20世纪80年代,当我还是个孩子的时候,通过Basic和我的Atari发现了编程,我不明白为什么我们不能将基本的执行活动自动化,比如超速控制、违反交通灯和停车计时器。每一件事似乎都很简单:我的书上说过,要成为一个好的程序员,你应该避免使用GOTO语句。然而,当我在开发我的大富翁游戏时,我无法想象数据量(以及蓬勃发展的物联网,或称IoT)。当我的游戏装进64KB的内存时,我绝对不知道数据集会变得更大(以一个巨大的系数),也不知道数据会有一个速度,或者说速度,因为我正在耐心地等待我的游戏被保存在我的Atari 1010录音机上。
短短35年后,我想象中的那些用例似乎都可以获得(而我的游戏,是徒劳的)。数据的增长速度已经超过了支持数据的硬件技术的增长速度1一个小型计算机集群的成本可以低于一台大型计算机。与2005年相比,内存便宜了一半,2005年的内存比2000年便宜了5倍.网络速度快了许多倍,现代数据中心提供的速度高达100G比特/秒(Gbps),比五年前的家庭Wi-Fi快了近2000倍。这些都是促使人们提出这个问题的一些因素。如何使用分布式内存计算来分析大量数据?
当你阅读文献或在网络上搜索有关Apache Spark的信息时,你可能会发现它是一个大数据的工具,是Hadoop的继承者,是一个做分析的平台,是一个集群计算机框架等等。
LAB 本章的实验室可以在GitHub上找到,网址是https://github.com/jgperrin/net.jgp.books.spark.ch01。这是实验室#400。如果你不熟悉GitHub和Eclipse,附录A、B、C和D提供了指导。
Spark是什么,它的作用是什么
正如Antoine de Saint-Exupéry的《小王子》说的那样,给我画一个Spark。在本节中,你将首先看看什么是Spark,然后通过几个用例看看Spark能做什么。第一节最后描述了Spark是如何作为一个软件堆栈被集成并被数据科学家使用的。
什么是Spark?
对于数据科学家来说,Spark不仅仅是一个软件栈。当你构建应用程序时,你将它们构建在一个操作系统之上,如图1.1所示。操作系统提供的服务使你的应用开发更容易,换句话说,你并不是为你开发的每个应用构建一个文件系统或网络驱动。
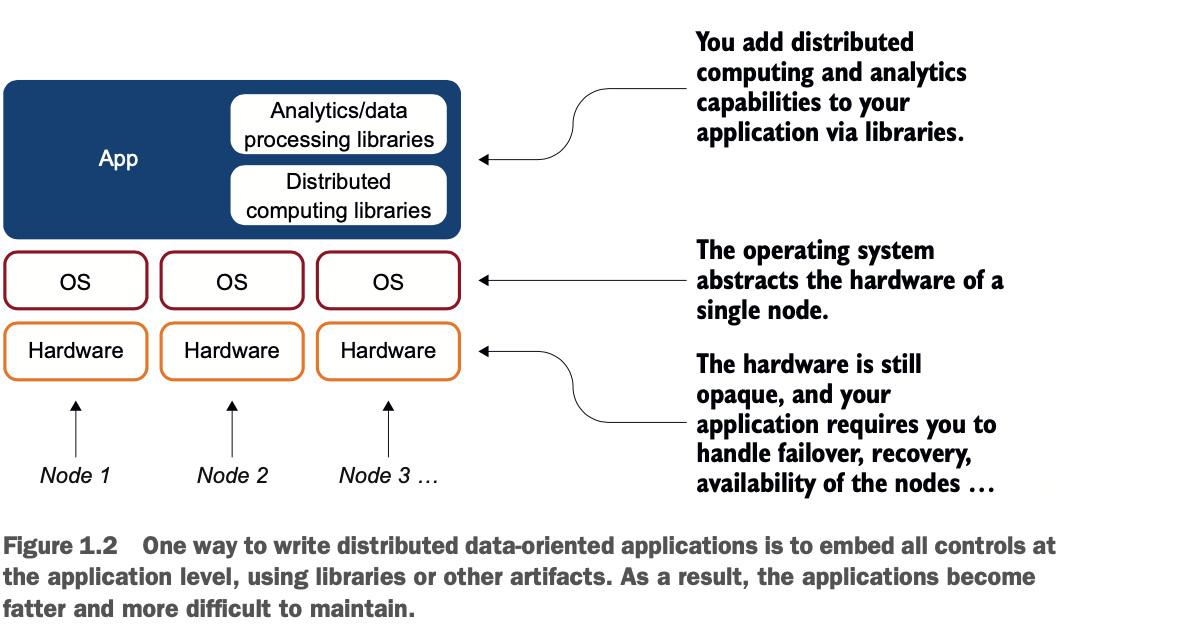
 随着对更多计算能力的需求,对分布式计算的需求也越来越大。随着分布式计算的出现,一个分布式的应用程序必须纳入这些分布式功能。图1.2显示了在应用程序中增加更多组件的复杂性。
随着对更多计算能力的需求,对分布式计算的需求也越来越大。随着分布式计算的出现,一个分布式的应用程序必须纳入这些分布式功能。图1.2显示了在应用程序中增加更多组件的复杂性。
 说了这么多,Apache Spark可能看起来像一个复杂的系统,需要你有很多先前的知识。我坚信,你只需要Java和关系型数据库管理系统(RDBMS)的技能,就可以理解、使用、利用和扩展Spark构建应用程序。
说了这么多,Apache Spark可能看起来像一个复杂的系统,需要你有很多先前的知识。我坚信,你只需要Java和关系型数据库管理系统(RDBMS)的技能,就可以理解、使用、利用和扩展Spark构建应用程序。
