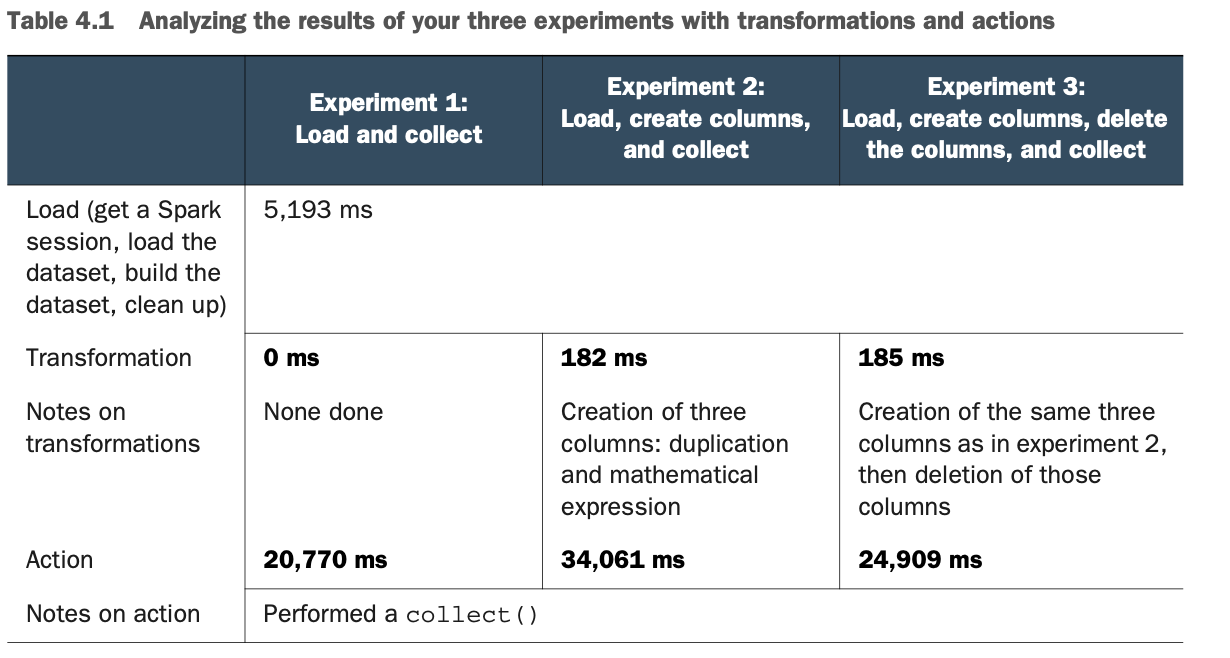 我希望表4.1中的一些结果对你来说是奇怪的。如果不是,这里有一些提示。
我希望表4.1中的一些结果对你来说是奇怪的。如果不是,这里有一些提示。
* 通过转换,你刚刚创建了三列250万条记录 所以大约750万个数据集,用了182毫秒。很快吧?
* 在执行动作时,如果你不做任何转换,动作大约需要21秒。如果你创建三列,动作需要34秒。但如果你创建并删除这些列,动作大约需要25秒。这是不是很奇怪?你已经猜到了,这是由于懒惰造成的。
让我们更详细地看看这个过程,以及你可以构建的代码来填充表4.1。那么你就有了解决这两个谜团的线索。
转型过程,步步为营
在上一节中,您看到了转换过程的结果以及结果中的异常情况。在本节中,您将更详细地探索这个过程,然后再看代码,然后深入探究其中的奥秘。
这个过程本身是非常基本的。你要做的是以下工作。
1 获取一个新的Spark会话
2 加载一个数据集。在这个例子中,你将使用来自美国国家健康统计中心(NCHS)的数据,该中心是美国疾病控制和预防中心(CDC)的一个部门,可在www.cdc.gov/nchs/index.htm。该数据集包含了美国各县和各州每年的平均青少年出生率。您可以在 http://mng.bz/yz6e 找到更多信息,该数据集包含在实验室的数据目录中。
3 将数据集复制几次,使其更大一些。示例中包含的文件包含40,781条记录。这个数字有点低:当你研究一个特定的机制或处理时,你可能会看到副作用条件。Spark的设计是分布式的,是为了处理大量的记录,而不是仅仅40000条记录。因此,你会通过执行数据集与自身的联合来增加数据集。我知道这并没有太多的商业价值,但我没有找到一个更大但不巨大的数据集(从而打破GitHub的100MB限制)。
4清理工作。在外部数据集上总要做一点清理工作。在这种情况下,你将重命名一些列。
5 执行转换。这些分为三种类型:不进行转换,创建额外的列,最后,创建列并删除。
6 最后,采取操作。
图4.3说明了这个过程。注意,转换将在步骤5中运行。这将根据我们的三个实验而变化。
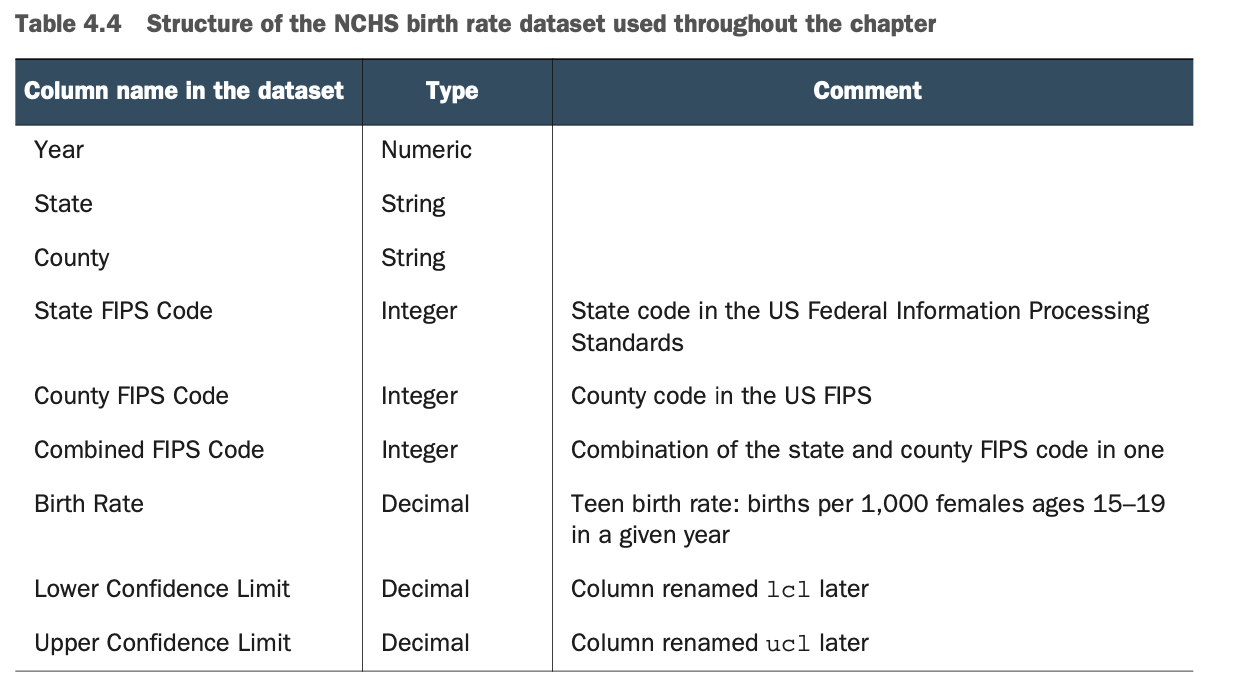
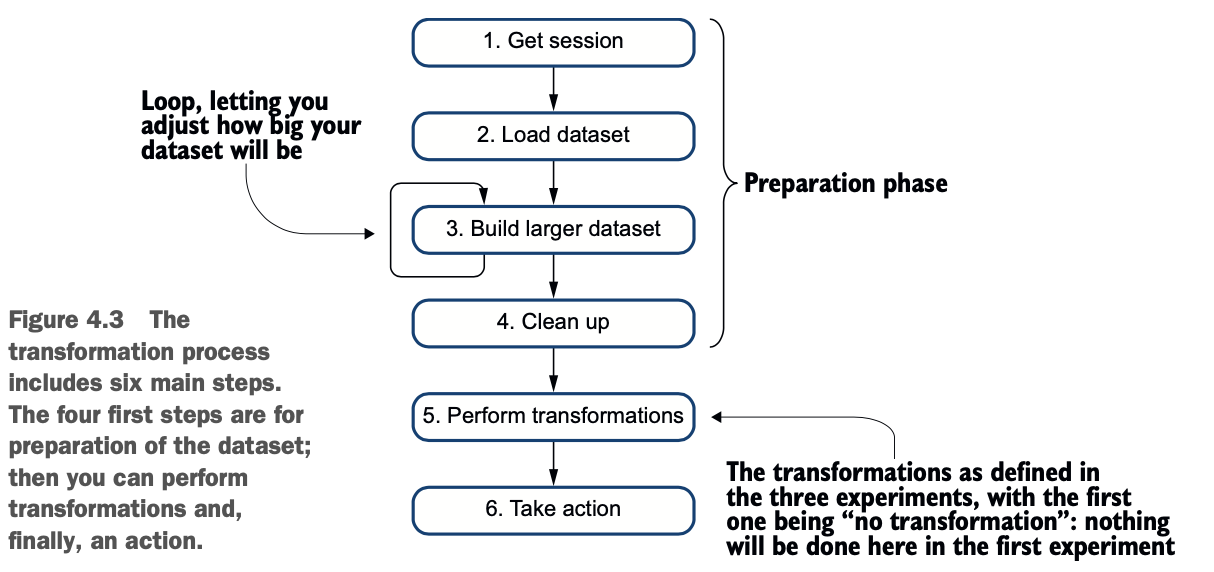 表4.2详细说明了数据集的结构。你所使用的NCHS数据集包含了2003年到2015年美国15到19岁青少年的出生率,按县划分。这个数据集的基调有点严肃,但在本书的写作过程中,我希望使用有意义的、现实生活中的数据集。每一个数据集都是一个基础,你也可以在本章之外使用它。
