Embedding概述
如果我们要用一句话来描述这个特性,我们会说OpenAI的文本嵌入度测量了两个文本字符串彼此之间的相似程度。
嵌入通常用于诸如查找与搜索查询最相关的结果、基于相似性将文本字符串分组在一起、推荐具有相似文本字符串的项目、查找与其他文本字符串非常不同的文本字符串、分析不同文本字符串之间的差异以及基于它们最相似的内容对文本字符串进行标记等任务。
从实际角度看,嵌入是一种将现实世界的对象和关系表示为矢量(数字列表)的方式。相同的矢量空间用于测量两个事物的相似程度。
用途
OpenAI的文本嵌入度测量了文本字符串的相关性,并可用于各种用途。
以下是一些用例:
自然语言处理(NLP)任务,如情感分析、语义相似性和情感分类。
为机器学习模型生成嵌入式特征,如关键字匹配、文档分类和主题建模。
生成文本的语言无关表示,允许跨语言比较文本字符串。
提高基于文本的搜索引擎和自然语言理解系统的准确性。
通过将用户的文本输入与各种文本字符串进行比较来创建个性化的推荐。
我们可以总结用例如下:
搜索:根据查询字符串的相关性对结果进行排名
聚类:将文本字符串根据相似性分组
推荐:推荐具有相关文本字符串的项目
异常检测:识别与其他文本关联性较小的异常值
多样性测量:分析相似性分布
分类:根据它们最相似的标签对文本字符串进行分类
以下是使用嵌入的一些实际方法(不一定是OpenAI的):
特斯拉
处理非结构化数据可能有些棘手 - 原始文本、图片和视频不总是容易从头开始创建模型。这通常是因为由于隐私约束而难以获取原始数据,而且需要大量的计算能力、大数据集和时间才能创建良好的模型。
嵌入是一种将信息从一个上下文(例如来自汽车的图像)转移到另一个上下文(例如游戏)的方式。这被称为迁移学习,它帮助我们在不需要大量现实世界数据的情况下训练模型。
特斯拉正在其自动驾驶汽车中使用这种技术。
Kalendar AI
Kalendar AI是一款销售外联产品,它使用嵌入来以自动化的方式从包含340百万个配置文件的数据集中匹配合适的销售话术。
自动化依赖于客户配置文件和销售话术的嵌入之间的相似性,以排名最合适的匹配项。根据OpenAI的说法,与其以前的方法相比,这降低了不必要的定位40-56%。
Notion
Notion是一种在线工作空间工具,通过利用OpenAI的嵌入功能提高了其搜索功能。在这种情况下,搜索超越了工具当前正在使用的简单关键字匹配系统。
这一新功能使概念能够更好地理解其平台中存储的内容的结构、上下文和含义,从而使用户能够执行更精确的搜索并更快地找到文档。
DALL·E 2
DALL·E 2是一个将文本标签转化为图像的系统。
它通过使用称为Prior和Decoder的两个模型来工作。Prior接受文本标签并创建CLIP22图像嵌入,而Decoder接受CLIP图像嵌入并生成一个学习过的图像。然后将图像从64x64放大到1024x1024。
Requirements
要使用嵌入,您应该使用以下命令安装datalib:
pip install datalib在本指南的另一个级别上,我们还需要Matplotlib和其他库:
pip install matplotlib plotly scipy scikit-learn确保您将其安装在正确的虚拟开发环境中。这个包还会安装pandas和NumPy等工具。
这些库在AI和数据科学中是最常用的一些库。
pandas是一个快速、强大、灵活且易于使用的开源数据分析和操作工具,构建在Python之上。
NumPy是另一个Python库,支持大型、多维数组和矩阵,以及大量高级数学函数来操作这些数组。
Matplotlib是Python编程语言和其数值数学扩展NumPy的绘图库。
plotly.py是一种交互式、开源的基于浏览器的Python图形库。
SciPy是用于科学计算和技术计算的免费开源Python库。
理解文本Embedding
让我们从这个例子开始:
import os
import openai
def init_api():
with open(".env") as env:
for line in env:
key, value = line.strip().split("=")
os.environ[key] = value
openai.api_key = os.environ.get("API_KEY")
openai.organization = os.environ.get("ORG_ID")
init_api()
response=openai.Embedding.create( model="text-embedding-ada-002", input="I am a programmer",)
print(response)和往常一样,我们导入了openai,进行了身份验证,并调用了一个Endpoint。然而,这一次我们使用的是“Ada”,这是OpenAI为embedding提供的唯一最佳模型。OpenAI团队建议几乎所有用例都使用text-embedding-ada-002,因为他们将其描述为“更好、更便宜和更简单”的模型。
输出应该很长,应该看起来像这样:
{
"data": [ {
"embedding": [
-0.0169205479323864,
-0.019740639254450798,
-0.011300412937998772,
-0.016452759504318237,
[..]