应用程序也变得更加智能,可以生成报表并进行数据分析(包括数据聚合、线性回归或简单显示环形图)。因此,当你想在你的应用程序中添加这样的分析功能时,你必须链接库或建立自己的库。所有这些都会让你的应用变得更大(或者说更胖,如胖客户端),更难维护,更复杂,因此,企业的成本也更高。
"那为什么不把这些功能放在操作系统层面呢?"你可能会问。把这些功能放在操作系统等较低层次的好处很多,包括以下几点:
* 提供处理数据的标准方法(有点像结构化查询语言,或关系数据库的SQL)。
* 降低了应用程序的开发(和维护)成本。
* 使你能够专注于了解如何使用工具,而不是工具如何工作。例如,Spark执行分布式摄取,你可以学习如何从中受益,而不必完全掌握Spark完成任务的方式)。
而这正是Spark对我的意义:一个分析操作系统。图1.3显示了这个简化的栈。
 在本章中,你会发现Apache Spark在不同行业和不同项目规模下的一些用例。这些例子会让你对你能实现的目标有一个小小的概述。
在本章中,你会发现Apache Spark在不同行业和不同项目规模下的一些用例。这些例子会让你对你能实现的目标有一个小小的概述。
我坚信,为了更好地了解我们所处的位置,我们应该看看历史。这也适用于信息技术(IT):如果你想知道我的看法,请阅读附录E。
现在,场景已经设定好了,你将深入了解Spark。我们将从一个全局的视角开始,看看存储和API,最后,通过你的第一个例子。
四大法力支柱
根据波利尼西亚人的说法,法力是体现在物体或人身上的自然元素力量的力量。这个定义符合你在所有Spark文档中都能找到的经典图表,它显示了将这些元素力量带到Spark中的四个支柱。Spark SQL、Spark Streaming、Spark MLlib(用于机器学习)和GraphX坐在Spark Core之上。虽然这是对Spark堆栈的精确表示,但我发现它有局限性。堆栈需要扩展以显示硬件、操作系统和你的应用,如图1.4。
 当然,Spark运行的集群可能并不完全为你的应用所使用,但你的工作将使用以下内容:
当然,Spark运行的集群可能并不完全为你的应用所使用,但你的工作将使用以下内容:
* Spark SQL来运行数据操作,就像RDBMS中的传统SQL作业一样。Spark SQL提供了API和SQL来操作你的数据。你将在第11章发现Spark SQL,并在之后的大部分章节中阅读更多关于它的内容。Spark SQL是Spark的基石。
* Spark Streaming,特别是Spark结构化流,来分析流数据。Spark的统一API将帮助你以类似的方式处理你的数据,无论是流式数据还是批处理数据。你将在第10章学习关于流式数据的具体内容。
* 用于机器学习的Spark MLlib和最近在深度学习方面的扩展。机器学习、深度学习和人工智能应该有自己的书。
* 用于利用图数据结构的GraphX。要了解更多关于GraphX的信息,你可以阅读Michael Malak和Robin East所著的《Spark GraphX in Action》(Manning,2016)。
如何使用Spark?