表4.2详细说明了数据集的结构。你所使用的NCHS数据集包含了2003年到2015年美国15到19岁青少年的出生率,按县划分。这个数据集的基调有点严肃,但在本书的写作过程中,我希望使用有意义的、现实生活中的数据集。每一个数据集都是一个基础,你也可以在本章之外使用它。
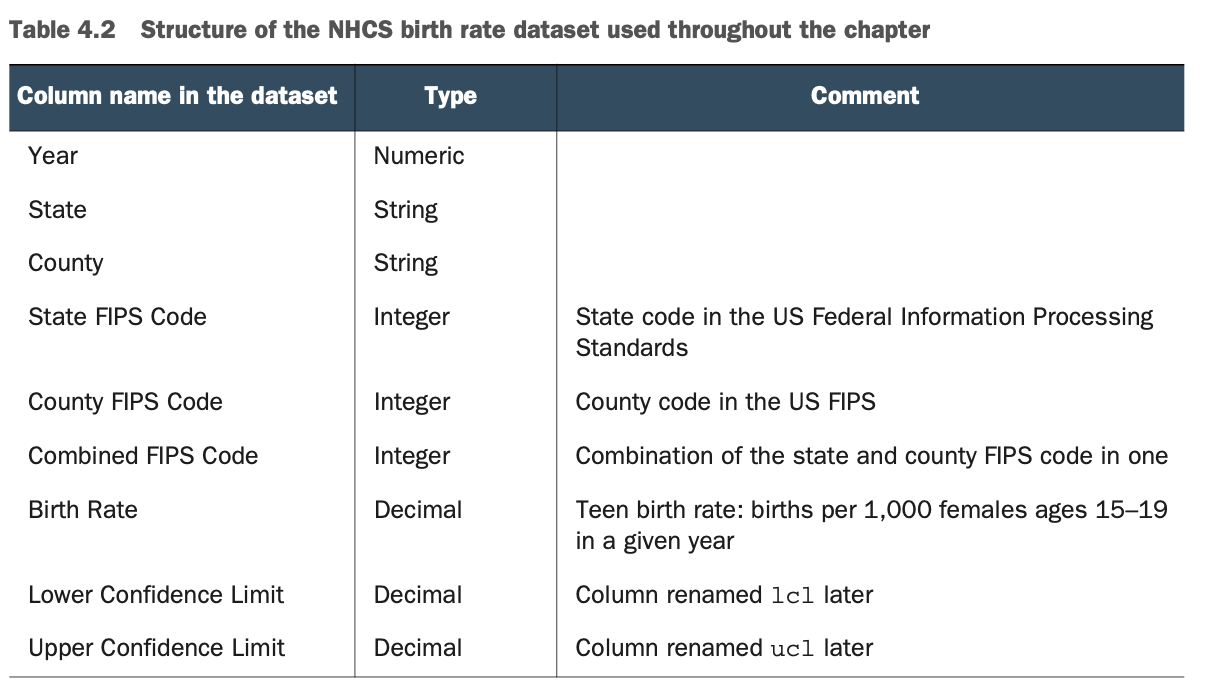
用FIPS使政府数据标准化
联邦信息处理标准(FIPS)是由美国联邦政府制定的公开宣布的标准,用于非军事政府机构和政府承包商的计算机系统。
你可以在美国国家标准与技术研究所(NIST)网站(www.nist.gov/itl/fips-general-information)和维基百科(https://en.wikipedia.org/wiki/Federal_Information_Processing_Standards)上阅读更多关于FIPS的信息。
在这个数据集中,最后两列分别是置信度的下限和上限。这表示出生率的置信度。
信心极限是统计学的一部分
你可能已经知道了,本书中使用的所有较大的数据集都来自真实世界,并不是为了学习而编造的。因此,有时你会发现一些奇怪(或不寻常)的术语。
这个数据集包含置信度下限和上限。置信限是置信区间的上端和下端的数字。这个区间是根据观察到的数据的统计量计算出来的,应该包含一个未知的群体参数的真实值,基于观察到的数据。你不需要计算它,它是你使用的数据集的一部分。
关于置信限和置信区间的更多解释,请参见John H. McDonald所著的《生物统计手册》(Sparky House Publishing,2014,www.biostathandbook.com/confidence.html)和维基百科(https://en.wikipedia.org/wiki/Confidence_interval)。
转变/行动过程背后的代码
在前面的章节中,你看到了过程的结果(表4.1),了解了实验中使用的过程细节,并查看了数据集的结构。现在,是时候看看代码和如何运行它了。
你将在命令行上用三个不同的参数执行三次代码。代码会根据参数自动调整。使用命令行可以让你更容易地连锁命令,多次运行测试以比较结果,平均结果,并更容易尝试其他平台。你将使用Maven。如果需要,请查看附录B的安装。
本节绝不是对如何执行基准的科学描述,然而,它说明了时间花在哪里。
你可以通过使用命令行参数在一个命令中运行三个实验。你将运行clean和编译/安装,然后运行每个实验。第一个实验是默认的,所以它不需要参数。命令行看起来像这样。
 执行结果如下:
执行结果如下:
 如果你想建立与表4.1相同的表,你可以在Microsoft Excel中复制数值。Excel表附在项目中。它的名字叫Analysis results.xlsx,在本章资源库的data文件夹中。