0.003966170828789473,
-0.011714739724993706
],
"index": 0,
"object": "embedding"
} ],
"model": "text-embedding-ada-002-v2",
"object": "list",
"usage": {
"prompt_tokens": 4,
"total_tokens": 4
}
}我们可以直接访问Embedding,如下所示:
print(response["data"][0]["embedding"])我们编写的程序会打印一个浮点数列表,如0.010284645482897758和0.013211660087108612。
这些浮点数表示由OpenAI“text-embedding-ada-002”模型生成的输入文本“I am a programmer”的embedding。嵌入是输入文本的高维表示,捕捉了其含义。这有时被称为矢量表示或简单的嵌入矢量。
嵌入是一种使用大量值来表示对象(例如文本)的方式。每个值代表对象含义的特定方面以及该特定对象的该方面的强度。对于文本,这些方面可以表示文本的主题、情感或其他语义特征。
换句话说,您需要在这里理解的是,由嵌入端点生成的矢量表示是一种以机器学习模型和算法可以理解的格式表示数据的方式。这是一种将给定的输入转化为这些模型和算法可用的形式的方式。
我们将看到如何在不同的用例中使用它。
用于多个输入的Embedding
在上一个示例中,我们使用了:
input="Iamaprogrammer",可以使用多个输入,方法如下:
import os
import openai
def init_api():
with open(".env") as env:
for line in env:
key, value = line.strip().split("=")
os.environ[key] = value
openai.api_key = os.environ.get("API_KEY")
openai.organization = os.environ.get("ORG_ID")
init_api()
response=openai.Embedding.create( model="text-embedding-ada-002",input=["I am a programmer", "I am a writer"],)
for data in response["data"]:
print(data["embedding"])重要的是要注意,每个输入的标记数不能超过8192。
语义搜索
在本指南的这一部分,我们将使用OpenAI嵌入来实现语义搜索。这是一个基本示例,但我们将进行更高级的示例。
让我们从身份验证开始:
import openai
import os
import pandas as pd
import numpy as np
def init_api():
with open(".env") as env:
for line in env:
key, value = line.strip().split("=")
os.environ[key] = value
openai.api_key = os.environ.get("API_KEY")
openai.organization = os.environ.get("ORG_ID")
init_api()接下来,我们将创建一个名为“words.csv”的文件。CSV文件包含一个名为“text”的单列和一列随机单词列表:
text
apple
banana
cherry
dog
cat
house
car
tree
phone
computer
television
book
music
food
water
sky
air
sun
moon
star
ocean
desk
bed
sofa
lamp
carpet
window
door
floor
ceiling
wall
clock
watch
jewelry
ring
necklace
bracelet
earring
wallet
key
photoPandas在处理包括CSV文件中的数据在内的数据操作方面是一个非常强大的工具。这完全适用于我们的用例。让我们使用pandas来读取文件并创建一个pandas数据帧。
df=pd.read_csv('words.csv')
Dataframe是最常用的pandas对象。
Pandas的官方文档将数据帧描述为具有不同类型列的2维标记数据结构。您可以将其视为类似于电子表格或SQL表的东西,或者将其视为一组Series对象的字典。
如果您打印df,您将看到以下输出:
text
0 apple
1 banana
2 cherry
3 dog
4 cat
5 house
6 car
7 tree
8 phone
9 computer
10 television
11 book
12 music
13 food
14 water
15 sky
16 air
17 sun
18 moon
19 star
20 ocean
21 desk
22 bed
23 sofa
...
37 earring
38 wallet
39 key
40 photo接下来,我们将获取数据框中每个单词的Embedding。为此,我们将不使用openai.Embedding.create()函数,而是使用get_embedding。两者将执行相同的操作,但前者将返回包含嵌入和其他数据的JSON,而后者将返回嵌入的列表。后者在数据框中更实用。
这个函数的工作方式如下:
get_embedding("Hello", engine='text-embedding-ada-002')
#将返回[-0.02499537356197834,-0.019351257011294365,..等等]我们还将使用Dataframe对象上拥有的apply函数。这个函数(apply)将函数应用于Dataframe的一个轴。
#导入用于获取embedding的函数
from openai.embeddings_utils import get_embedding
#获取数据框中每个单词的embedding
df['embedding'] = df['text'].apply(lambda x: get_embedding(x, engine='text-embedding-ada-002'))现在,我们有一个具有两个轴的数据框,一个是文本,另一个是嵌入。最后一个包含了第一个轴上每个单词的嵌入。
让我们将数据框保存到另一个CSV文件中:
df.to_csv('embeddings.csv')新文件应该如下截图所示:
 它包含3列:id、text和embeddings。
它包含3列:id、text和embeddings。
现在让我们读取新文件并将最后一列转换为numpy数组。为什么?
因为在下一步中,我们将使用cosine_similarity函数。这个函数期望一个numpy数组,而默认情况下它是一个字符串。
但为什么不只是使用常规的Python数组/列表,而要使用numpy数组呢?