在本节中,你将通过关注典型的数据处理场景以及数据科学场景,详细了解如何使用Apache Spark。无论你是数据工程师还是数据科学家,你都能在工作中使用Apache Spark。
Spark在数据处理/工程场景中的应用案例分析
Spark可以以多种不同的方式处理你的数据。但当它在大数据场景中发挥作用时,它就会表现出色,在这个场景中,你会摄取数据、清理数据、转换数据和重新发布数据。
我喜欢把数据工程师看作是数据准备者和数据物流师。他们确保数据是可用的,确保数据质量规则被成功应用,确保转化成功执行,确保数据可供其他系统或部门使用,包括业务分析师和数据科学家。数据工程师也可以是将数据科学家的工作进行产业化。
Spark是数据工程师的完美工具。数据工程所执行的典型Spark(大数据)场景的四个步骤如下:
1 摄取
2 提高数据质量(DQ)
3 转换数据
4 推送
图1.5说明了这一过程。
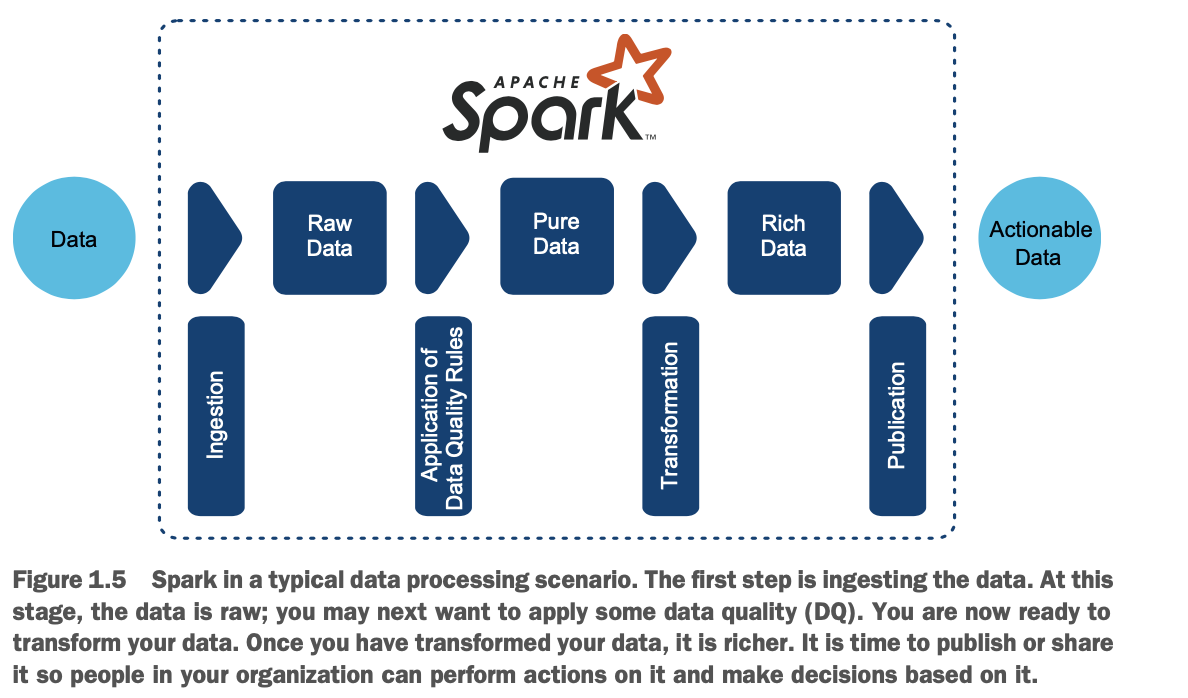 这个过程包括四个步骤,每一步之后,数据都会落在一个区域:
这个过程包括四个步骤,每一步之后,数据都会落在一个区域:
1 摄取数据-Spark 可以从各种来源摄取数据(参见第 7、8 和 9 章关于摄取的内容)。如果你找不到支持的格式,你可以建立自己的数据源。我把这个阶段的数据称为原始数据。你也可以发现这个区域被命名为暂存区、加载区、青铜区,甚至事件交换区( staging,landing,bronze,even,swamp zone)
2 提高数据质量(DQ) -在处理数据之前,你可能想检查数据本身的质量。DQ的一个例子是确保所有的出生日期都在过去。作为这个过程的一部分,你也可以选择混淆一些数据:如果你是在医疗保健环境中处理社会安全号码(SSN),你可以确保SSN不能被开发人员或非授权人员访问在你的数据被完善后,我把这个阶段称为纯数据区。你可能也会发现这个区域被称为精炼区、银子区、池塘区、沙箱区或探索区。
