在本章中,你将建立一个Apache Spark的心智模型。心智模型是用你的思维过程和跟随图来解释某件事情在现实世界中是如何工作的。本章的目标是帮助你定义你自己的想法,关于我将引导你完成的思维过程。我将使用大量的图表和一些代码。如果要建立一个独特的Spark心理模型,那将是非常矫情的,这个模型将描述一个涉及加载、处理和保存数据的典型场景。你也将会走过这些操作的Java代码。
你将遵循的场景涉及分布式加载一个CSV文件,执行一个小操作,并将结果保存在PostgreSQL数据库(和Apache Derby)中。要理解这个例子,并不需要了解或安装PostgreSQL。如果你熟悉使用其他RDBMS和Java,你会很容易适应这个例子。附录F提供了关于关系型数据库的额外帮助(技巧、安装、链接等)。
LAB代码和样本数据可以在GitHub上找到,网址是https://github.com/jgperrin/net.jgp.books.spark.ch02.
建立你的心智模型
在本节中,你将建立一个Spark的心智模型。在软件方面,心智模型是一个概念图,你可以用它来规划、预测、诊断和调试你的应用程序。为了开始建立心理模型,你将通过一个大数据场景进行工作。在学习这个场景的同时,您将探索Spark的整体架构、流程和术语,并将很好地理解Spark的全局。
想象一下下面的大数据场景:你是一个书商,在一个文件里有一个作者列表,你想对这个文件进行一个基本的操作,然后保存在数据库里。在技术上,这个过程如下:
1. 摄取一个CSV文件,就像你在第1章看到的那样。
2. 通过连接姓氏和名字来转换数据。
3. 将结果保存在关系型数据库中。
图2.1说明了你和Spark要做的事情:
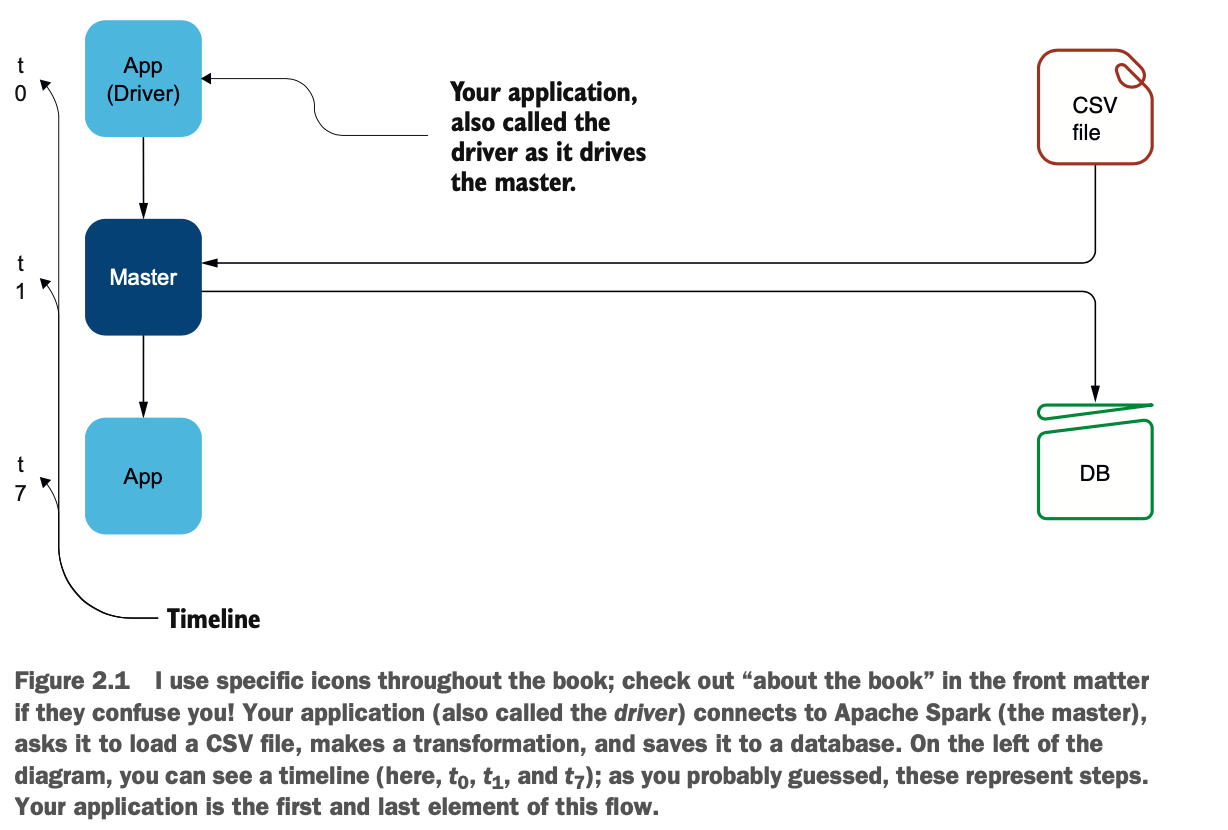 你的应用程序,或驱动程序,连接到一个Spark集群。从那里,应用程序告诉集群做什么:应用程序驱动集群。在这种情况下,主控通过加载CSV文件开始,最后保存在数据库中。
你的应用程序,或驱动程序,连接到一个Spark集群。从那里,应用程序告诉集群做什么:应用程序驱动集群。在这种情况下,主控通过加载CSV文件开始,最后保存在数据库中。
示例环境 对于实验室100,我最初使用Spark v2.4.0,PostgreSQL v10.1和PostgreSQL JDBC驱动v42.1.4,在macOS v10.13.2上使用Java 8。实验室110使用Apache Derby v10.14.2.0作为后台。代码大部分是一样的,所以如果你不想(或不能)安装PostgreSQL,可以跟着实验室#110一起做。
### 使用Java代码建立你的心理模型
在深入研究建立心智模型的每一步之前,我们先来分析一下应用程序的整体。在本节中,你将先设定Java的 "礼节",然后再解构并深入研究每一行代码及其后果。
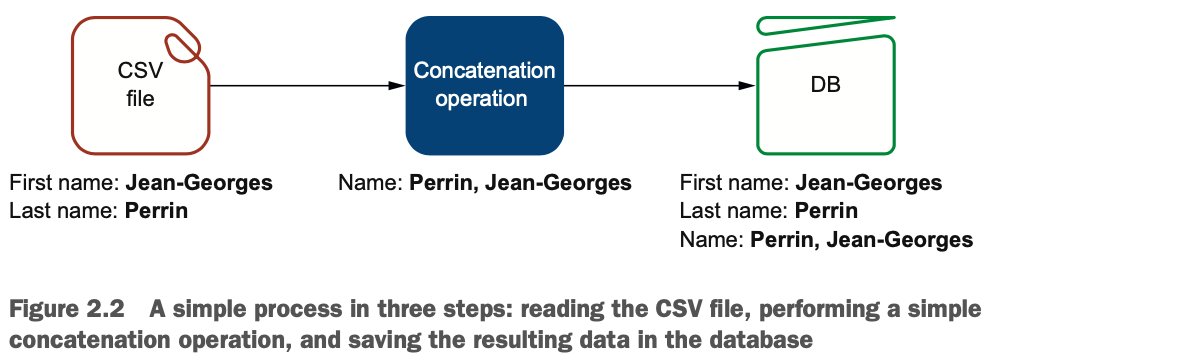
图2.2是这个过程的基本表示。Spark读取一个CSV文件;将姓氏、逗号和名字连接起来;然后将整个数据集保存在数据库中。
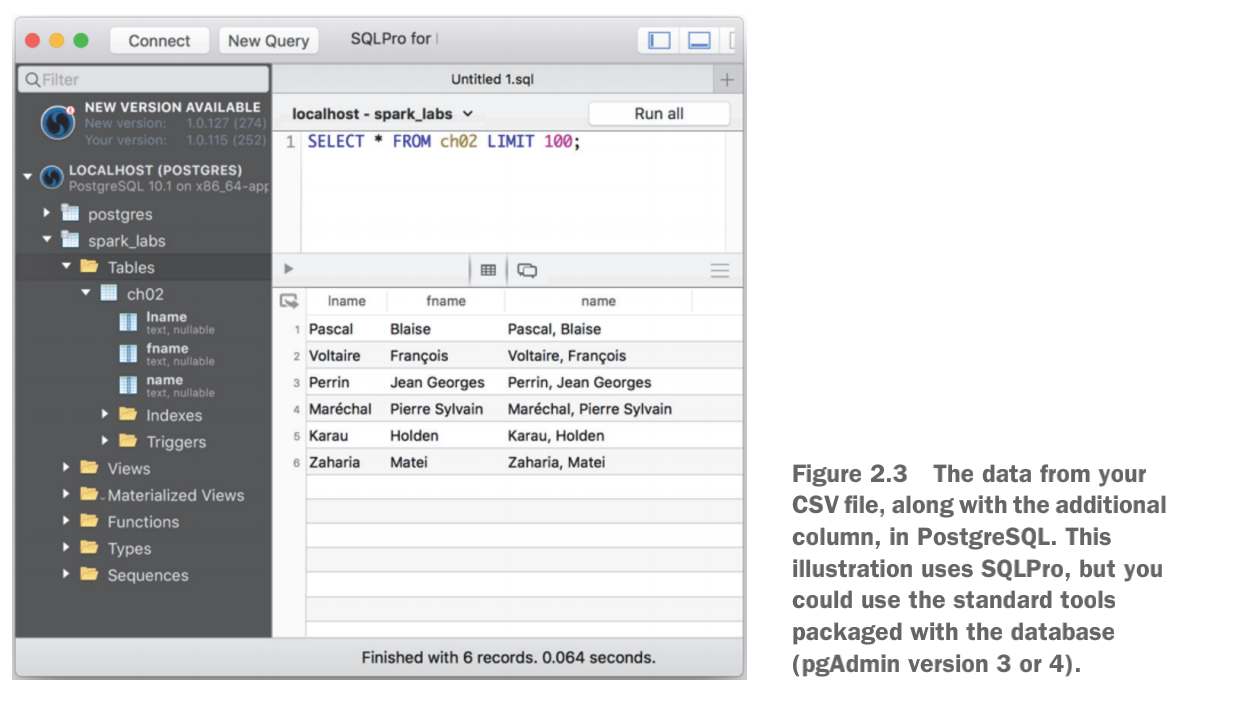
 当你运行这个应用程序时,你会得到一个简单的Process complete消息。图2.3说明了这个过程的结果。你的ch02表有三列--fname,lname,以及你想要的新列name。如果你需要数据库的帮助,请参考附录F。
当你运行这个应用程序时,你会得到一个简单的Process complete消息。图2.3说明了这个过程的结果。你的ch02表有三列--fname,lname,以及你想要的新列name。如果你需要数据库的帮助,请参考附录F。