实际上,在数值计算中广泛使用numpy数组。常规的列表模块在这种计算中没有提供任何帮助。此外,数组消耗更少的内存并且更快。这是因为数组是一组存储在连续内存位置中的同质数据类型,而Python中的列表是一组存储在非连续内存位置中的异质数据类型。
回到我们的代码,让我们将最后一列转换为numpy数组:
df['embedding'] = df['embedding'].apply(eval).apply(np.array)现在,我们将要求用户输入,读取它,并使用余弦相似度执行语义搜索:
#从用户获取搜索词
user_search = input('输入搜索词:')
#获取搜索词的嵌入
user_search_embedding = get_embedding(user_search, engine='text-embedding-ada-002')
#导入计算余弦相似度的函数
from openai.embeddings_utils import cosine_similarity
#计算搜索词的嵌入与数据框中每个单词的余弦相似度
df['similarity'] = df['embedding'].apply(lambda x: cosine_similarity(x, user_search_embedding))让我们看看上面代码中的最后3个操作分别做了什么:
1) user_search_embedding = get_embedding(user_search, engine='text-embedding-ada-002') 这行代码使用get_embedding函数获取用户指定的搜索词user_search的embedding。
engine参数设置为'text-embedding-ada-002',指定要使用的OpenAI文本嵌入模型。
2) from openai.embeddings_utils import cosine_similarity
这行代码从openai.embeddings_utils模块中导入cosine_similarity函数。cosine_similarity函数计算两个embedding之间的余弦相似度。
3) df['similarity'] = df['embedding'].apply(lambda x: cosine_similarity(x, user_search_embedding)) 这行代码在数据框中创建一个名为'similarity'的新列,并使用apply方法和lambda函数计算用户搜索词的嵌入与数据框中每个单词的嵌入之间的余弦相似度。
余弦相似度对每对嵌入之间的相似度进行计算,并将其存储在新的'similarity'列中。这就是所有东西的综合:
import openai
import os
import pandas as pd
import numpy as np
from openai.embeddings_utils import get_embedding, cosine_similarity
def init_api():
with open(".env") as env:
for line in env:
key, value = line.strip().split("=")
os.environ[key] = value
openai.api_key = os.environ.get("API_KEY")
openai.organization = os.environ.get("ORG_ID")
init_api()
# 从包含名为'text'的列和单词的csv文件中读取数据框
df = pd.read_csv('words.csv')
# 获取Dataframe中每个单词的嵌入
df['embedding'] = df['text'].apply(lambda x: get_embedding(x, engine='text-embedding-ada-002'))
# 保存数据框到csv文件
df.to_csv('embeddings.csv')
# 读取csv文件
df = pd.read_csv('embeddings.csv')
# 将嵌入轴转换为numpy数组
df['embedding'] = df['embedding'].apply(eval).apply(np.array)
# 从用户获取输入搜索词
user_search = input('输入搜索词:')
# 获取搜索词的嵌入
search_term_embedding = get_embedding(user_search, engine='text-embedding-ada-002')
# 计算搜索词的嵌入与Dataframe中每个单词的余弦相似度
df['similarity'] = df['embedding'].apply(lambda x: cosine_similarity(x, search_term_embedding))
print(df)运行代码后,我输入了词汇"office",这是输出:
Unnamed: 0 text embedding \
0 0 apple [0.00777884665876627, -0.023069249466061592, -...
1 1 banana [-0.013928349129855633, -0.03294311463832855, ...
2 2 cherry [0.006536407396197319, -0.0189522635191679, -0...
3 3 dog [-0.00337603478692472, -0.017694612964987755, ...
4 4 cat [-0.007100660353899002, -0.017430506646633148,...
5 5 house [-0.007216442376375198, 0.00717067951336503, -...
6 6 car [-0.0074860816821455956, -0.02152673341333866,...
7 7 tree [-0.004628860391676426, -0.013212542049586773,...
8 8 phone [-0.0013222387060523033, -0.022854076698422432...
9 9 computer [-0.003120896639302373, -0.014261004514992237,...
10 10 television [-0.004805790726095438, -0.01992644928395748, ...
11 11 book [-0.0068267760798335075, -0.019158145412802696...
12 12 music [-0.0018868133192881942, -0.02329297550022602,...
13 13 food [0.022320540621876717, -0.026822732761502266, ...
14 14 water [0.019045095890760422, -0.012522426433861256, ...
15 15 sky [0.0049745566211640835, -0.0014098514802753925...
16 16 air [0.008967065252363682, -0.023472610861063004, ...
17 17 sun [0.024841999635100365, -0.0025255579967051744,...
18 18 moon [0.01746830902993679, -0.00917647872120142, 0....
19 19 star [0.011601175181567669, -0.009590022265911102, ...
20 20 ocean [0.0055202580988407135, 7.79720357968472e-05, ...
21 21 desk [0.012829462066292763, -0.02070934884250164, -...
22 22 bed [0.005951494909822941, 0.004073821473866701, 0...
23 23 sofa [0.011828833259642124, -0.011590897105634212, ...
...