3 转化数据--下一步是处理你的数据。您可以将其与其他数据集加入,应用自定义函数,执行聚合,实现机器学习等。这一步的目标是获得丰富的数据,即你的分析工作的成果。大部分章节都在讨论转化。这个区域也可以称为生产、黄金、精炼、泻湖或运营化区域。
4 加载和发布--与ETL流程一样,5你可以通过将数据加载到数据仓库、使用商业智能(BI)工具、调用API或将数据保存在文件中来完成。其结果是为您的企业提供可操作的数据。
数据科学场景下的Spark
数据科学家的方法与软件工程师或数据工程师略有不同,因为数据科学家专注于转换部分,以互动的方式。为此,数据科学家使用不同的工具,如笔记本。笔记本的名字包括Jupyter、Zeppelin、IBM Watson Studio和Databricks Runtime。
数据科学家的工作方式对你来说肯定是很重要的,因为数据科学项目会消耗企业数据,因此你可能最终会将数据交付给数据科学家,将他们的工作(如机器学习模型)保存到企业数据存储中,或者将他们的发现产业化。
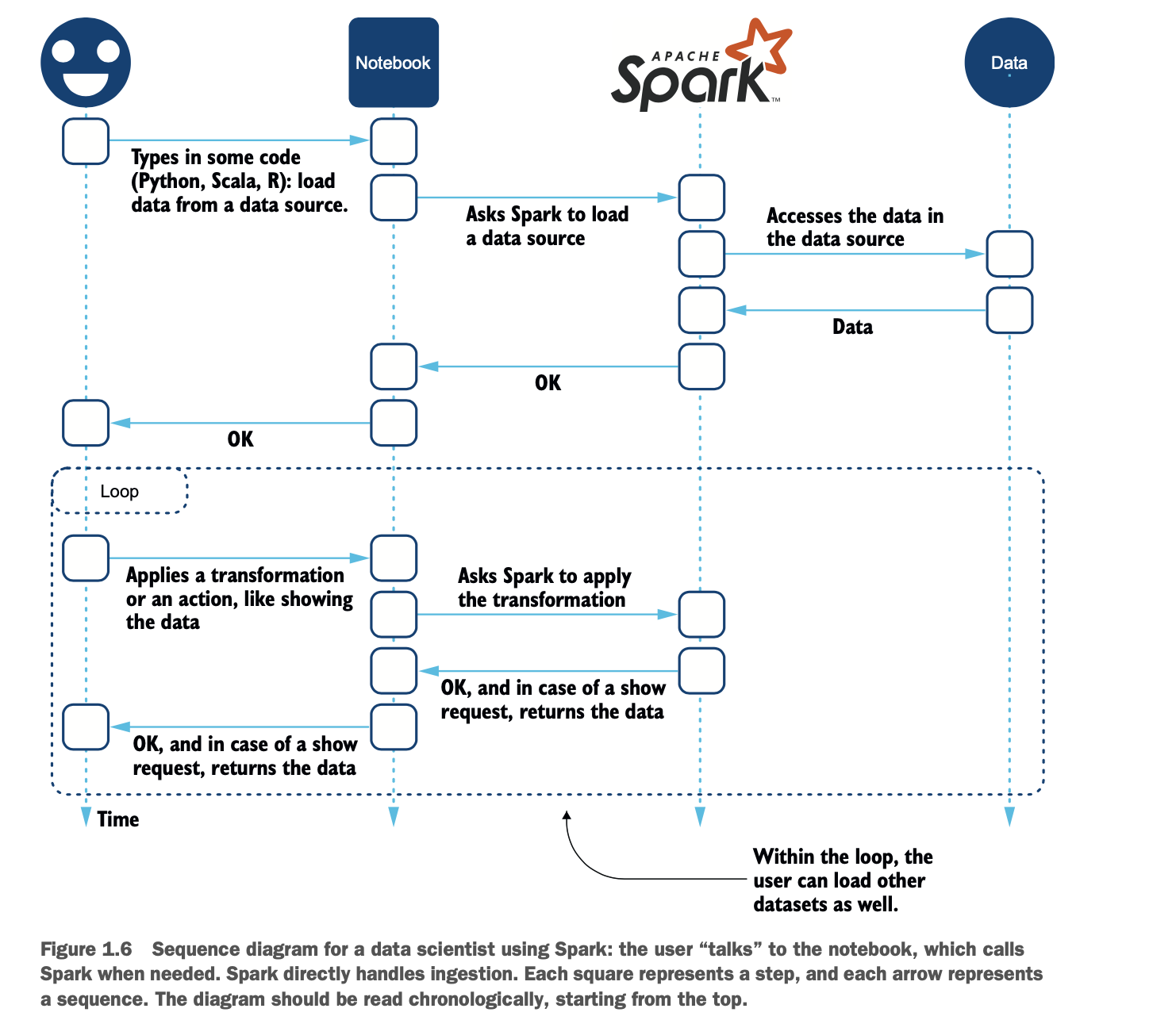
因此,一个类似UML的序列图,如图1.6,可以更好地解释数据科学家如何使用Spark。
 如果你想了解更多关于Spark和数据科学的知识,可以看看这些书。
如果你想了解更多关于Spark和数据科学的知识,可以看看这些书。
* Jonathan Rioux所著的《PySpark in Action》(Manning,2020,www.manning.com/books/pyspark-in-action?a_aid=jgp)。
* Mastering Large Datasets with Python by John T. Wolohan (Manning, 2020, www.manning.com/books/mastering-large-datasets-with-python?a_aid=jgp)。
