从几千米(或英尺,如果你拘泥于英制)的地方看你的数据,并关注数据生成的部分。你看到的是成批生成数据的系统,还是连续生成数据的系统?提供数据流的系统,也就是所谓的流,几年前还不太流行。流肯定是越来越受欢迎了,理解流是本章的重点。
比如说,你的手机会定期对手机信号塔进行ping。如果是智能手机(根据本书的受众,极有可能),它还会查看电子邮件等。
穿越(智能)城市的公交车会发送其GPS坐标。
超市收银台的收银机在收银员(或你)将物品递到扫描仪前时,会产生数据。当你付款时,一笔交易就被处理了。
当你把你的车开到车库时,一系列的信息被收集、存储和处理。
在美国,当病人进入医疗机构时,会产生包含原子信息的信息,称为入院、出院和转院(ADTs)。
企业喜欢流式数据;与隔夜处理后相比,它能让他们更好地敏锐地了解正在发生的事情。在我居住的北卡罗来纳州,可能在美国其他地方,一旦宣布发生灾难,人们就会冲到商店去买牛奶、水和海绵面包(别问我他们怎么用)。就商业而言,获得销售的实时信息,实际上可以引发配送中心更快地做出反应,向销售量最大的杂货店供应更多的这些商品。在这里,我说的不是在灾难发生的时候,甚至是灾难恢复,而是能够对市场需求做出更快的反应。在2019年,数据应该更多地被看作是一种流动,而不是被填充的孤岛。
在本章中,您将发现什么是流,以及它与批处理模式有何不同(如此之小)。然后,您将构建您的第一个流式应用。
为了让流媒体更容易模拟,我构建了一个流媒体数据生成器并添加到本章的源代码库中,它对模拟流媒体很有用。你可以根据自己的需要定制这个生成器。附录O涵盖了数据生成器的细节,它不是本章的先决条件。尽管如此,我们将在本章的实验室中使用该生成器。