37 0.776575
38 0.825625
39 0.812441
40 0.833105通过使用"similarity"轴,我们可以看到哪个单词在语义上与"office"相似。浮点值越高,来自"text"列的单词与其相似性越高。
像"necklace"、"bracelet"和"earring"这样的词的得分为0.77,但像"desk"这样的词的得分为0.88。
为了使结果更易读,我们可以按相似性轴对数据框进行排序:
#按相似性轴排序数据框
df = df.sort_values(by='similarity', ascending=False)
#我们还可以使用以下代码获取前10个相似性最高的单词:
df.head(10)让我们来看一下最终的代码:
import openai
import os
import pandas as pd
import numpy as np
from openai.embeddings_utils import get_embedding
from openai.embeddings_utils import cosine_similarity
def init_api():
with open(".env") as env:
for line in env:
key, value = line.strip().split("=")
os.environ[key] = value
openai.api_key = os.environ.get("API_KEY")
openai.organization = os.environ.get("ORG_ID")
init_api()
# 从包含名为'text'的列和单词的csv文件中读取数据框
df = pd.read_csv('words.csv')
# 获取数据框中每个单词的嵌入
df['embedding'] = df['text'].apply(lambda x: get_embedding(x, engine='text-embedding-ada-002'))
# 保存数据框到csv文件
df.to_csv('embeddings.csv')
# 读取csv文件
df = pd.read_csv('embeddings.csv')
# 将嵌入轴转换为numpy数组
df['embedding'] = df['embedding'].apply(eval).apply(np.array)
# 从用户获取输入搜索词
user_search = input('输入搜索词:')
# 获取搜索词的嵌入
search_term_embedding = get_embedding(user_search, engine='text-embedding-ada-002')
# 计算搜索词的嵌入与数据框中每个单词的余弦相似度
df['similarity'] = df['embedding'].apply(lambda x: cosine_similarity(x, search_term_embedding))
# 按相似性轴排序数据框
df = df.sort_values(by='similarity', ascending=False)
# 打印前10个结果
print(df.head(10))以下是前10个单词的相似性结果:
您可以尝试运行代码,并输入其他单词(如"dog"、"hat"、"fashion"、"phone"、"philosophy"等)并查看相应的结果。
余弦相似性
两个单词之间的相似性是通过余弦相似性来进行的。为了使用它,无需理解数学细节,但如果您想深入了解这个主题,可以阅读本指南的这一部分。否则,跳过它不会改变您如何使用OpenAI API构建智能应用程序的理解。
余弦相似性是一种衡量两个向量相似程度的方法。它关注两个向量(线)之间的夹角并进行比较。余弦相似性是向量之间夹角的余弦值。结果是一个介于-1和1之间的数字。如果向量相同,则结果为1。如果向量完全不同,则结果为-1。如果向量处于90度角,则结果为0。在数学术语中,这是等式:
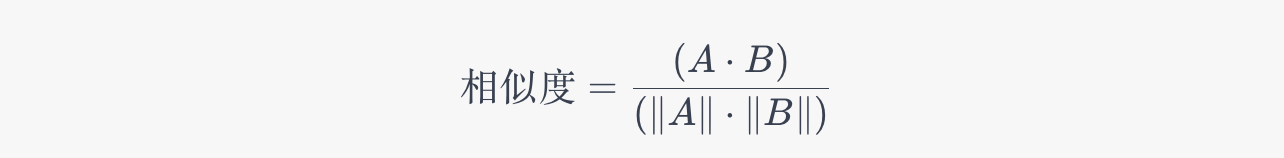
A和B是向量
A.B是将两组数字相乘的一种方法。它通过取一组中的每个数字并将其与另一组中的相同数字相乘,然后将所有这些乘积相加来完成。
||A||是向量A的长度。它通过取向量A的每个元素的平方的总和的平方根来计算。
让我们考虑向量A = [2,3,5,2,6,7,9,2,3,4]和向量B = [3,6,3,1,0,9,2,3,4,5]。这是如何使用Python获取它们之间的余弦相似性的:
# 导入numpy和numpy.linalg中的norm
import numpy as np
from numpy.linalg import norm
# 定义两个向量
A = np.array([2, 3, 5, 2, 6, 7, 9, 2, 3, 4])
B = np.array([3, 6, 3, 1, 0, 9, 2, 3, 4, 5])
# 打印向量
print("向量A:{}".format(A))
print("向量B:{}".format(B))
# 计算余弦相似性
cosine = np.dot(A, B) / (norm(A) * norm(B))
# 打印余弦相似性
print("向量A和B的余弦相似性:{}".format(cosine))我们还可以使用Python的Scipy编写相同的程序:
# 导入numpy
import numpy as np
from scipy import spatial
# 定义两个向量
A = np.array([2, 3, 5, 2, 6, 7, 9, 2, 3, 4])
B = np.array([3, 6, 3, 1, 0, 9, 2, 3, 4, 5])
# 打印向量
print("向量A:{}".format(A))
print("向量B:{}".format(B))
# 计算余弦相似性
cosine = 1 - spatial.distance.cosine(A, B)
# 打印余弦相似性
print("向量A和B的余弦相似性:{}".format(cosine))或者使用Scikit-Learn:
# 导入numpy
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 定义两个向量
A = np.array([2, 3, 5, 2, 6, 7, 9, 2, 3, 4])
B = np.array([3, 6, 3, 1, 0, 9, 2, 3, 4, 5])
# 打印向量
print("向量A:{}".format(A))
print("向量B:{}".format(B))
# 计算余弦相似性
cosine = cosine_similarity([A], [B])
# 打印余弦相似性
print("余弦相似性:{}".format(cosine[0][0]))高级Embedding示例
预测您喜欢的咖啡
我们在本部分的目标是根据用户的输入向其推荐最适合的咖啡混合物。例如,用户输入“Ethiopia Dumerso”,程序会发现“Ethiopia Dumerso”、“Ethiopia Guji Natural Dasaya”和“Organic Dulce de Guatemala”是与其选择最接近的混合物,输出将包含这三种混合物。
我们需要一个数据集,可以在Kaggle上下载。前往Kaggle并下载名为simplified_coffee.csv的数据集。(您需要创建一个帐户。)数据集有1267行(混合物)和9个特征:
name(咖啡名称)
roaster(烘焙师名称)
roast(烘焙类型)
loc_country(烘焙师所在国家)
origin(豆子的产地)
100g_USD(每100克的价格,以美元计价)
rating(100分制的评分)
review_date(评论日期)
review(评论文本)
在这个数据集中,我们感兴趣的是用户的评论。这些评论是从www.coffeereview.com上抓取的。
当用户输入咖啡的名称时,我们将使用OpenAI Embeddings API获取该咖啡的评论文本的embedding。然后,我们将计算输入咖啡评论与数据集中所有其他评论之间的余弦相似性。具有最高余弦相似性分数的评论将与输入咖啡的评论最相似。然后,我们将向用户打印最相似的咖啡的名称。
让我们一步步开始。
激活您的虚拟开发环境并安装nltk:
pip install nltk自然语言工具包,更常用的是NLTK,是用于英语的符号和统计自然语言处理的一套库和程序,用Python编写。在接下来的步骤中,您将了解我们如何使用它。
现在,使用您的终端,输入python进入Python解释器。然后,输入以下命令:
import nltk
nltk.download('stopwords')
nltk.download('punkt')NLTK附带许多语料库、玩具语法、训练模型等等。上述的stopwords和punkt是我们这个演示中唯一需要的。如果您想下载所有语料库,可以使用nltk.download('all')。您可以在这里找到完整的[语料库列表](https://www.nltk.org/nltk_data/)。
我们将创建3个函数:
import os
import pandas as pd
import numpy as np
import nltk
import openai
from openai.embeddings_utils import get_embedding, cosine_similarity
def init_api():
with open(".env") as env:
for line in env:
key, value = line.strip().split("=")
os.environ[key] = value
openai.api_key = os.environ.get("API_KEY")
openai.organization = os.environ.get("ORG_ID")
def download_nltk_data():
try:
nltk.data.find('tokenizers/punkt')
except LookupError:
nltk.download('punkt')
try:
nltk.data.find('corpora/stopwords')
except LookupError:
nltk.download('stopwords')
def preprocess_review(review):
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
stopwords = set(stopwords.words('english'))
stemmer = PorterStemmer()
tokens = nltk.word_tokenize(review.lower())
tokens = [token for token in tokens if token not in stopwords]
tokens = [stemmer.stem(token) for token in tokens]
return ' '.join(tokens)init_api函数从环境变量文件(.env)中读取API密钥和组织ID,然后初始化OpenAI API。
download_nltk_data函数将下载NLTK所需的数据(停用词和标点符号),如果它们尚未被下载的话。
preprocess_review函数将评论进行预处理,包括转为小写、分词、去除停用词和词干提取。
接下来,我们将初始化API并下载NLTK数据:
init_api()
download_nltk_data()然后,我们将读取用户输入的咖啡名称:
input_coffee_name = input("Enter a coffee name:")接下来,我们将加载CSV文件到Pandas DataFrame中,注意这里我们只读取前50行数据,您可以根据需要更改代码以加载整个CSV数据集:
df = pd.read_csv('simplified_coffee.csv', nrows=50)然后,我们将对所有评论文本进行预处理:
df['preprocessed_review'] = df['review'].apply(preprocess_review)接下来,我们需要为每个评论获取嵌入:
review_embeddings = []
for review in df['preprocessed_review']:
review_embeddings.append(get_embedding(review, engine='text-embedding-ada-002'))然后,我们将获取输入咖啡名称的索引,如果咖啡名称不在我们的数据库中,程序将退出:
try:
input_coffee_index = df[df['name'] == input_coffee_name].index[0]
except:
print("Sorry, we don't have that coffee in our database. Please try again.")
exit()接下来,我们将计算输入咖啡评论与所有其他评论之间的余弦相似性:
similarities = []
input_review_embedding = review_embeddings[input_coffee_index]
for review_embedding in review_embeddings:
similarity = cosine_similarity(input_review_embedding, review_embedding)
similarities.append(similarity)最后,我们将获取最相似的评论的索引(不包括输入咖啡的评论本身):
most_similar_indices = np.argsort(similarities)[-6:-1]这段代码使用NumPy的argsort()函数获取与输入咖啡评论最相似的前5个评论的索引。我们排除了输入咖啡的评论本身。这样,我们将得到与输入咖啡评论最相似的5个评论的索引,按相似性降序排列。
这个操作的目的是排除用户已经尝试过的相同咖啡的评论,因为推荐相同的咖啡不太有帮助。使用[-6:-1],我们排除了切片的第一个元素,即输入咖啡的评论。同时也排除了自身与自身的相似性。
另外,可能会有一个问题:为什么不使用[-5:]呢?
如果我们使用np.argsort(similarities)[-5:]而不是np.argsort(similarities)[-6:-1],我们将获得最相似的5个评论,包括输入咖啡的评论本身。排除输入咖啡的评论是因为推荐用户已经尝试过的相同咖啡不太有帮助。通过使用[-6:-1],我们排除了切片的第一个元素,即输入咖啡的评论。
还有一个问题可能是,为什么在相似性数组中会包含自身的评论?