在图1.6描述的用例中,数据被加载到Spark中,然后用户将使用数据,应用转换,并显示部分数据。显示数据并不是这个过程的结束。用户还可以继续以交互的方式,就像实体笔记本一样,在笔记本上写配方、做笔记等等。最后,笔记本用户可以将数据保存到文件或数据库中,或者制作(交互式)报告。
用Spark可以做什么?
Spark在各种项目中都有使用,所以我们来探讨一下其中的几个项目。所有的用例都涉及到无法在单台计算机上容纳或处理的数据(也就是大数据),因此需要一个计算机集群--因此需要一个分布式操作系统,专门用于分析。
随着时间的推移,大数据的定义已经发生了变化,从具有被称为 "五V "特征的数据到 "无法在一台计算机上容纳的数据"。我不喜欢这个定义;你可能知道,许多RDBMS将数据分割在几个服务器上。与许多概念一样,你可能要自己下定义。本书希望能帮助你。
对我来说,大数据是企业中随处可见的数据集的集合,这些数据集聚集在一个位置,你可以在上面运行基本分析到更高级的分析,比如机器和深度学习。这些更大的数据集可以成为人工智能(AI)的基础。技术、规模或计算机数量都与这个概念无关。
Spark通过其分析功能和原生分布式架构,可以解决大数据问题,无论你认为它是否大,也无论它是否适合放在一台或多台计算机中。简单的记住,传统的132列点阵打印机上的报表输出并不是Spark的典型用例。让我们来发现几个真实世界的例子。
Spark预测北卡罗来纳州餐馆的质量
在美国的大部分地区,餐馆都需要经过当地卫生部门的检查才能营业,并根据检查情况进行分级。更高的等级并不意味着更好的食物,但它可能会给一个指示,你是否会死后,你有烧烤在某个小屋在你的南方之旅。等级衡量的是厨房的清洁度、食物的安全储存程度以及更多的标准,以(希望)避免食源性疾病的发生。
在北卡罗来纳州,餐馆的等级是0到100分。每个县都提供了访问餐厅的等级,但没有中央位置访问信息全州。
NCEatery.com是一个以消费者为导向的网站,它列出了餐馆及其在一段时间内的检查等级。NCEatery.com的野心是将这些信息集中起来,并对餐厅进行预测分析,看能否发现餐厅质量的模式。两年前我喜欢的这个地方是不是在走下坡路?