从本章开始,例子和实验室将更多地使用日志记录,而不是简单的打印到屏幕上。日志可以简化阅读,而且是一种行业标准,这更符合日常工作中对你的期望(而println是一种不好的开发实践)。日志的设置仍然会将信息转储到控制台,不需要在一个不知名的地方寻找日志文件。
你还将实验一个更复杂的例子,你将用两个流来工作。最后,作为本章的总结,你将学习结构化流(从Apache Spark v2开始)和离散化流(从Apache Spark v1开始)之间的区别。附录P提供了关于流的额外资源。
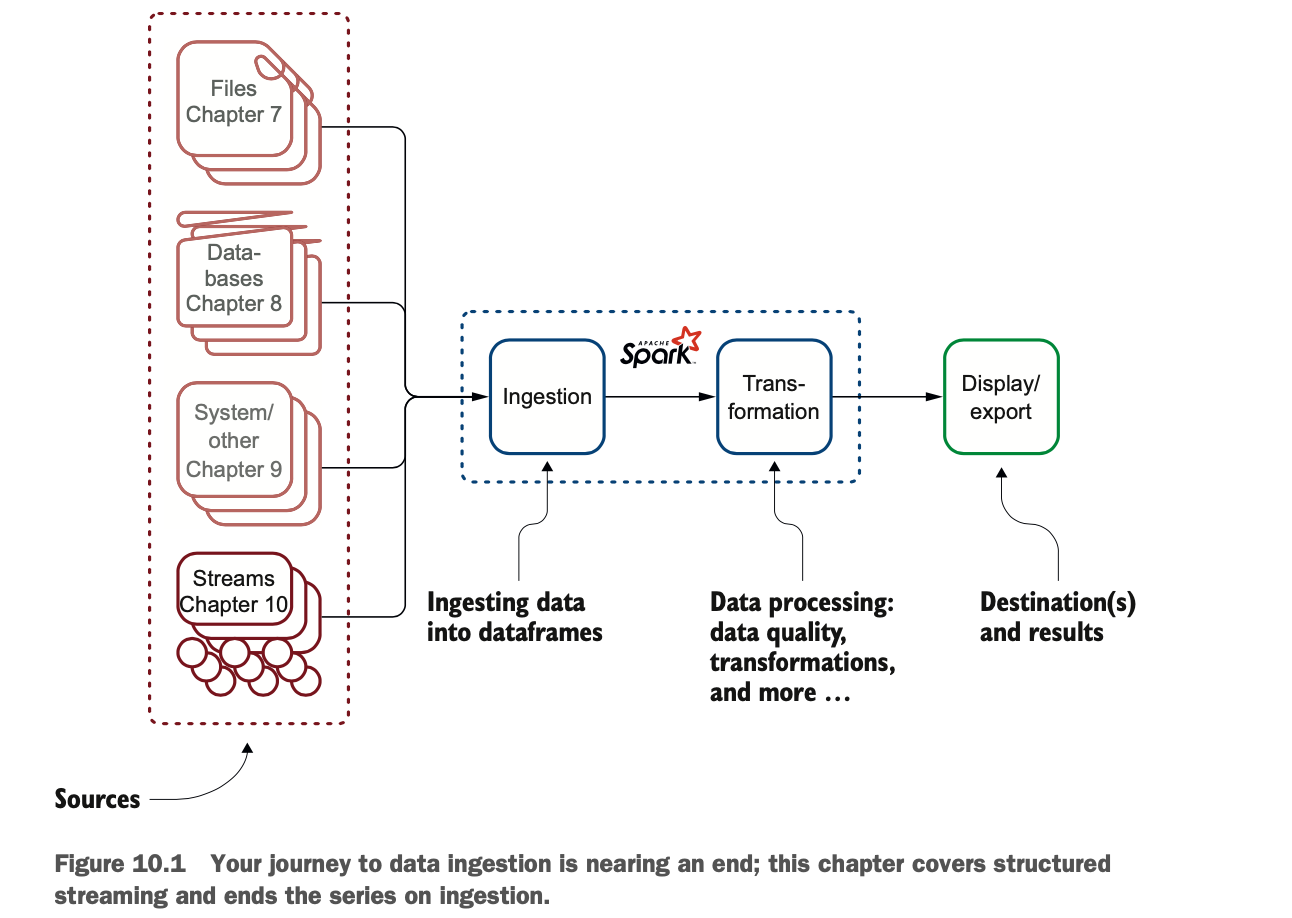
图10.1显示了你在Apache Spark中的摄取旅程中的位置。好消息!这是数据的最后一章。这是关于数据摄取的最后一章。
LAB 本章的例子可以在GitHub上找到:https://github.com/jgperrin/net.jgp.books.spark.ch10。附录L是摄取的参考资料。附录P还提供了关于流媒体的其他资源。
什么是流式计算?
在本节中,我们来看看Apache Spark背景下的流计算。这将为您提供所需的基础知识,以理解示例并将流计算集成到您的项目中。
通过流处理数据并不是一个新颖的想法。然而,近年来,它的普及程度越来越高。没有人愿意再等待任何事情。作为一个社会,我们已经成长为一直期待着立即的结果。你去看医生,你期望在回家时能在医疗服务提供者的门户网站上看到你的索赔。你把不小心买的电视退还给Costco,你希望马上看到信用卡账单上的信用额度。你坐完Lyft,你希望马上就能在网上看到你的SkyMiles奖励。在这个数据不断加速的世界里,流媒体绝对有它的用武之地:没有人愿意等待一夜之间的批量处理。
使用流式计算的另一个原因是,随着数据量的增加,将其切成小块以减少高峰期的负载也是一个不错的主意。