 清单2.1是完整的应用程序。我尽量将代码完整地呈现出来,包括导入语句,以防止你使用错误的包或类似名称的废弃类。这段代码可以从GitHub下载,网址是:https://github.com/jgperrin/net.jgp.books.spark.ch02。
清单2.1是完整的应用程序。我尽量将代码完整地呈现出来,包括导入语句,以防止你使用错误的包或类似名称的废弃类。这段代码可以从GitHub下载,网址是:https://github.com/jgperrin/net.jgp.books.spark.ch02。
 如果你很好奇,已经觉得很舒服了,你可以再多做几步(另一个法语口语是指走火入魔),参考Spark Javadoc,网址是https://spark.apache.org/docs/latest/api/java/index.html。
如果你很好奇,已经觉得很舒服了,你可以再多做几步(另一个法语口语是指走火入魔),参考Spark Javadoc,网址是https://spark.apache.org/docs/latest/api/java/index.html。
你将需要PostgreSQL JDBC驱动程序。因此,你的pom.xml文件应该包含下面列表中的依赖关系。
 因为pom.xml是和一个章节的所有实验室共享的,而且因为实验室110使用的是Apache Derby而不是PostgreSQL,所以版本库中的pom.xml(在GitHub中)也包含了Derby的依赖关系。
因为pom.xml是和一个章节的所有实验室共享的,而且因为实验室110使用的是Apache Derby而不是PostgreSQL,所以版本库中的pom.xml(在GitHub中)也包含了Derby的依赖关系。
通过您的申请