在网站的后台,Apache Spark 摄取了来自不同县城的餐厅、检查和违规数据集,对数据进行压缩,并在网站上发布摘要。在压缩阶段,我们应用了一些数据质量规则,以及机器学习来尝试预测检查和分数。Spark处理1.6×1021个数据点,并使用一个小型集群每18小时发布约2500页。这个正在进行的项目正在入驻更多的NC县。
Spark允许Lumeris快速传输数据
Lumeris是一家基于信息的医疗保健服务公司,总部位于密苏里州圣路易斯市。它传统上一直在帮助医疗保健提供商从他们的数据中获得更多的洞察力。该公司最先进的IT系统需要得到提升,以适应更多的客户,并从数据中获得更强大的洞察力。
在 Lumeris,作为数据工程流程的一部分,Apache Spark 摄取了存储在 Amazon Simple Storage Service (S3) 上的大量逗号分隔值 (CSV) 文件,构建了符合 HL7 FHIR 标准的医疗保健资源,并将它们保存在一个专门的文档存储中,在那里它们可以被现有的应用程序和新一代的客户端应用程序所使用。
这种技术堆栈使Lumeris能够在处理数据和应用方面继续发展。未来,在这项技术的帮助下,Lumeris的目标是拯救生命。
#### Spark为欧洲核子研究中心分析设备日志
欧洲核子研究组织(CERN)成立于1954年。它是大型强子对撞机(LHC)的所在地,它是一个27公里长的环,位于日内瓦的法国和瑞士边界下100米处。
在那里运行的巨型物理实验每秒产生1PB的数据。经过大量的过滤后,每天的数据减少到900GB。
在使用Oracle、Impala和Spark进行实验后,CERN团队围绕Spark设计了Next CERN加速器日志服务(NXCALS),在一个运行OpenStack的预置云上运行,核心数高达25万个。这个令人印象深刻的架构的消费者是科学家(通过定制应用和Jupyter笔记本)、开发者和应用。欧洲核子研究中心的雄心壮志是要上马更多的数据,提高数据处理的整体速度。
其他用例
Spark还参与了许多其他的用例,包括以下几种:
* 构建交互式数据整理工具,如IBM的Watson Studio和Databricks的笔记本。
* 监测MTV或Nickelodeon等电视频道的视频馈送质量。
* 通过Riot Games公司监测在线电子游戏玩家的不良行为,并准实时调整玩家互动,最大限度地提高所有玩家的积极体验。
为什么你会喜欢dataframe
在本节中,我的目标是让你爱上dataframe。你会学到足够多的知识,从而想要发现更多的东西,随着你在第3章和整本书中的深入探索,你会发现更多的东西。数据框架既是一个数据容器,也是一个API。
dataframe的概念对于Spark来说是至关重要的。然而,这个概念并不难理解。你会一直使用数据框。在本节中,您将从Java(软件工程师)和RDBMS(数据工程师)的角度来了解什么是dataframe。当你熟悉了一些类比之后,我将用一张图来总结。
一个拼写问题
在大多数文献中,你会发现dataframe有不同的拼法:DataFrame. 我决定采用最英式的写法,我同意,这对一个法国人来说可能很奇怪。然而,尽管它的雄伟壮观,dataframe仍然是一个普通名词,所以没有理由在这里和那里玩大写字母。这又不是汉堡店!
从Java角度看DataFrame
如果你的背景是Java,并且你有一些Java数据库连接(JDBC)的经验,那么数据框就会看起来像一个ResultSet。它包含数据;它有一个API......。
ResultSet和数据框的相似之处如下:
* 数据可以通过一个简单的API访问。
* 你可以访问schema。
这里有一些不同之处:
* 你不能用 next() 方法浏览它。
* 它的 API 可通过用户定义函数(UDFs)进行扩展。你可以编写或包装现有的代码并将其添加到Spark中。然后,这些代码将以分布式模式被访问。你将在第16章学习UDF。
* 如果你想访问数据,你首先要得到Row,然后用getter(类似于ResultSet)去访问该行的列。
* 元数据是相当基本的,因为在Spark中没有主键或外键或索引。
在Java中,一个DataFrame被实现为Dataset<Row>(发音为 "行的数据集")。
从RDBMS角度看DataFrame
如果你更多的是来自RDBMS的背景,你可能会发现数据框就像一个表。以下是相似之处:
* 数据是用列和行来定义的。
* 数据列是强类型。
下面是一些不同之处:
* 数据可以被嵌套,就像JSON或XML文档一样。第7章描述了这些文档的摄取,你将在第13章使用这些嵌套结构。
* 你不需要更新或删除整个行,而是创建新的数据框架。
* 你可以轻松地添加或删除列。
* 在DataFrame中没有约束、索引、主键、外键或触发器。
DataFrame的图形表示
DataFrame是一个强大的工具,你将在本书和你的Spark之旅中使用。它强大的API和存储能力使它成为一切辐射的关键元素。图1.7显示了想象API、实现和存储的一种方式。
你的第一个例子
现在是你的第一个例子的时候了。你的目标是用一个简单的应用程序运行Spark,它将读取一个文件,将其内容存储在一个DataFrame中,并显示结果。你将学习如何设置你的工作环境,你将在本书中使用。你还将学习如何与Spark交互,并进行基本操作。
正如你会发现的那样,大多数章节都包含了专门的实验室,你可以通过破解这些实验室来实验代码。每个实验室都有一个数据集(尽可能是真实生活中的数据集),以及一个或多个代码列表。
要开始,你将做以下工作。
* 安装基本软件,你可能已经有了。Git, Maven, Eclipse.