总的来说,流式计算比传统的批处理计算更自然,因为它是以流程的形式发生的。然而,由于它与你可能习惯的模式不同,你可能必须转变你的思维方式。图10.2说明了这个系统。
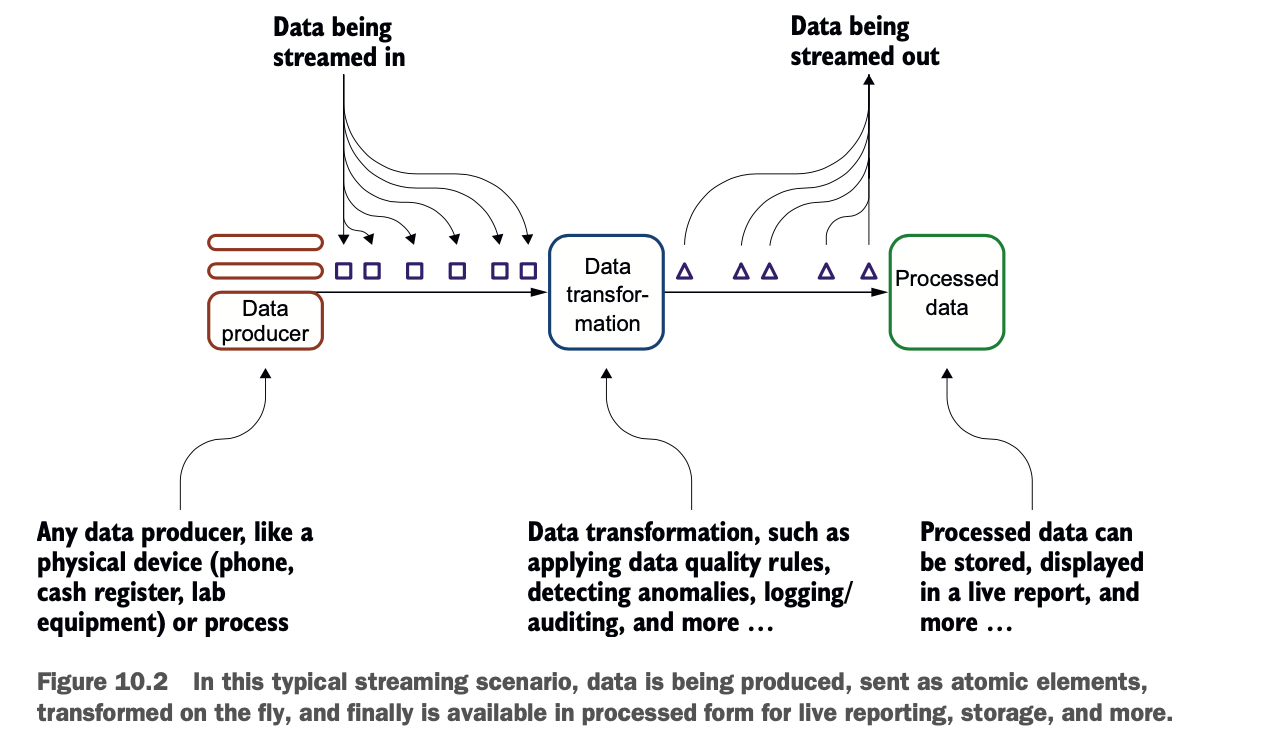 流通常有两种形式:文件和网络流。在文件流方案中,文件被丢在一个目录中(有时也被称为登陆区或暂存区,见第1章),Spark在文件进来时从这个目录中获取文件。在第二种情况下,数据是通过网络发送的。
流通常有两种形式:文件和网络流。在文件流方案中,文件被丢在一个目录中(有时也被称为登陆区或暂存区,见第1章),Spark在文件进来时从这个目录中获取文件。在第二种情况下,数据是通过网络发送的。
Apache Spark处理流的方式是通过在一个小的时间窗口中重新分组操作。这就是所谓的微批处理。
创建您的第一个流
对于您的第一个流摄取,您将使用文件。文件是在一个文件夹中生成的。Spark在它们生成时就会摄取它们。这个更简单的场景避免了处理潜在的网络问题,并将说明流的核心原则,即在数据可用时尽快消耗数据。
文件流是医疗行业的一个常见用例。医院(供应商)可以将文件转储到FTP服务器上,然后由保险公司(支付方)接收。
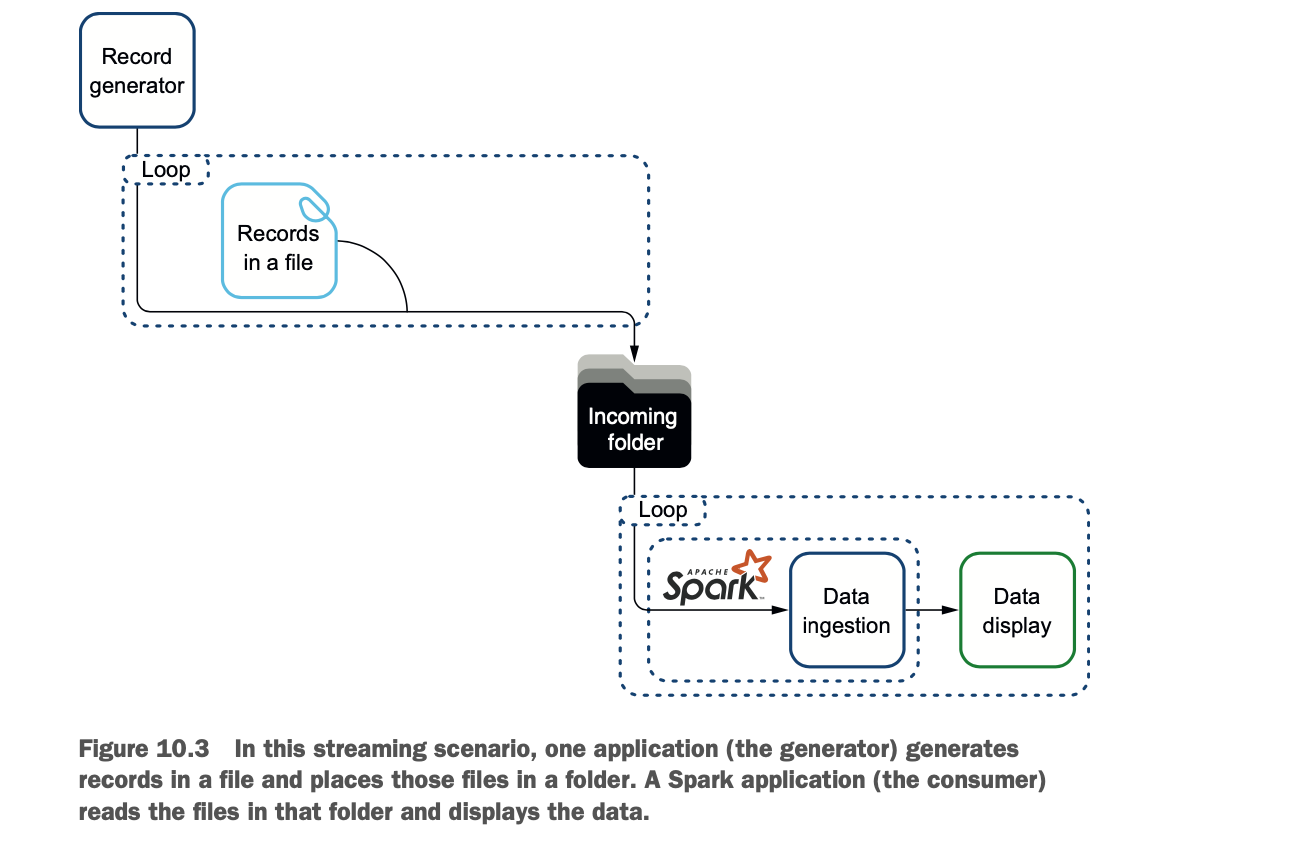
在这种情况下,你将运行两个应用程序。对于文件流来说,启动应用程序的顺序并不重要。一个应用程序将产生流,其中包含描述人的记录。另一个应用程序将使用Spark来消费生成的流。您将从数据生成器开始,然后构建消费者。图10.3说明了这个过程。
生成一个文件流
为了模拟一个稳定的数据流,你将首先启动记录生成器。在这一节中,你将看到生成器的输出,学习如何编译和运行它,然后简要地看一下它的代码。