在创建嵌入时,我们使用get_embedding()函数为每个评论创建了嵌入,因此输入咖啡的评论也包含在review_embeddings数组中。
接下来,我们将获取最相似咖啡的名称:
#获取最相似咖啡的名称
similar_coffee_names = df.iloc[most_similar_indices]['name'].tolist()df.iloc[most_similar_indices]['name'].tolist() 使用Pandas的iloc[]函数来获取最相似咖啡的名称。这里有一个解释:
df.iloc[most_similar_indices] 使用iloc[]来获取与最相似评论对应的DataFrame行。例如,如果最相似的索引是[3, 4, 0, 2],df.iloc[most_similar_indices]将返回与第4、5、1和3个最相似评论对应的DataFrame行。
然后,我们使用['name']来获取这些行的名称列。最后,我们使用tolist()将列转换为列表。这给我们提供了最相似咖啡的名称列表。
最后,我们将打印结果:
#打印结果
print("与{}最相似的咖啡是:".format(input_coffee_name))
for coffee_name in similar_coffee_names:
print(coffee_name)这是最终的代码:
import os
import pandas as pd
import numpy as np
import nltk
import openai
from openai.embeddings_utils import get_embedding
from openai.embeddings_utils import cosine_similarity
def init_api():
with open(".env") as env:
for line in env:
key, value = line.strip().split("=")
os.environ[key] = value
openai.api_key = os.environ.get("API_KEY")
openai.organization = os.environ.get("ORG_ID")
def download_nltk_data():
try:
nltk.data.find('tokenizers/punkt')
except LookupError:
nltk.download('punkt')
try:
nltk.data.find('corpora/stopwords')
except LookupError:
nltk.download('stopwords')
def preprocess_review(review):
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
stopwords = set(stopwords.words('english'))
stemmer = PorterStemmer()
tokens = nltk.word_tokenize(review.lower())
tokens = [token for token in tokens if token not in stopwords]
tokens = [stemmer.stem(token) for token in tokens]
return ' '.join(tokens)
init_api()
download_nltk_data()
# 读取用户输入
input_coffee_name = input("请输入咖啡名称:")
# 将CSV文件加载到Pandas DataFrame中(仅加载前50行以加快演示速度并避免过多的API调用)
df = pd.read_csv('simplified_coffee.csv', nrows=50)
# 预处理评论文本:转换为小写,分词,去除停用词,并词干处理
df['preprocessed_review'] = df['review'].apply(preprocess_review)
# 获取每个评论的embedding
review_embeddings = []
for review in df['preprocessed_review']:
review_embeddings.append(get_embedding(review, engine='text-embedding-ada-002'))
# 获取输入咖啡名称的索引
try:
input_coffee_index = df[df['name'] == input_coffee_name].index[0]
except:
print("抱歉,我们的数据库中没有该咖啡。请重试。")
exit()
# 计算输入咖啡的评论与所有其他评论之间的余弦相似度
similarities = []
input_review_embedding = review_embeddings[input_coffee_index]
for review_embedding in review_embeddings:
similarity = cosine_similarity(input_review_embedding, review_embedding)
similarities.append(similarity)
# 获取最相似评论的索引(不包括输入咖啡的评论本身)
most_similar_indices = np.argsort(similarities)[-6:-1]
# 为什么是-1?因为最后一个是输入咖啡本身
# 获取最相似咖啡的名称
similar_coffee_names = df.iloc[most_similar_indices]['name'].tolist()
# 打印结果
print("与{}最相似的咖啡是:".format(input_coffee_name))
for coffee_name in similar_coffee_names:
print(coffee_name)这段代码的功能是根据输入的咖啡名称,找到与之最相似的咖啡名称并打印出来。
进行“模糊”搜索
代码的一个潜在问题是用户必须输入数据集中存在的咖啡的确切名称。一些示例包括:“Estate Medium Roast”,“Gedeb Ethiopia”等。在现实生活中,这不太可能发生。用户可能会错过一个字符或一个单词,输入错误的名称或使用不同的大小写,这将导致搜索退出,并显示消息:“抱歉,我们的数据库中没有这种咖啡。请重试。”
一个解决方法是执行更灵活的查找。例如,我们可以搜索包含输入咖啡名称的名称,同时忽略大小写:
#获取输入咖啡名称的索引
try:
# 在数据框中搜索看起来像输入咖啡名称的咖啡名称
input_coffee_index = df[df['name'].str.contains(input_coffee_name, case=False)].index[0]
print("找到一个看起来像{}的咖啡名称。正在使用该名称。".format(df.iloc[input_coffee_index]['name']))
except:
print("抱歉,我们的数据库中没有这个咖啡名称。请重试。")
exit()如果我们使用上面的代码并执行它,对于某些关键词,我们将获得多个结果:
#获取输入咖啡名称的索引
try:
#在数据框中搜索所有看起来像输入咖啡名称的咖啡名称
input_coffee_indexes = df[df['name'].str.contains(input_coffee_name, case=False)].index
except:
print("抱歉,我们找不到任何带有该名称的咖啡。")
exit()通过在具有关键词“Ethiopia”的数据集上运行此操作,我们将获得约390个结果。因此,我们应该处理这些结果的每个描述的Embedding,并将每个描述与其他咖啡描述的Embedding进行比较。这可能会耗费很长时间,我们肯定会获得数十个结果。在这种情况下,最好从所有结果中选择3个名称,但我们应该如何选择它们?应该只随机选择一些结果吗?