* 从GitHub下载代码。
* 执行这个例子,它将加载一个基本的CSV文件并显示一些行。
推荐软件
本节提供了你将在本书中使用的软件清单。所需软件的详细安装说明见附录A和附录B。
本书使用了以下软件。
* Apache Spark 3.0.0。
* 主要是macOS Catalina,但实例也可以在Ubuntu 14~18和Windows 10上运行。
* Java 8 (尽管你不会使用很多在8版本中引入的构造,比如lambda函数)。我知道Java 11是可用的,但大多数企业在采用较新的版本方面进展缓慢(而且我发现Oracle最近的Java策略有点令人困惑)。截至目前,只有Spark v3获得了Java 11的认证。
示例将使用命令行或Eclipse。对于命令行,你可以使用以下方法。
* Maven:本书使用的是3.5.2版本,但任何最近的版本都可以使用。
* Git的版本是2.13.6,但任何最新的版本也可以使用。在macOS上,你可以使用Xcode打包的版本。在 Windows 上,你可以从 https://git-scm.com/download/win 下载。如果你喜欢图形用户界面(GUI),我强烈推荐Atlassian Sourcetree,你可以从以下网站下载。来自www.sourcetreeapp.com。
项目使用Maven的pom.xml结构,它可以被导入或直接用于许多集成开发环境(IDE)。然而,所有的可视化示例都将使用Eclipse。你可以使用任何比4.7.1a(Eclipse Oxygen)更早的Eclipse版本,但Maven和Git的集成在Eclipse的Oxygen版本中得到了增强。我强烈建议你至少使用Oxygen版本,现在已经很老了。
下载代码
源代码在GitHub上的一个公共仓库中。仓库的 URL 是 https://github.com/jgperrin/net.jgp.books.spark.ch01。附录D详细介绍了如何在命令行上使用Git和Eclipse下载代码。
运行您的第一个应用程序
现在你已经准备好运行你的应用程序了! 如果你在运行第一个应用程序时遇到任何问题,附录R应该可以帮你解决。
命令行
在命令行中,改到工作目录。
$ cd net.jgp.books.spark.ch01
然后运行这个
$ mvn clean install exec:exec
ECLIPSE
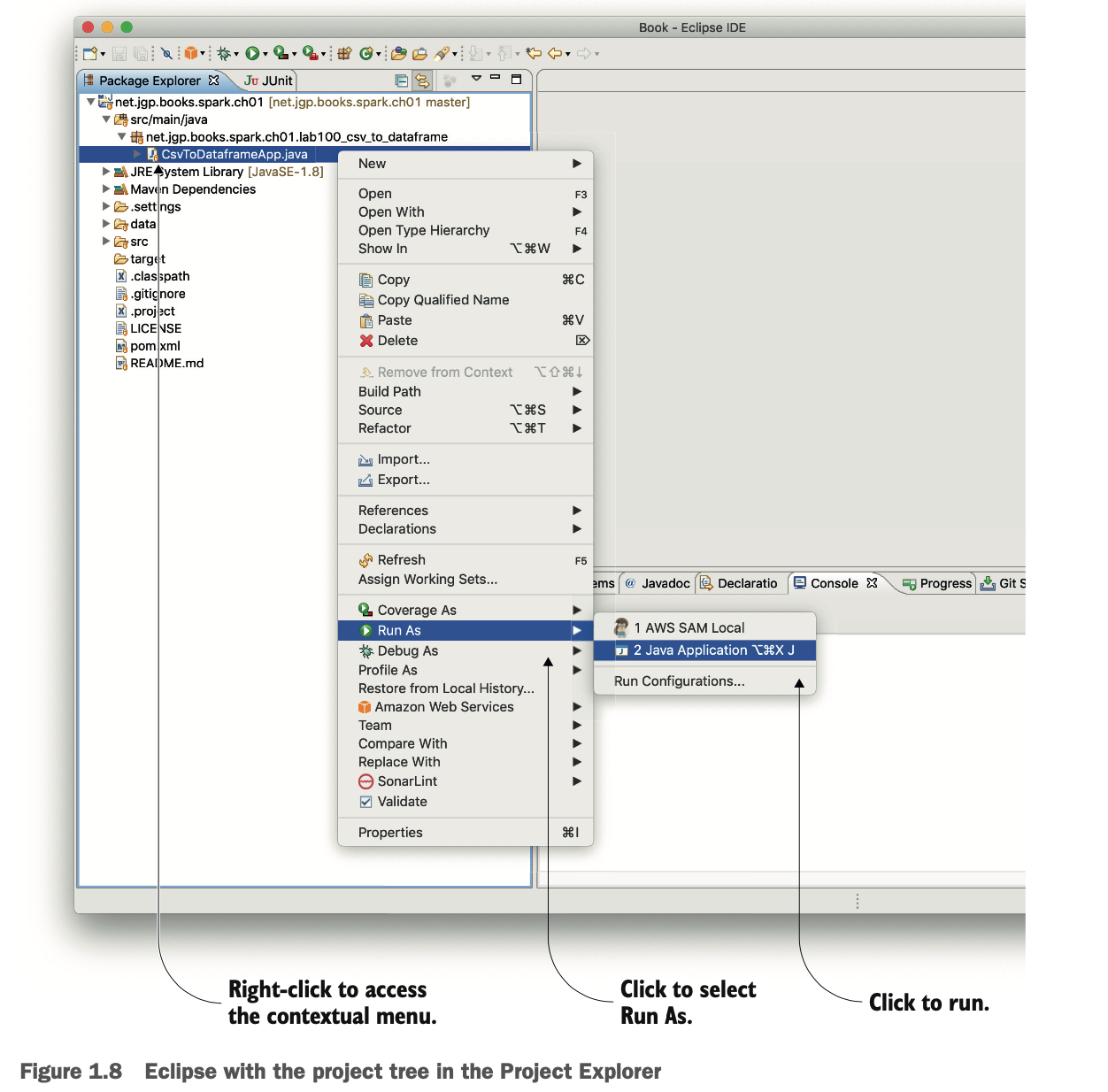