如果你想建立与表4.1相同的表,你可以在Microsoft Excel中复制数值。Excel表附在项目中。它的名字叫Analysis results.xlsx,在本章资源库的data文件夹中。
清单4.1有点长,但应该不难理解。
你的main()方法将确保你传递一个参数给start()方法,所有的工作都在这里。预期的参数如下(参数不区分大小写)。
* noop 表示没有操作/转换,在实验1中使用。
* Col用于创建列,用于实验2。
* 完整的过程,用于实验3。
start()方法将创建一个会话,读取文件,增加数据集,并作为准备阶段的一部分进行一点清理。然后你将执行转换和操作。
LAB Lab#200可在net.jgp.books.spark.ch04.lab200_transfor- mation_and_action包中找到。应用程序是TransformationAndActionApp.java。

 在第三步中,你将数据框架联合到自己身上,以创建一个更大的数据集(否则,Spark会太快,你无法衡量其好处):
在第三步中,你将数据框架联合到自己身上,以创建一个更大的数据集(否则,Spark会太快,你无法衡量其好处):
 第五步是实际的数据转换,不同的模式:
第五步是实际的数据转换,不同的模式:
 第6步是应用程序的最后一步,它调用的是动作:
第6步是应用程序的最后一步,它调用的是动作:
 collect()操作返回一个对象。该方法的完整签名显示在这里。
collect()操作返回一个对象。该方法的完整签名显示在这里。
Object collect()你可以忽略返回值,因为你对进一步处理不感兴趣。然而,在基准之外的情况下,你很可能会使用返回值。在接下来的章节中,你将仔细看看发生了什么。
182毫秒创造700万个数据点背后的奥秘
在前面的章节中,你看到转换过程在大约182毫秒内创建了超过700万个数据点。让我们看看你做了什么,Spark做了什么。
你的原始数据集包含40,781条记录。你将数据集本身复制了60次,这就创建了一个新的数据集,包含2,487,641条记录(约250万条记录)。在清单4.1中,这是通过以下代码完成的。
for (int i = 0; i < 60; i++) {
df = df.union(df0);
}在建立这个数据集后,你会创建三列:一列包含下限和上限的平均值,两列重复。这样就创建了3×2,487,641=7,462,923个数据点。你在创建列之前就启动了计时器,之后又马上停止了:你真的在182毫秒内创建了大约750万个数据点吗?
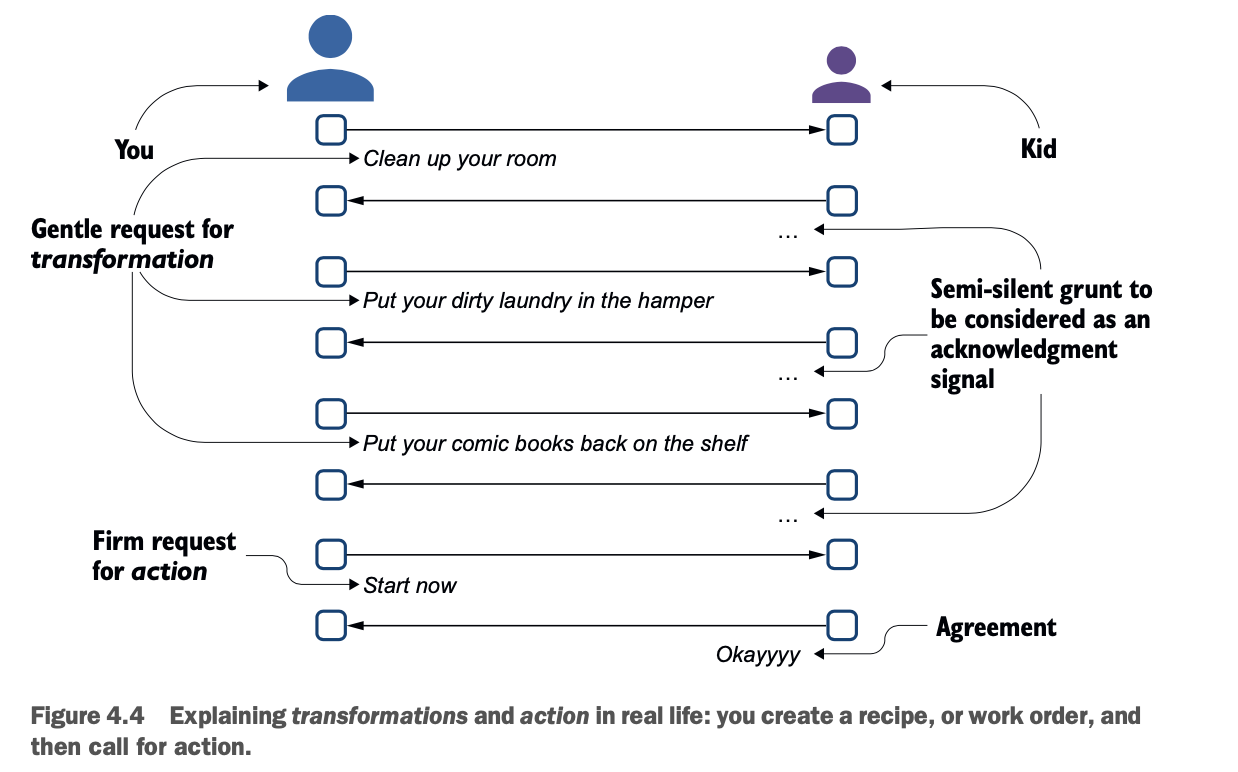
Spark只是在创建配方,当你调用一个动作时,会执行配方。这就是为什么Spark是懒惰的,有点像你要求你的孩子做某事,如图4.4所示。
我说的配方是什么意思?它是一个作业吗?