你已经看到了一个简单的用例,即Spark从CSV文件中摄取数据,执行一个简单的操作,然后将结果存储在数据库中。在本节中,你将会看到幕后真正发生的事情。
首先,你将更仔细地观察第一个操作:与Master的连接。在这个非功能性的步骤之后,让我们来看看摄取、转换,以及最后在RDBMS中发布数据的过程。
连接到Master
对于每一个Spark应用,第一个操作是连接到Spark master,并获得一个Spark会话。这是你每次都要做的操作。这一点通过清单2.3中的代码片段和图2.4来说明。
在这种情况下,你是以本地模式连接到Spark。你将在第5章中发现连接和使用Spark的三种方法。

方法链让Java更紧凑
近年来,越来越多的Java API使用方法链,如SparkSession.builder().appName(...).master(...).getOrCreate()。此前,你可能看到更多的中间对象被创建,有点像这样。
Object1 o1 = new Object1(); Object2 o2 = o1.getObject2(); o2.set("something")。
Spark的API使用了大量的方法链。方法链让你的代码更紧凑,更易读。但一个主要的缺点是调试:想象一下在你的链中间出现一个空指针异常(NPE),你会花更多的时间来调试它。
本章的所有插图都代表了一条时间线。在t0,你开始你的应用程序(你的main()函数),在t1,你得到你的会话。
这第一步总是要连接到一个Master。现在你可以要求Spark加载CSV文件。

本地模式不是一个集群,但它是更简单的
为了让你能够在不设置一个完整的集群的情况下运行本章的例子,我指定了本地作为Master的值,因为你是在本地模式下运行Spark。如果你有一个集群,你会给出这个集群的地址。你将在第5章和第6章学习更多关于集群的知识。