更好的解决方法是使用模糊搜索技术。例如,我们可以使用Python中的Levenshtein距离技术。简单来说,两个单词之间的Levenshtein距离是将一个单词转换为另一个单词所需的最小单字符编辑(插入、删除或替换)的数量。您不需要自己重新实现任何算法,因为大多数算法可以在像textdistance等库中找到。
另一个解决方法是在用户输入和咖啡名称之间运行余弦相似性搜索。
#获取输入咖啡名称的索引
try:
input_coffee_index = df[df['name'] == input_coffee_name].index[0]
except IndexError:
#获取每个名称的嵌入
print("抱歉,我们的数据库中没有这个咖啡名称。我们将尝试找到最接近的匹配。")
name_embeddings = []
for name in df['name']:
name_embeddings.append(get_embedding(name, engine='text-embedding-ada-002'))
#在输入咖啡名称上执行余弦相似性搜索
input_coffee_embedding = get_embedding(input_coffee_name, engine='text-embedding-ada-002')
_similarities = []
for name_embedding in name_embeddings:
similarities.append(cosinesimilarity(input_coffee_embedding, name_embedding))
input_coffee_index = similarities.index(max(similarities))
except:
print("抱歉,我们的数据库中没有这个咖啡名称。请重试。")
exit()
这意味着我们在同一代码中将有两次余弦相似性搜索:
搜索最接近用户输入的名称(name_embeddings)
搜索最接近用户输入的描述(review_embeddings)
我们还可以在同一代码中结合模糊搜索和余弦相似性搜索技术。
使用Embedding预测新闻类别
此示例将介绍一个零样本新闻分类器,用于预测新闻文章的类别。我们总是从以下代码片段开始:
import os
import openai
import pandas as pd
from openai.embeddings_utils import get_embedding
from openai.embeddings_utils import cosine_similarity
def init_api():
with open(".env") as env:
for line in env:
key, value = line.strip().split("=")
os.environ[key] = value
openai.api_key = os.environ.get("API_KEY")
openai.organization = os.environ.get("ORG_ID")
init_api()然后,我们将定义一个类别列表:
categories = [
'U.S. NEWS',
'COMEDY',
'PARENTING',
'WORLD NEWS',
'CULTURE & ARTS',
'TECH',
'SPORTS'
]选择这些类别并非是随意的。稍后我们将看到我们为什么做出了这个选择。
接下来,我们将编写一个函数,将句子分类为上述类别之一:
#定义一个分类句子的函数
def classify_sentence(sentence):
# 获取句子的Embedding
sentence_embedding = get_embedding(sentence, engine="text-embedding-ada-002") # 计算句子与每个类别之间的相似性分数
similarity_scores = {}
for category in categories:
category_embeddings = get_embedding(category, engine="text-embedding-ada-002")
similarity_scores[category] = cosine_similarity(sentence_embedding, category_embeddings)
# 返回具有最高相似性分数的类别
return max(similarity_scores, key=similarity_scores.get)以下是函数的每个部分的功能:
sentence_embedding = get_embedding(sentence, engine="text-embedding-ada-002"):这一行使用OpenAI的get_embedding函数来获取输入句子的Embedding。engine="text-embedding-ada-002"参数指定了用于嵌入的OpenAI模型。
category_embeddings = get_embedding(category, engine="text-embedding-ada-002"):我们在for循环中获取当前类别的嵌入。
similarity_scores[category] = cosine_similarity(sentence_embedding, category_embeddings):我们计算句子Embedding与类别Embedding之间的余弦相似性,并将结果存储在similarity_scores字典中。
return max(similarity_scores, key=similarity_scores.get):我们返回具有最高相似性分数的类别。max函数在similarity_scores字典中找到具有最大值(相似性分数)的键(类别)。
我们现在可以对一些句子进行分类:
#分类句子
sentences=[
"1 dead and 3 injured in El Paso, Texas, mall shooting",
"Director Owen Kline Calls Funny Pages His ‘Self-Critical’ Debut",
"15 spring break ideas for families that want to get away",
"The US is preparing to send more troops to the Middle East",
"Bruce Willis' 'condition has progressed' to frontotemporal dementia, his family says",
"Get an inside look at Universal’s new Super Nintendo World",
"Barcelona 2-2 Manchester United: Marcus Rashford shines but Raphinha salvages draw for hosts",
"Chicago bulls win the NBA championship",
"The new iPhone 12 is now available",
"Scientists discover a new dinosaur species",
"The new coronavirus vaccine is now available",
"The new Star Wars movie is now available",
"Amazon stock hits a new record high",
]
for sentence in sentences:
print("{:50} category is {}".format(sentence, classify_sentence(sentence)))
print()在执行上述代码后,您将看到类似于以下输出:
<Senence>
<PreditectedCategory>
<Senence>
<PreditectedCategory>
<Senence>
<PreditectedCategory>在下一个示例中,我们将继续使用相同的代码。
评估零样本分类器的准确性
看起来前面的分类器几乎完美,但有一种方法可以了解它是否真的准确,并生成准确性分数。
我们将从[Kaggle](https://www.kaggle.com/datasets/rmisra/news-category-dataset)下载此数据集并保存在data/News_Category_Dataset_v3.json下。
这个数据集包含了从2012年到2022年来自HuffPost的大约210,000条新闻标题。数据集将每篇文章的标题分类到一个类别中。
数据集中使用的类别与我们之前使用的类别相同(因此是我最初的选择):
POLITICS
WELLNESS
ENTERTAINMENT
TRAVEL
STYLE & BEAUTY
PARENTING