Spark将job定义为由多个任务组成的并行计算,这些任务在响应Spark动作(如save()、collect()等)时被生成。
Spark没有一个术语来描述转换列表,而转换列表是作业的重要组成部分。你会在第5章看到更多关于job的内容。
作为法国人,我与食物有这很强的关系,当然,与食物相关的类比-术语也很多。在我看来,把这一连串的变换称为食谱是很有意义的。烹饪中使用的一个术语是 "就地取材":在你开始烹饪之前,把所有的材料都测量、切割、去皮、切片、磨碎等等。如果你想把类比推得更远一点,你可以说所有的数据摄取都是 "就地取材",但这不是一本食谱,对吧?
总结一下。Spark处理的是作业,而一个作业由一定数量的转化组成,这些转化在一个食谱中被组合起来。
 Spark将这个配方实现为一个有向无环图(DAG)。
Spark将这个配方实现为一个有向无环图(DAG)。
什么是有向无环图?
我在本书中的承诺之一是跳过复杂的数学概念,所以如果你对数学过敏,请随意跳到下一节。
在数学和计算机科学中,有向无环图(DAG)是一个没有定向循环的有限有向图。该图由有限个顶点和边组成,每条边从一个顶点定向到另一个顶点,这样就没有办法从任何顶点v开始,按照一个持续的定向边序列,最终再次循环回到v。
同理,DAG是一个定向图,它有一个拓扑顺序,一个顶点的序列,使得每一条边都是从序列中较早的地方定向到较晚的地方。基本上,DAG是一个永不回头的图。
此信息改编自维基百科https://en.wikipedia.org/wiki/Directed_clic_graph。
在下一节,你将分析Spark是如何清洗(或优化)配方的。
行动时机背后的奥秘
在前面的章节中,你了解到了Spark的懒惰,以及它像个孩子一样,在你呼唤它的时候,它是如何等待你告诉它做所有的转变。所有读到这本书的爸爸妈妈们应该都能体会到。你还了解到,Spark将变换的配方存储在DAG中,基本上,DAG是一个永不倒退的图形。
所以,正如你所记得的,你做了三个实验。表4.3总结了配方和时间。
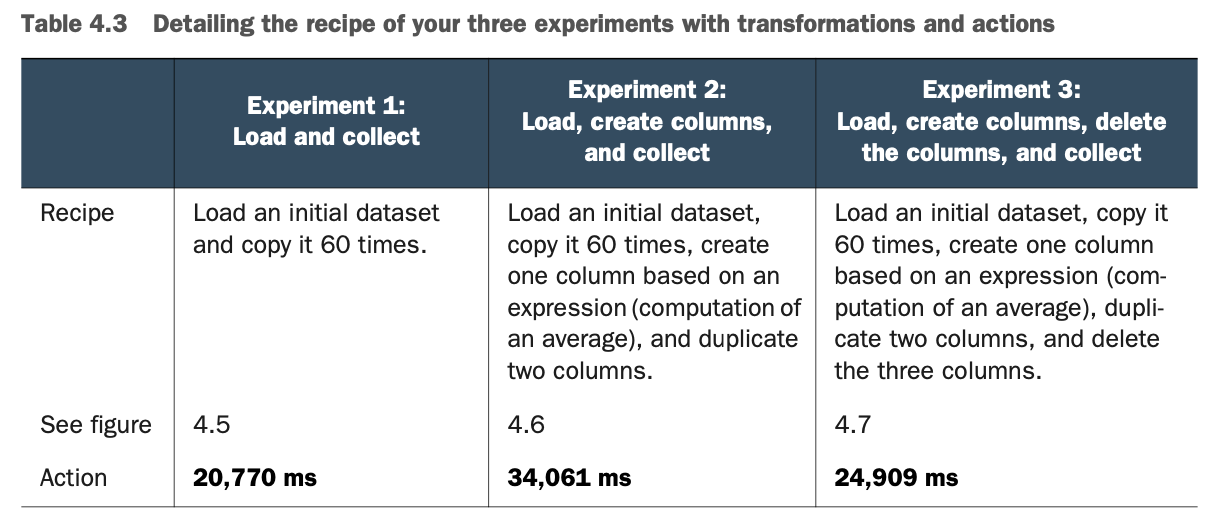 图4.5描述了第一个实验的变换配方。你加载数据集,把它复制60次到自己身上,然后清理。这个过程在我的笔记本电脑上花了大约21秒。