为了建立你的心理模型,你将假设你有一个集群而不是本地模式。
加载或摄取CSV文件
加载、摄取和读取是你现在要做的事情的同义词:要求Spark加载CSV文件中包含的数据。Spark可以通过集群的各个节点使用分布式摄取。现在是时候要求Spark加载文件了吧?你已经在本章中学习了好几页新概念,所以现在是Spark为你做事的黄金时间。
但是你可以想象,就像所有的好主人一样,Spark做的事情并不多。Spark依靠的是slaves,或者说是workers。你会在Spark文档中找到这两个术语;尽管我是法国人,而且天生优柔寡断,但我还是要用工人。
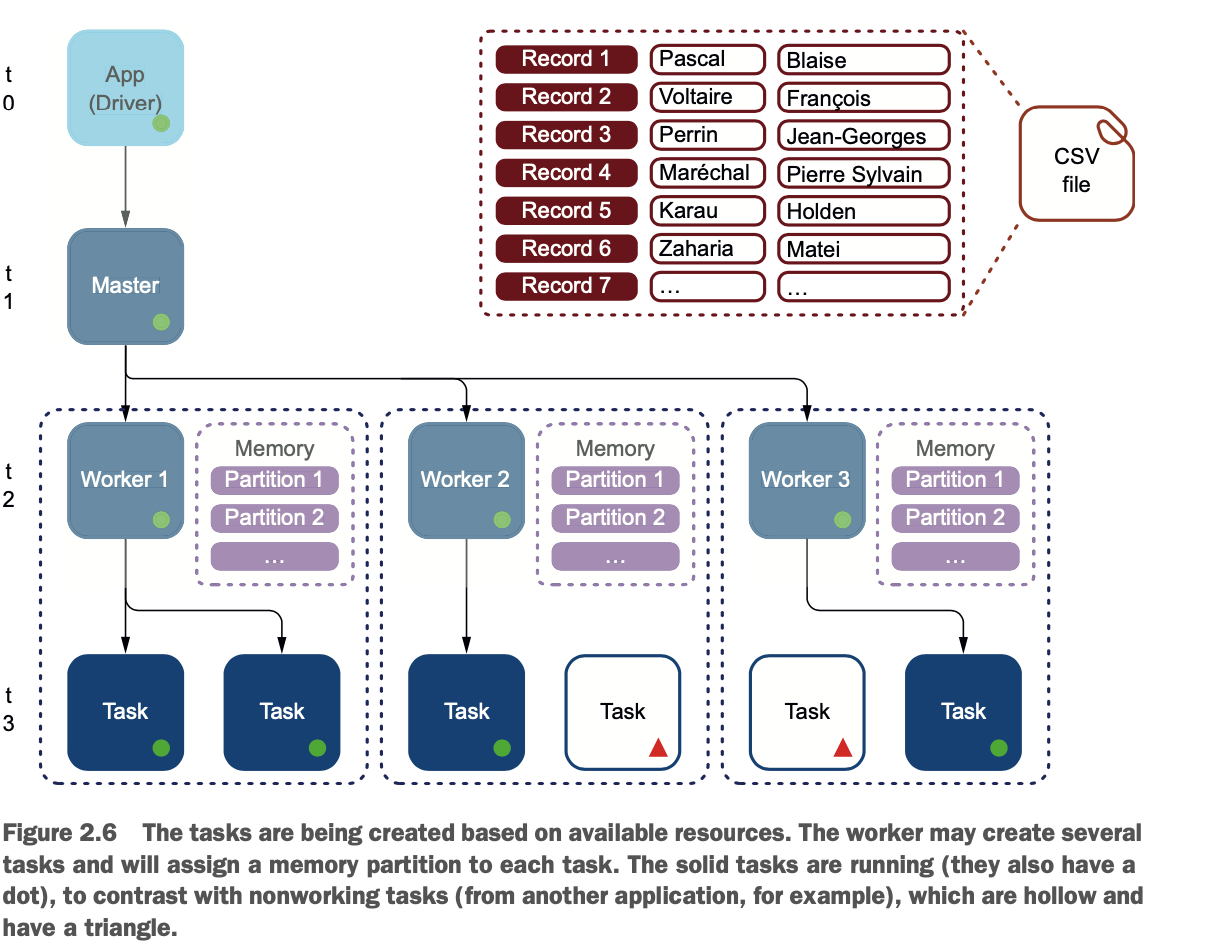
在我们的方案中,如图2.5所示,你有三个工人。分布式摄取意味着你将要求我们的三个工人同时摄取。
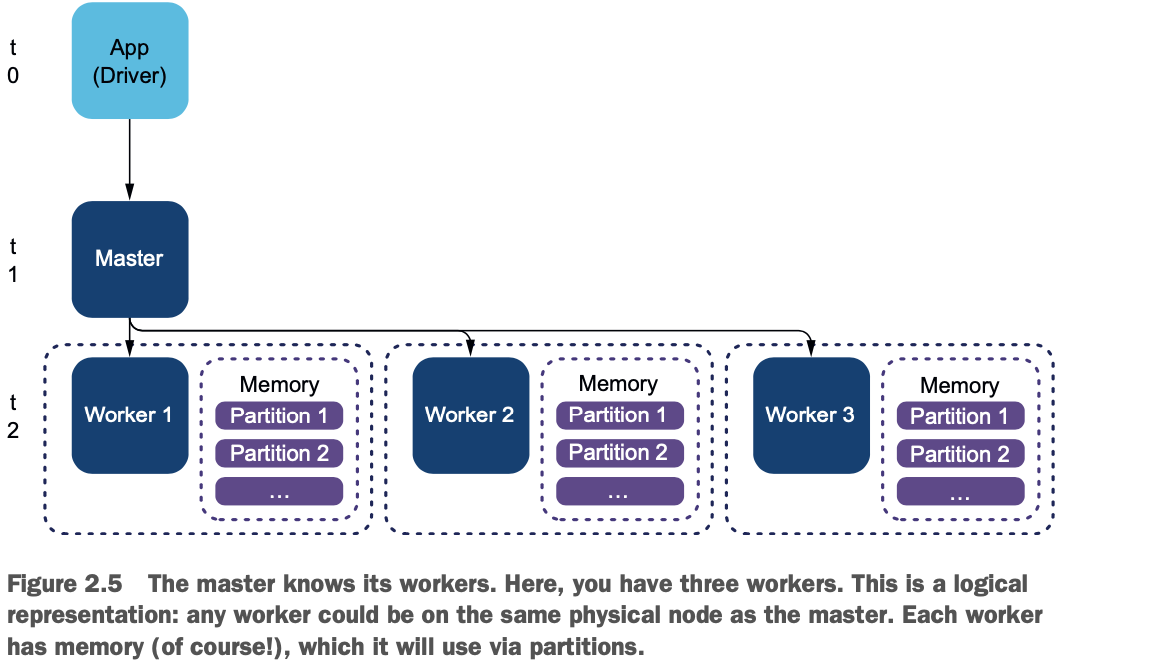 在t2,Master告诉工人加载文件,如清单2.4中的编码。你可能会想,"如果你有三个工人,哪一个在加载文件?"或者 "如果他们同时加载,他们怎么知道在哪里开始和结束?" Spark将以分布式方式摄取CSV文件。文件必须在共享驱动器、分布式文件系统(如第18章中的HDFS)上,或通过共享文件系统机制(如Dropbox、Box、Nextcloud或ownCloud)共享。在这种情况下,分区是工人内存中的一个专用区域。
在t2,Master告诉工人加载文件,如清单2.4中的编码。你可能会想,"如果你有三个工人,哪一个在加载文件?"或者 "如果他们同时加载,他们怎么知道在哪里开始和结束?" Spark将以分布式方式摄取CSV文件。文件必须在共享驱动器、分布式文件系统(如第18章中的HDFS)上,或通过共享文件系统机制(如Dropbox、Box、Nextcloud或ownCloud)共享。在这种情况下,分区是工人内存中的一个专用区域。