导入项目后(见附录D),在项目资源管理器中找到CsvToDataframeApp.java。右键单击该文件,然后选择 Run As > 2 Java Application,如图1.8所示。看看控制台中的结果。
 无论是使用命令行还是Eclipse,几秒钟后的结果应该是这样的:
无论是使用命令行还是Eclipse,几秒钟后的结果应该是这样的:
 现在,让我们来了解一下发生了什么。
现在,让我们来了解一下发生了什么。
您的第一个代码
终于,你在编码了! 在上一节中,你看到了输出。现在是你运行第一个应用程序的时候了。它将获取一个会话,要求Spark加载一个CSV文件,然后显示数据集的五行(最多)。清单1.1提供了完整的程序。
在显示代码时,存在两派思路:一派是显示抽象的代码,另一派是呈现所有的代码。我是后一派。我喜欢完整的例子,而不是部分的,因为我不希望你必须找出缺失的部分或所需的包,即使它们很明显。
 虽然这个例子很简单,但你已经完成了以下工作。
虽然这个例子很简单,但你已经完成了以下工作。
* 安装了使用Spark所需的所有组件。是的,就是这么简单!)。
* 创建一个可以执行代码的会话。
* 加载了一个CSV数据文件。
* 显示该数据集的五行。
现在你已经准备好深入了解Apache Spark,并更多地了解引擎盖下的东西。
概要
* Spark是一个分析操作系统;你可以用它以分布式的方式处理工作负载和算法。而且它不仅适用于分析:你可以使用Spark进行数据传输、海量数据转换、日志分析等。
* Spark支持SQL、Java、Scala、R和Python作为编程接口,但在本书中,我们主要关注Java(有时也关注Python)。
* Spark的内部主要数据存储是DataFrame。DataFrame将存储容量与API结合起来。
* 如果你有JDBC开发的经验,你会发现与JDBC ResultSet有相似之处。
* 如果你有关系型数据库的开发经验,你可以把数据框比作元数据较少的表。
* 在Java中,DataFrame被实现为Dataset<Row>。
* 你可以用Maven和Eclipse快速设置Spark。Spark不需要安装。
* Spark不局限于MapReduce算法:它的API允许很多算法应用于数据。
* 流媒体在企业中的使用越来越频繁,因为企业希望能够访问实时分析。Spark支持流式分析。
* 分析已经从简单的连接和聚合发展到了现在。企业希望计算机能够替我们思考,因此Spark支持机器学习和深度学习。
* 图表是分析的一个特殊用例,尽管如此,Spark支持他们。