图4.5描述了第一个实验的变换配方。你加载数据集,把它复制60次到自己身上,然后清理。这个过程在我的笔记本电脑上花了大约21秒。
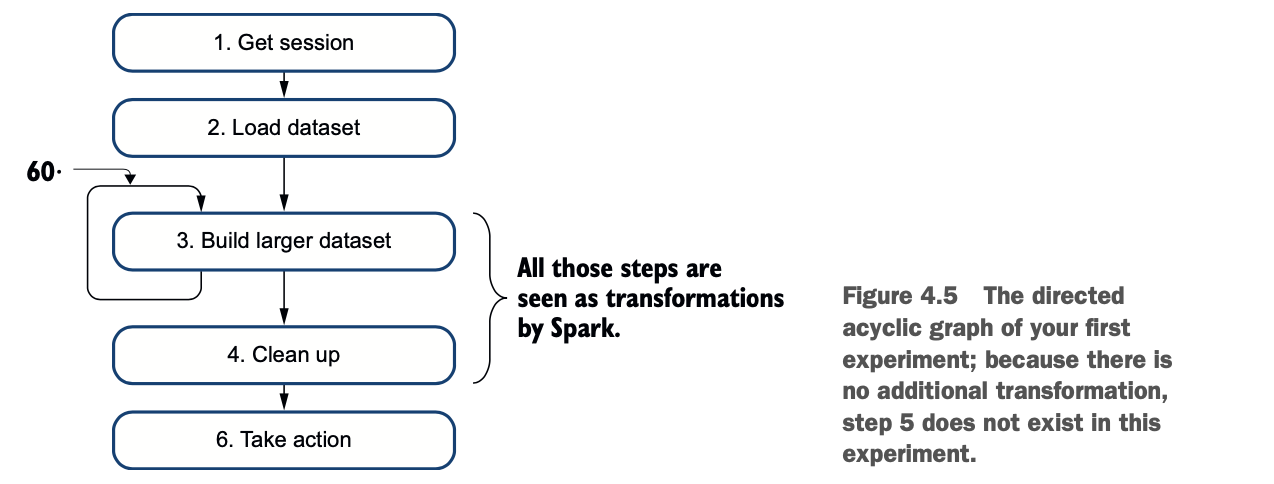 图4.6描述了第二个实验中使用的配方:第五步出现了变换。该动作需要更多的时间是有道理的,因为它将在此时执行所有的转换。
图4.6描述了第二个实验中使用的配方:第五步出现了变换。该动作需要更多的时间是有道理的,因为它将在此时执行所有的转换。
1 构建更大的数据集。
2 进行清理。
3 计算平均值。
4 复制lcl列。
5 复制ucl列。
这个过程在我的笔记本电脑上花了大约34秒。
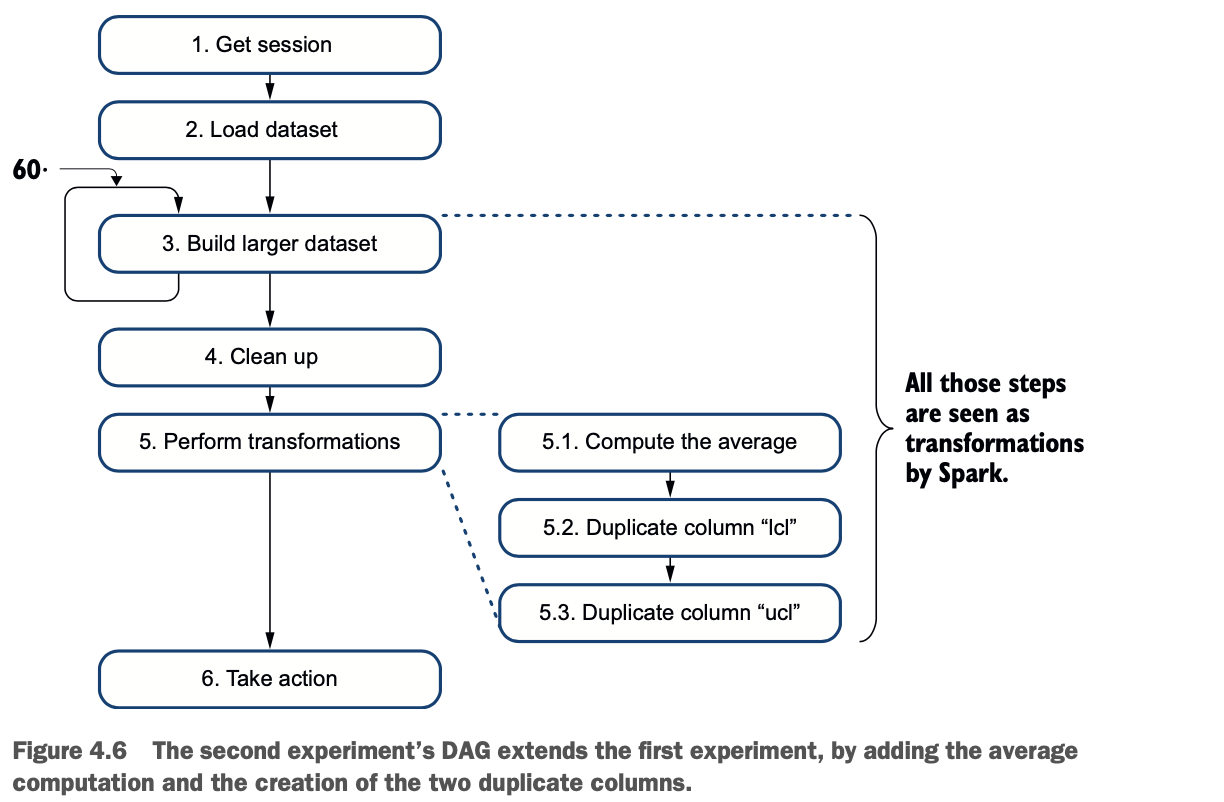
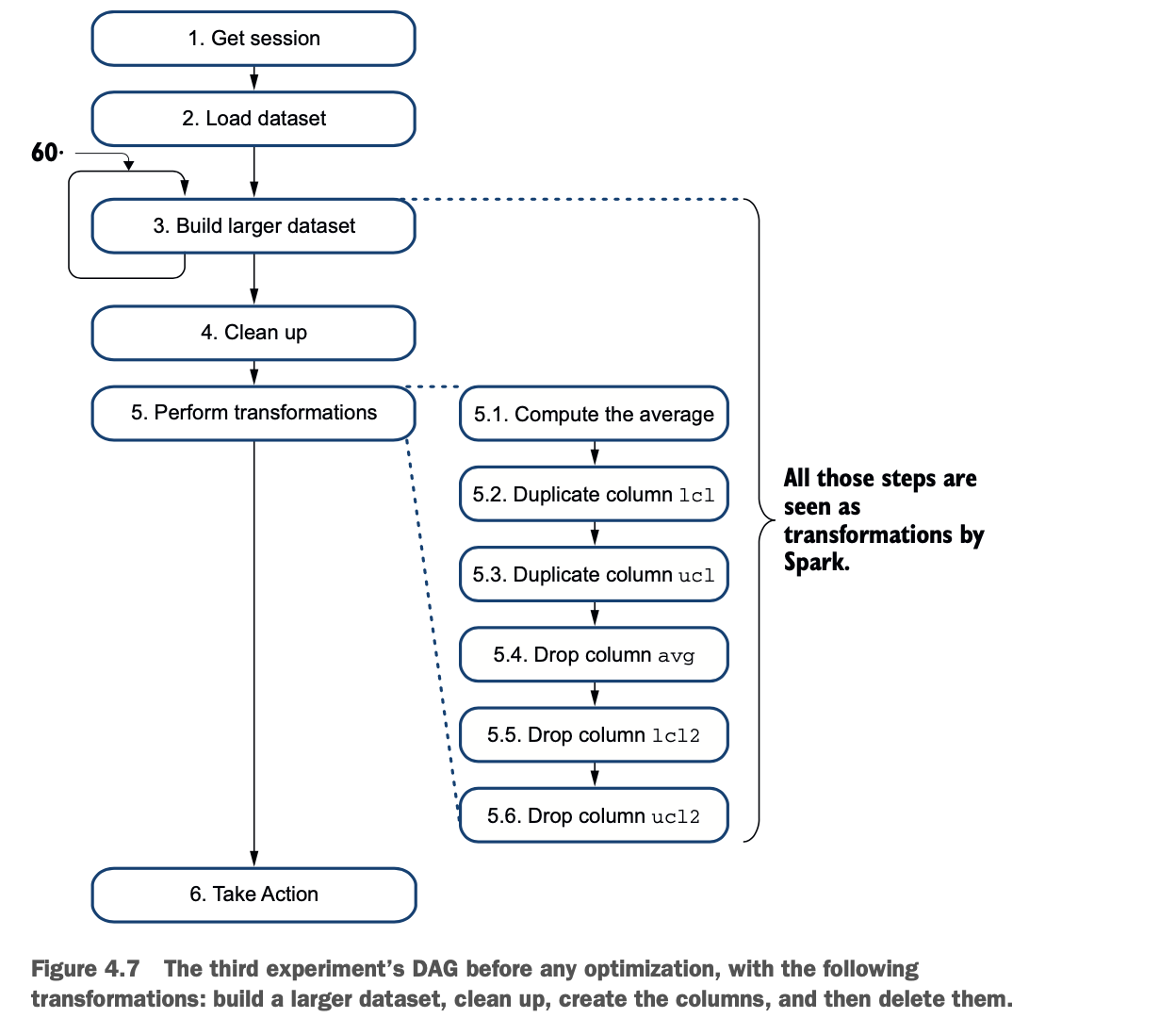 图4.7说明了在进行任何优化之前,附加变换的第三个实验。
图4.7说明了在进行任何优化之前,附加变换的第三个实验。
当你看图4.7时,你会发现第三个实验需要34秒以上的时间来完成。这个秒数是第二个实验的持续时间,在这个实验中,完成的变换较少。那么,为什么执行起来只需要25秒呢?Spark 嵌入了一个优化器,叫做 Catalyst。在执行动作之前,Catalyst会查看DAG,并做出一个更好的DAG。图4.8显示了Catalyst的过程。
Catalyst仍然会构建更大的数据集(通过union())并执行清理,但它会优化其他的变换。
* 计算平均数的过程会因为丢弃列而被取消。
* 复制lcl和ucl列,然后丢弃重复的列就会取消操作。
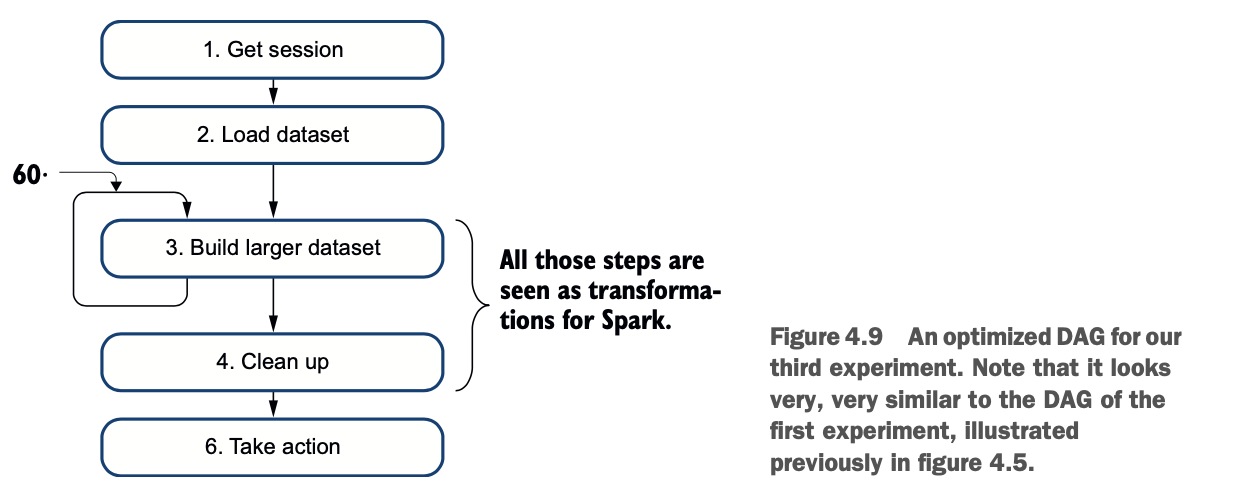
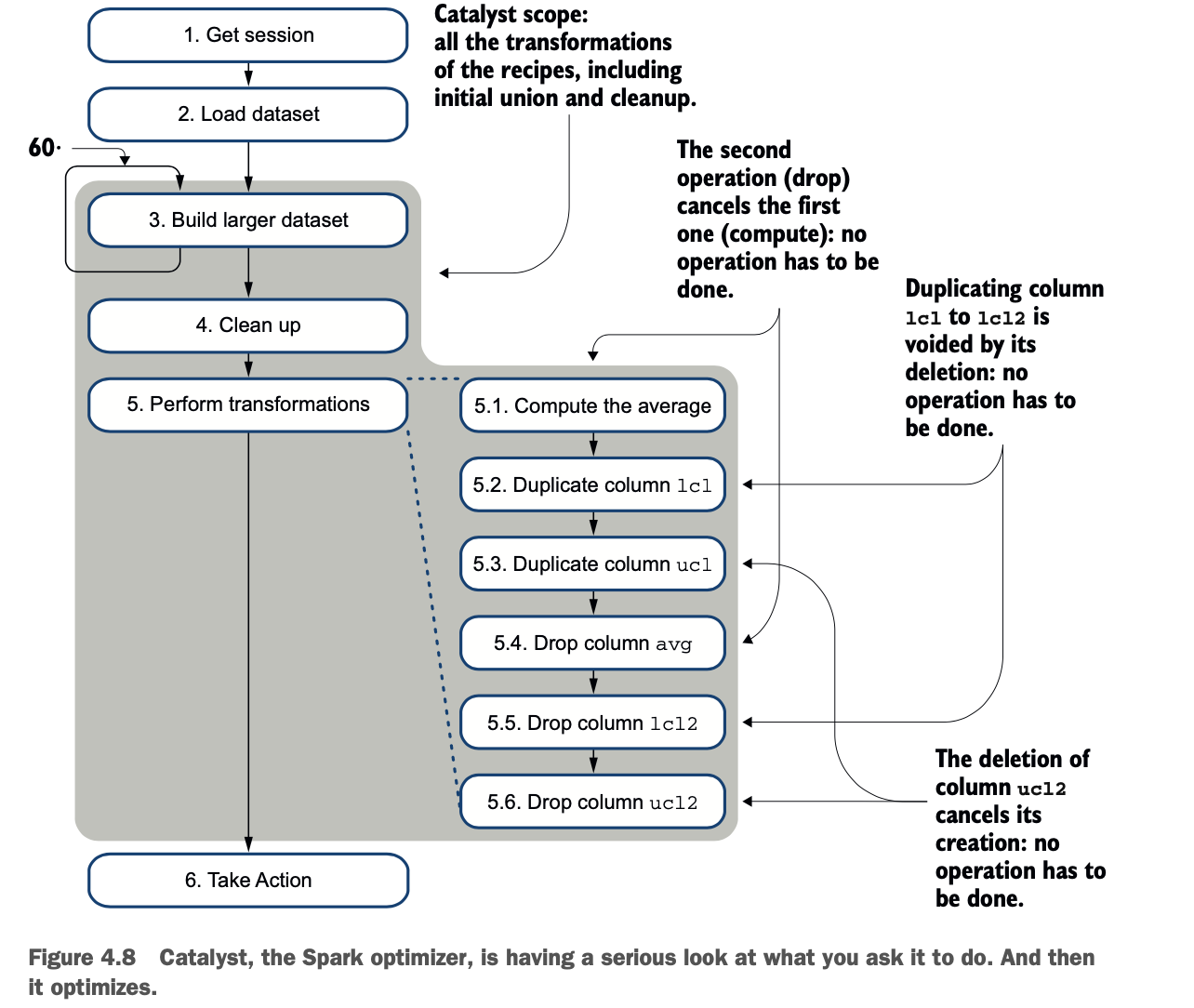 经过优化处理后,DAG得到简化,如图4.9所示。
经过优化处理后,DAG得到简化,如图4.9所示。
 希望你能了解到Catalyst在优化方面的作用。为了好玩,让我们把它与使用JDBC的标准应用程序进行比较,后者会使用数据库进行同样的操作。