 让我们来看看我们的CSV文件(见列表2.5)。这是一个简单的文件,有两列:lname代表姓,fname代表名。文件的第一行是页眉。这个文件还包含六行,在我们的数据框架中,这六行将成为六行。
让我们来看看我们的CSV文件(见列表2.5)。这是一个简单的文件,有两列:lname代表姓,fname代表名。文件的第一行是页眉。这个文件还包含六行,在我们的数据框架中,这六行将成为六行。
lname,fname
Pascal,Blaise
Voltaire,François
Perrin,Jean-Georges
Maréchal,Pierre Sylvain
Karau,Holden
Zaharia,Matei工人将创建任务来读取文件。每个工作者都可以访问节点的内存,并为任务分配一个内存分区,如图2.6所示。
在t4,每个任务将继续读取CSV文件的一部分,如图2.7所示。由于任务正在摄取它的行,它将它们存储在一个专用的分区中。
图2.7显示了在摄取过程中从CSV文件复制到分区的记录,在R > P(Record to Partition)框内。内存框中显示了哪些记录在哪个分区中。在这个例子中,包含Blaise Pascal的记录1在第一个工作者的第一个分区中。
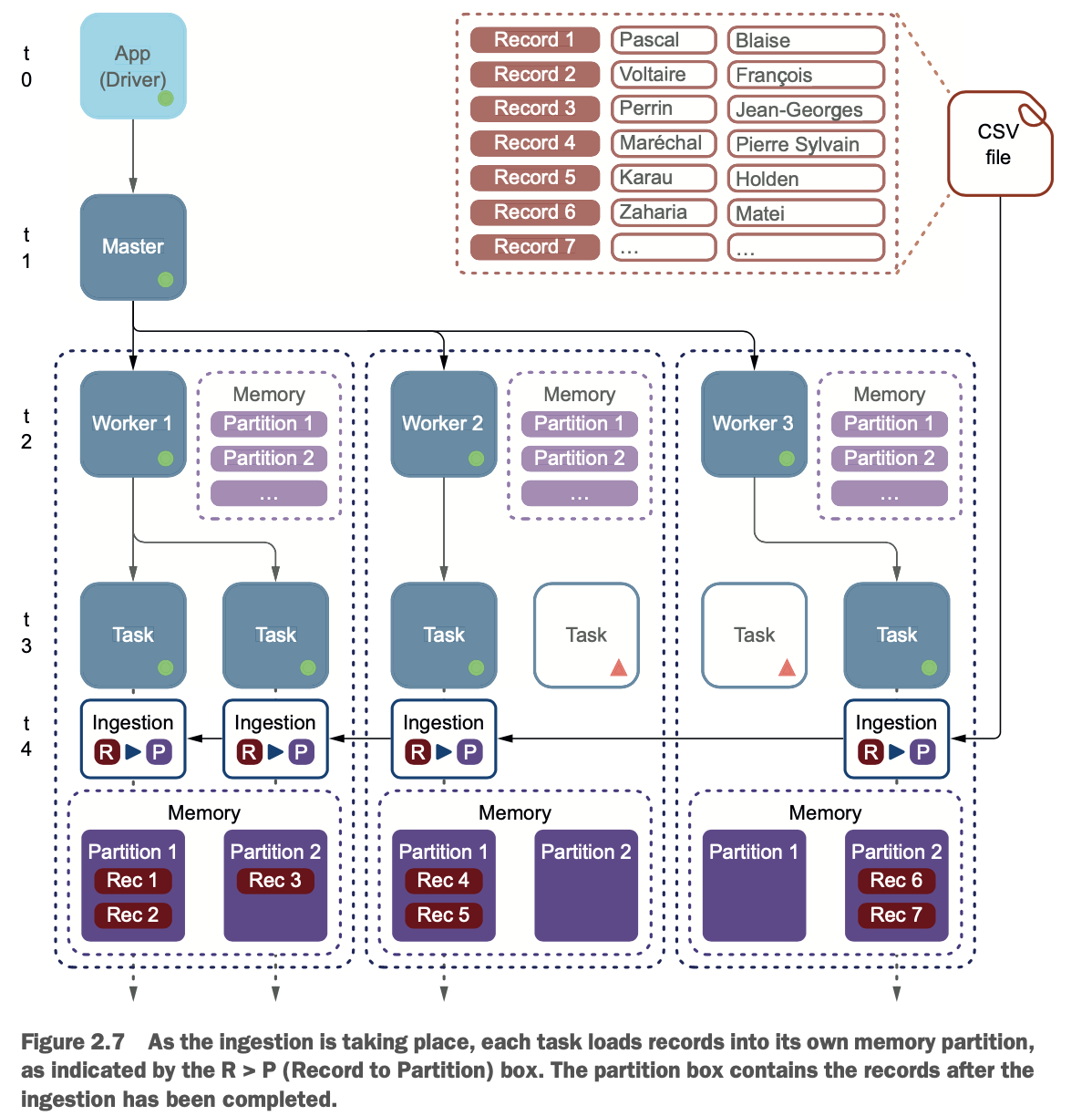
为什么你要关心分区和它们的位置?
因为你的操作非常简单(例如,在第三个字段中连接两个字段),所以Spark会非常快。
正如你将在第12章和第13章中看到的那样,Spark可以连接来自多个数据集的数据,并且可以进行数据聚合,就像你在关系型数据库中进行这些操作一样。现在想象一下,你正在将worker 1的第一个分区的数据与worker 2的第二个分区的数据连接起来:所有的数据都必须被传输,这是一个昂贵的操作。