HEALTHY LIVING
QUEER VOICES
FOOD & DRINK
BUSINESS
COMEDY
SPORTS
BLACK VOICES
HOME & LIVING
PARENTS
我们将使用sklearn.metrics.precision_score函数来计算精度分数。
精度是tp / (tp + fp)的比率,其中tp是真正例的数量,fp是假正例的数量。精度直观上表示分类器不将负样本错误标记为正样本的能力。
让我们看看如何做到这一点。
from sklearn.metrics import precision_score
def evaluate_precision(categories):
# 加载数据集
df = pd.read_json("data/News_Category_Dataset_v3.json", lines=True).head(20)
y_true = []
y_pred = []
# 对每个句子进行分类
for _, row in df.iterrows():
true_category = row['category']
predicted_category = classify_sentence(row['headline'])
y_true.append(true_category)
y_pred.append(predicted_category)
# 如果需要,取消下面一行的注释以打印真正和假正预测
# if true_category != predicted_category:
# print("False prediction: {:50} True: {:20} Pred: {:20}".format(row['headline'], true_category, predicted_category))
# print("True prediction: {:50} True: {:20} Pred: {:20}".format(row['headline'], true_category, predicted_category))
# 计算精度分数
return precision_score(y_true, y_pred, average='micro', labels=categories)让我们看看每行的功能:
df = pd.read_json("data/News_Category_Dataset_v3.json", lines=True).head(20):这一行将News_Category_Dataset_v3.json数据集的前20条记录读入Pandas DataFrame中。lines=True参数指定文件每行包含一个JSON对象。为了更准确地计算精度,我会使用更多的记录。但是,对于这个示例,我只使用了20条记录,可以随时使用更多记录。
y_true = [] 和 y_pred = []:我们初始化空列表以存储每个句子的真实类别和预测类别。
for _, row in df.iterrows():我们遍历DataFrame中的每一行。
true_category = row['category'] 和 predicted_category = classify_sentence(row['headline']):这些行从当前行中提取真实类别,并使用classify_sentence函数来预测当前行中标题的类别。
y_true.append(true_category) 和 y_pred.append(predicted_category):我们将真实类别和预测类别添加到y_true和y_pred列表中。
return precision_score(y_true, y_pred, average='micro', labels=categories):这一行使用scikit的precision_score函数计算预测类别的精度。average='micro'参数指定应全局计算精度,通过计算总的真正例、假负例和假正例的数量。labels=categories参数指定用于精度计算的类别列表。
注意,average可以是micro、macro、samples、weighted或binary。官方文档解释了这些平均类型之间的区别。
总的来说,evaluate_precision函数加载News_Category_Dataset_v3.json数据集的一个小子集,用classify_sentence函数预测每个标题的类别,并计算预测类别的精度。返回的精度分数表示在数据集的这个小子集上classify_sentence函数的准确性。
一旦我们组合了所有组件,代码将如下所示:
import os
import openai
import pandas as pd
from openai.embeddings_utils import get_embedding
from openai.embeddings_utils import cosine_similarity
from sklearn.metrics import precision_score
def init_api():
with open(".env") as env:
for line in env:
key, value = line.strip().split("=")
os.environ[key] = value
openai.api_key = os.environ.get("API_KEY")
openai.organization = os.environ.get("ORG_ID")
init_api()
categories = [
"POLITICS",
"WELLNESS",
"ENTERTAINMENT",
"TRAVEL",
"STYLE & BEAUTY",
"PARENTING",
"HEALTHY LIVING",
"QUEER VOICES",
"FOOD & DRINK",
"BUSINESS",
"COMEDY",
"SPORTS",
"BLACK VOICES",
"HOME & LIVING",
"PARENTS",
]
# 定义一个分类句子的函数
def classify_sentence(sentence):
# 获取句子的嵌入
sentence_embedding = get_embedding(sentence, engine="text-embedding-ada-002")
# 计算句子与每个类别之间的相似性分数
similarity_scores = {}
for category in categories:
category_embeddings = get_embedding(category, engine="text-embedding-ada-002")
similarity_scores[category] = cosine_similarity(sentence_embedding, category_embeddings)
# 返回具有最高相似性分数的类别
return max(similarity_scores, key=similarity_scores.get)
def evaluate_precision(categories):
# 加载数据集
df = pd.read_json("data/News_Category_Dataset_v3.json", lines=True).head(20)
y_true = []
y_pred = []
# 对每个句子进行分类
for _, row in df.iterrows():
true_category = row['category']
predicted_category = classify_sentence(row['headline'])
y_true.append(true_category)
y_pred.append(predicted_category)
# 如果需要,取消下面一行的注释以打印真正和假正预测
# if true_category != predicted_category:
# print("False prediction: {:50} True: {:20} Pred: {:20}".format(row['headline'], true_category, predicted_category))
# print("True prediction: {:50} True: {:20} Pred: {:20}".format(row['headline'], true_category, predicted_category))
# 计算精度分数
return precision_score(y_true, y_pred, average='micro', labels=categories)
precision_evaluated = evaluate_precision(categories)
print("Precision: {:.2f}".format(precision_evaluated))