希望你能了解到Catalyst在优化方面的作用。为了好玩,让我们把它与使用JDBC的标准应用程序进行比较,后者会使用数据库进行同样的操作。
与RDBMS和传统应用相比
在前面的章节中,你读到了变换(配方的一个步骤)和动作(启动作业的触发器)之间的区别。您还阅读了Spark如何构建和优化DAG,DAG代表了配方,或操作您的数据的过程。
在本节中,您将比较Spark的过程和传统应用程序的过程。您将简要回顾上一节中详细介绍的应用程序的背景。然后,你将比较传统的应用程序和Spark应用程序,并得出一些结论。
利用青少年出生率数据集开展工作
设置你的应用背景是很重要的:你正在使用一个数据集,其中包含美国每个县和州的平均青少年出生率,按年计算。它来自于NCHS。表4.4描述了数据集的结构(与表4.2相同)。
 在上一节中,您运行了三个增量实验。然而,在本节中,你将把你的方法限制在第三个实验上,它包括以下步骤。
在上一节中,您运行了三个增量实验。然而,在本节中,你将把你的方法限制在第三个实验上,它包括以下步骤。
1 获取一个Spark会话
2 加载一个初始数据集。
3 构建一个更大的数据集。
4 清理:将置信度下限列重命名为lcl,置信度上限列重命名为ucl。
5 在新列中计算平均值。
6 复制lcl列。
7 复制ucl列。
8 丢弃这三列。
分析传统应用和Spark应用的区别
现在你有了上下文,你可以分析一下传统应用和Spark应用的路径。对于传统应用,你可以假设原始数据已经在数据库表中,不需要创建更大的数据集。
图4.10比较了这两个过程,表4.5详细介绍了每个步骤。
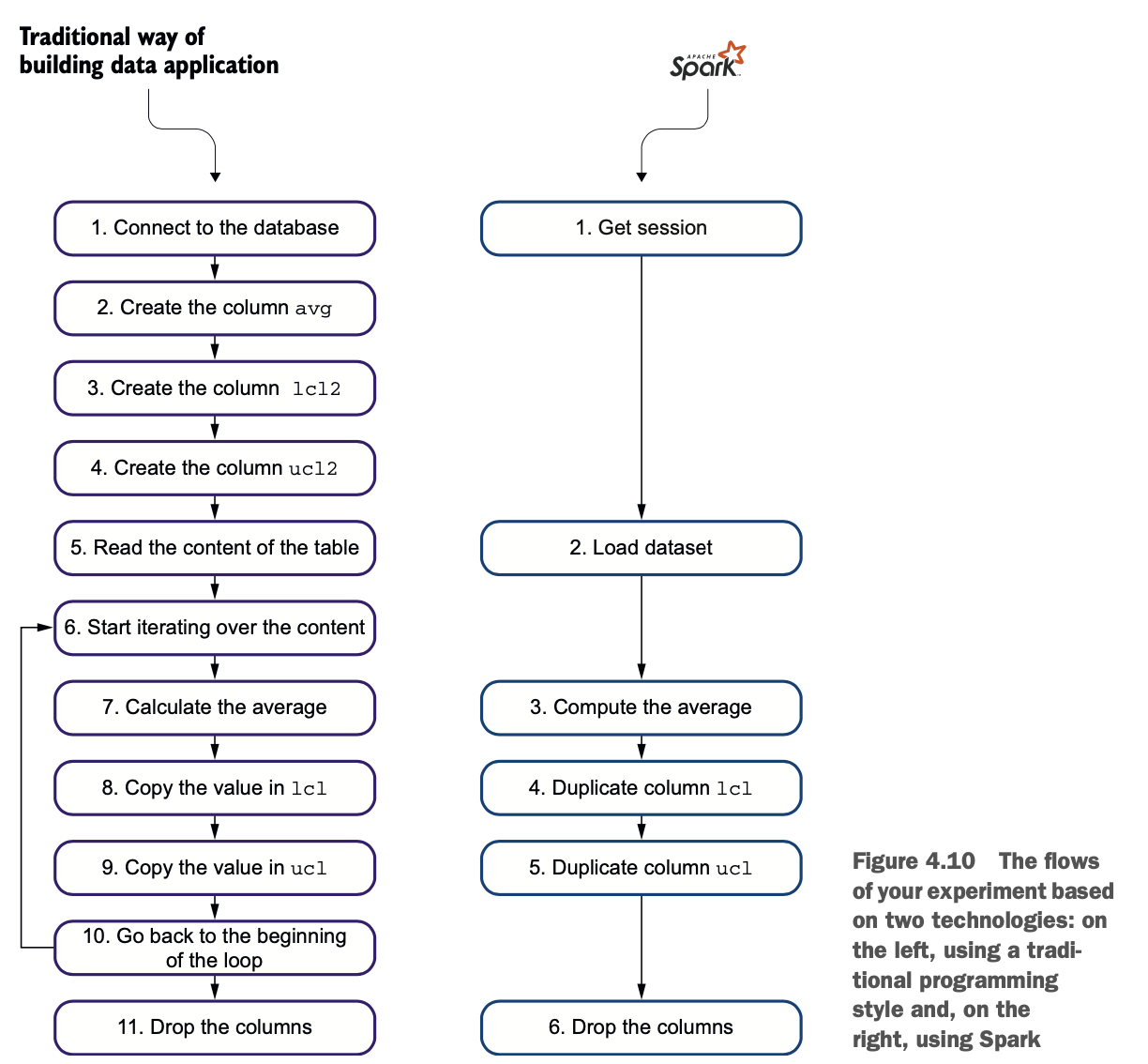 表4.5重用了图4.10的流程,但描述了每一步,并解释了传统应用和Spark应用的区别。
表4.5重用了图4.10的流程,但描述了每一步,并解释了传统应用和Spark应用的区别。
 根据这个对比,可以看出Spark的懒惰方式可以节省处理时间。
根据这个对比,可以看出Spark的懒惰方式可以节省处理时间。
Spark对于以数据为中心的应用来说是惊人的