你可以对数据进行重新分区,这可以使你的应用程序更有效率,你将在第17章中看到这一点。
转换您的数据
数据加载完毕后,在t5,你可以处理记录。你的操作相当简单:你将在数据框中添加一个新的列,称为name。全名(在列名中)是由姓(来自列lname)、逗号、空格和名(来自列fname)连接而成。因此,Jean-Georges(名)和Perrin(姓)变成了Perrin, Jean-Georges。清单2.6描述了这个过程,图2.8说明了这个过程。


Spark是懒惰的
就像塞斯-罗根说的那样:"我很懒,但不知道为什么,我太偏执了,以至于我最终还是努力工作。"这就是Spark的行为。这个时候,你让Spark去连通字段,但它什么也没做。
Spark是懒惰的:只有在被要求时它才会工作。Spark会把你所有的请求堆积起来,当它需要的时候,它会优化操作,做艰苦的工作。你将在第4章更仔细地研究它的懒惰。而且,就像Seth一样,当你要求得很好的时候,Spark会非常努力地工作。
在这种情况下,你使用的是withColumn()方法,这是一种转换。Spark只有在看到一个操作时才会开始处理,比如清单2.7中的write()方法。
现在你已经准备好了最后一个操作:将结果保存在数据库中。
将DataFrame中的工作保存到数据库中
在摄取CSV文件并在DataFrame中形成数据后,是时候将结果保存到数据库了。负责这个操作的代码在下面的列表中,如图2.9所示。
 你肯定熟悉JDBC,你可能已经注意到Spark需要类似的信息。
你肯定熟悉JDBC,你可能已经注意到Spark需要类似的信息。
* 一个JDBC连接的URL
* 驱动程序的名称
* 一个用户
* 一个密码
write()方法返回一个DataFrameWriter对象,你可以在这个对象上链上一个mode()方法来指定如何写入;在这里,你将覆盖表中的数据。