在前面的章节中,你看了一个真实的变换和动作的例子,然后你钻研了Spark对这种机制的设想及其作为DAG的实现。最后,你比较了传统的构建以数据为中心的应用程序的方式和Spark让你实现这些应用程序的方式。本节总结了Spark构建以数据为中心的应用的方式。
我必须承认,你在本章实验中构建的应用并没有太大意义:你做了一些事情,然后你删除了你刚刚做的事情。然而,在大数据和分析中,这些操作经常发生。如果你还不是大数据大师(同意,这只是第4章),你可以想到用Excel或任何其他电子表格建立公式:有时(经常!)你需要使用一个单元格作为透视点。大数据转换也是类似的。你可以把这种机制比作一个变量或一个变量列表(列)。
你可以通过使用以下方法来转换你的数据。
* 数据框架上的内置方法,如withColumn()
* 内置的列级方法,如expr()(参见附录G中的列表)
* 低级方法,如map()、union()等(见附录一)
* 你自己使用UDF进行的转换,详见第16章。
附录I给出了两张表,分别包含变换列表和动作列表。虽然这些列表可以在网上获得,但附录中的列表增加了重要的类签名,使您可以为您的项目编写简单和可维护的Java代码。
只有当你调用一个动作时,你的转换才会被应用。
Catalyst是你的应用催化剂
在前面的章节中,你了解到Spark将你操作数据的过程变成了一个DAG。Catalyst负责优化这个图。在这一节中,你将了解更多关于Catalyst的知识。
在我的一个项目中,团队需要并开发了两个数据框架之间的连接,结果第二个数据框架是一个嵌套的文档,作为第一个数据框架的一列。当我们需要添加第三个数据框时,团队考虑开发一种方法,将三个数据框,一个主文档和两个子文档,以此类推。由于操作相当繁重,团队希望优化步骤的数量。团队没有开发一种方法来取三个数据帧作为参数,而是多次使用第一种方法:每一步都简单地添加到DAG中。最后,Catalyst擅自进行了优化,使代码变得更 "轻"、更可读(维护成本更低)。
Catalyst所做的事情类似于关系数据库世界中查询优化器对查询计划的处理。让我们仔细看看Catalyst的计划。
要访问计划,你可以使用数据框架的explain()方法来显示它,如下面的列表。我添加了换行符,以使输出更加可读。