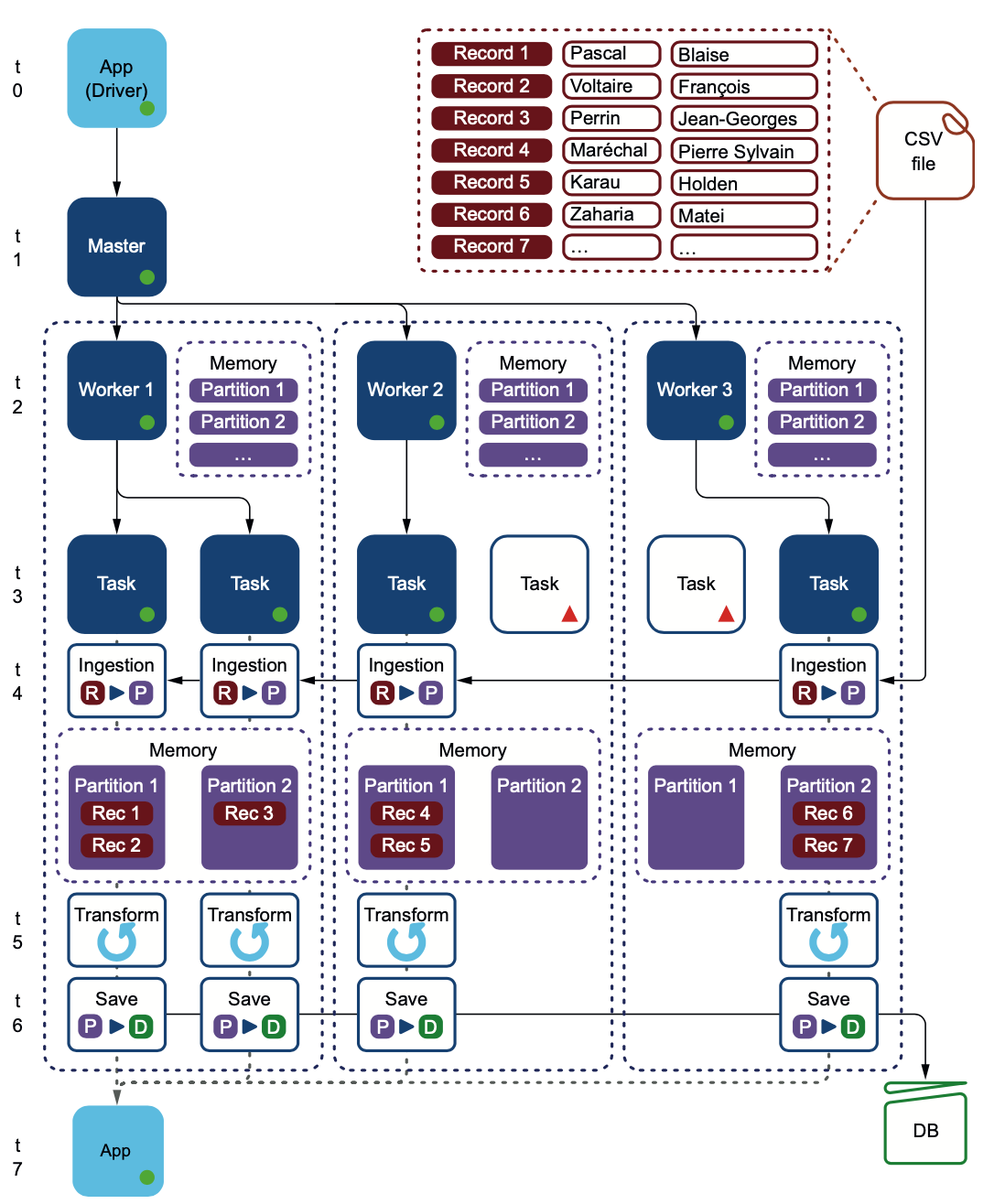
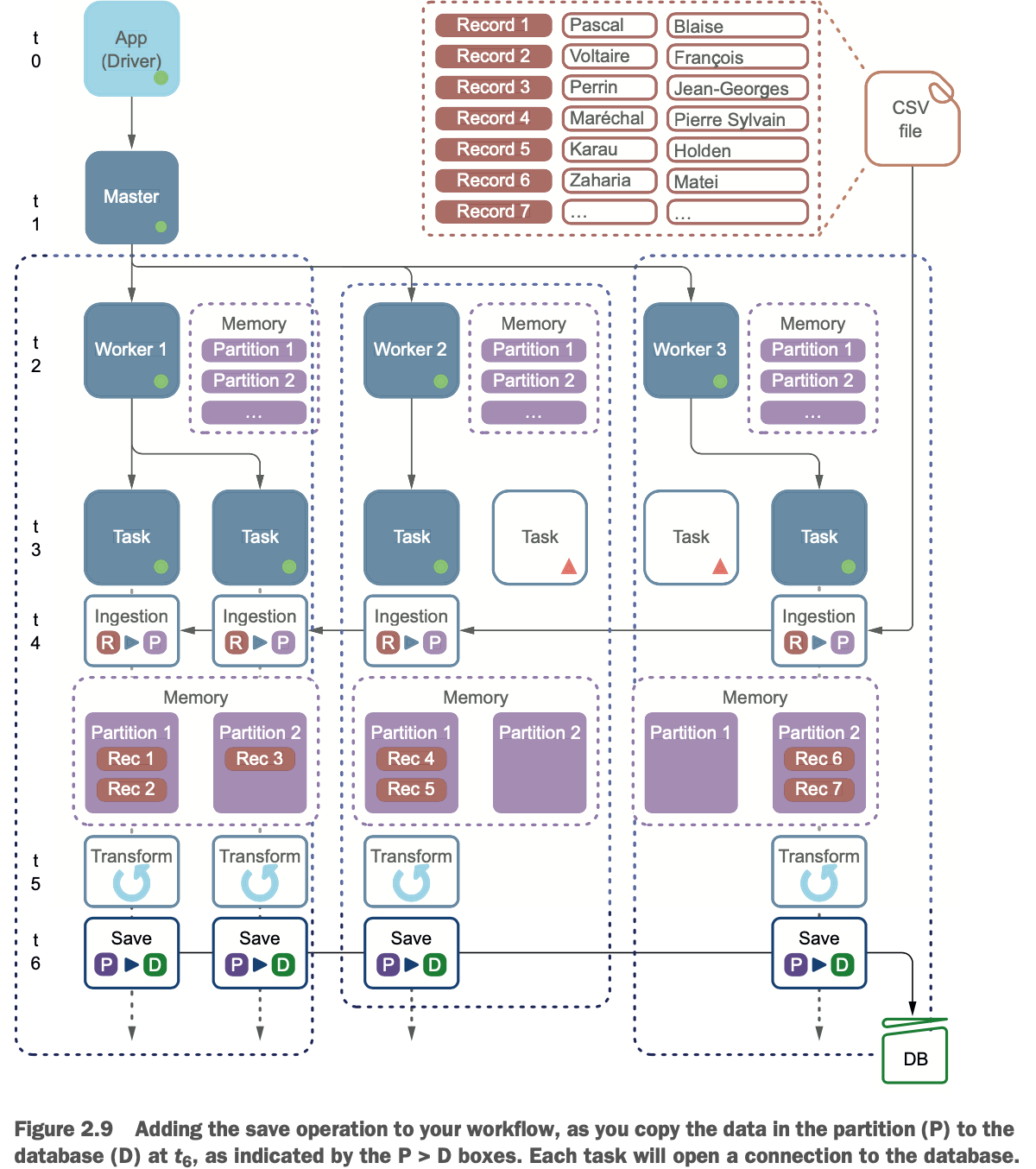 图2.10表示你的应用程序的完整心智模型。重要的是要记住以下几点。
图2.10表示你的应用程序的完整心智模型。重要的是要记住以下几点。
* 整个数据集永远不会打到我们的应用程序(驱动程序)上。数据集被分割在worker上的各个分区之间,而不是在驱动上。
* 整个处理过程在worker中进行。
* 工作者将其分区中的数据保存到数据库中。在这种情况下。
你有四个分区,这意味着你保存数据时有四个连接到数据库。想象一下类似的场景,有20万个任务首先试图连接到数据库,然后插入数据。微调的数据库服务器会拒绝过多的连接,这就需要在应用中多加控制。第17章通过重新分区和导出到数据库时的选项来解决这个负载问题。

概要
* 您的应用程序是驱动程序。数据可能不需要到驱动中来,它可以被远程驱动。当你确定部署规模时,记住这一点是很重要的(参见第5、6和18章)。
* 驱动程序连接到一个Master并获得一个会话。数据将被附加到这个会话上;会话定义了数据在 Worker 节点上的生命周期。
* Master可以是本地(你的本地机器)或远程集群。使用本地模式将不需要你建立一个集群,使你在开发时的生活更加轻松。
* 数据是分区的,并在分区内处理。分区在内存中。
* Spark可以很容易地从CSV文件中读取数据(更多细节见第7章)。
* Spark可以轻松地将数据保存在关系型数据库中(更多细节在第17章)。
* Spark是懒惰的:只有当你通过操作要求它这样做时,它才会工作。这种懒惰对你有好处,第4章提供了更多细节。
* Spark的API严重依赖方法链。