 清单4.3显示了产生这种输出的代码。这段代码与第二个实验类似。
清单4.3显示了产生这种输出的代码。这段代码与第二个实验类似。
* 加载数据集。
* 联合它(这里只有一次)。
* 重新命名列。
* 添加三列:平均数和两个重复的列。
 其结果对调试你的应用程序很有用。
其结果对调试你的应用程序很有用。
如果你对Catalyst如何工作的细节感兴趣,Matei Zaharia和其他的人都可以在这里找到。
Spark工程师发表了《Spark SQL: Spark中的关系数据处理》,这篇论文可以在http://mng.bz/MOA8。另一篇关于DAG及其表示的有趣论文 "Understanding your Apache Spark Application Through Visualization "来自Andrew Or,你可以在http://mng.bz/adYX。虽然最初的设计来自Databricks,但对于Spark v2.2,IBM将其数据库引擎中的查询优化技术贡献给了Spark代码库。如果你有兴趣在Catalyst中添加自己的规则,可以查看Sunitha Kambhampati写的 "Learn the Extension Points in Apache Spark and Extend the Spark Catalyst Optimizer",网址是http://mng.bz/gVjG,其中有Scala的例子。
概要
* Spark是高效的懒惰:它将以定向无环图(DAG)的形式建立变换列表,并使用Spark的内置优化器Catalyst进行优化。
* 当你在一个数据框架上应用一个变换时,数据不会被修改。
* 当你在一个数据框架上应用一个动作时,所有的变换都会被执行,如果需要的话,数据会被修改。
* 在Spark中,模式的修改是一个自然的操作。你可以创建列作为占位符,并对其执行操作。
* Spark在列级工作,不需要对数据进行迭代。
* 可以使用内置的函数进行转换(见附录G)。低级函数(附录I)、数据框方法和UDF(见第16章)。
* 你可以使用数据框的explain()方法打印查询计划。 这对调试很有用--而且非常啰嗦!