为了让事情变得更简单,我在本章的资源库中添加了一个记录生成器。记录生成器被设计用来创建具有描述人的随机记录的文件:他们有一个名字、一个中间名、一个姓氏、一个年龄和一个美国社会安全号码。嘿,这是假数据,所以不要以为你可以用它来冒充任何人。
在本节中,你将运行生成器,但你不会对它进行过多的修改。附录O描述了如何修改生成器或基于生成器所建立的简易API建立你自己的生成器。
当运行时,RecordsInFilesGeneratorApp的输出看起来像下面的列表。


在Eclipse这样的IDE中,同时运行两个应用程序并不容易。因此,我确保你可以使用Maven从命令行中运行所有的实验。如果你对Maven不熟悉,附录B介绍了它的安装,附录H提供了一些使用技巧。
一旦你在本地克隆了资源库,就到存放项目pom.xml文件的文件夹中去。在本例中,它是这样的:
$ cd /Users/jgp/Workspaces/Books/net.jgp.books.spark.ch10然后清理和编译你的数据生成应用程序。一开始,你不会修改它,而只是编译和运行它。清理将确保不留下任何编译后的代码。第一次肯定不需要,因为没有什么可清理的。编译将简单地构建应用程序:
$ mvn clean install如果Maven开始下载大量软件包(或者不下载),不要惊慌失措,除非你是根据你消耗的数据量来支付你的互联网服务。然后运行这个:
$ mvn exec:java@generate-records-in-files这个命令将执行由 generate -records-in-files ID 定义的 pom.xml 文件中的应用程序,如清单 10.2 所摘录。本章的例子依靠你的pom.xml中的ID来区分不同的应用程序。当然,你也可以在你的IDE中运行所有的应用程序。
 下面列出了生成器的代码。附录O更详细地介绍了生成器、生成器的API以及其可扩展性:
下面列出了生成器的代码。附录O更详细地介绍了生成器、生成器的API以及其可扩展性:
 你可以修改参数(streamDuration、batchSize和waitTime)和记录的结构来研究各种行为。
你可以修改参数(streamDuration、batchSize和waitTime)和记录的结构来研究各种行为。
streamDuration定义了流的持续时间,单位是秒。默认值是60秒(1分钟)。
batchSize定义了单个事件中的最大记录数。默认值为10,意味着你最多会得到10条被生成器生成的记录。
waitTime是生成器在两个事件之间等待的时间。这个值有一定的随机性:默认值5毫秒意味着 应用程序将在2.5毫秒(= 5 / 2)和7.5毫秒(= 5 × 1.5)之间等待。
摄取记录
现在文件夹已经被文件中的记录填满了,你可以用Spark摄取它们。你首先要看一下记录的显示方式,然后再深入研究代码。
LAB 这是第200号实验室。它可以在GitHub上找到:https://github.com/jgperrin/net.jgp.books.spark.ch10。该应用程序是 net.jgp.books.spark.ch10.lab200_read_stream 包中的 ReadLinesFromFileStreamApp.java。
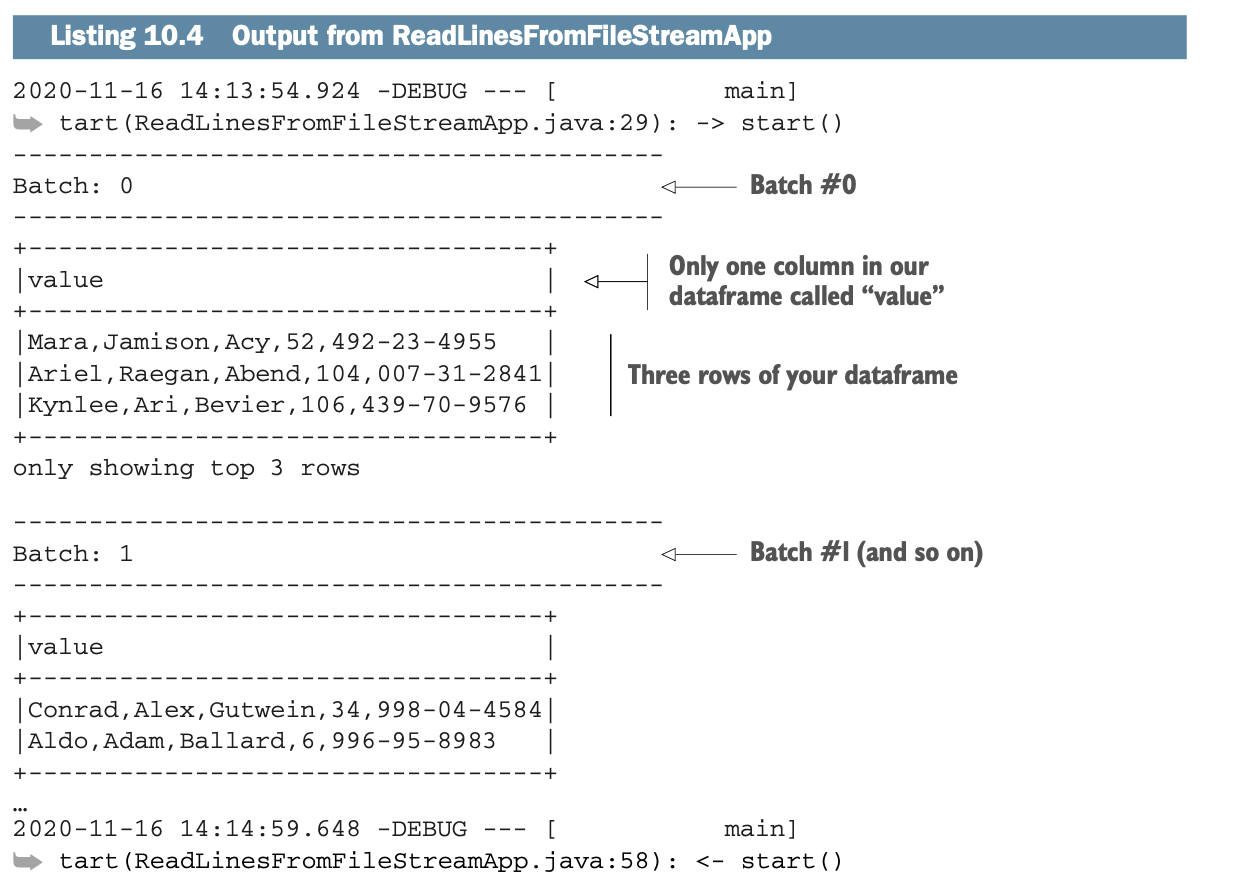
实验室将简单地摄取记录,把它们存储在一个DataFrame中(是的,就是你以前使用的那个DataFrame),并在控制台显示结果。图10.4说明了这个过程。
 下面的列表显示了应用程序的输出:
下面的列表显示了应用程序的输出:
 要启动摄取应用程序,你可以直接在IDE(此处为Eclipse)中运行,也可以通过Maven运行。在克隆项目的同一目录下,在另一个终端中,运行以下程序:
要启动摄取应用程序,你可以直接在IDE(此处为Eclipse)中运行,也可以通过Maven运行。在克隆项目的同一目录下,在另一个终端中,运行以下程序:
$ cd /Users/jgp/Workspaces/Book/net.jgp.books.spark.ch10
$ mvn clean install
$ mvn exec:exec@lab200注意,这里你使用的是exec:exec,而不是exec:java。通过使用exec:exec,Maven启动了一个新的JVM来运行你的应用程序。这样,你就可以向JVM传递参数。下面的列表显示了pom.xml中负责执行应用程序的部分。

 让我们分析一下列表10.6中net.jgp.books.spark.ch10.lab200_read_stream包中的ReadLinesFromFileStreamApp应用程序的代码。我知道在源代码的开头有这么大块的导入并不总是吸引人,但是随着底层框架(这里是Apache Spark)的各种演变,我想确保你将使用正确的包。
让我们分析一下列表10.6中net.jgp.books.spark.ch10.lab200_read_stream包中的ReadLinesFromFileStreamApp应用程序的代码。我知道在源代码的开头有这么大块的导入并不总是吸引人,但是随着底层框架(这里是Apache Spark)的各种演变,我想确保你将使用正确的包。
从本书的这一点来看,我将使用日志(SLF4J包)而不是println。日志是一个行业标准,而println可能会吓到我们中的一些人(如把你不希望用户看到的信息显示在控制台)。为了保持代码的清晰性,我不会在每个实验室中描述日志的初始化,而在书中描述它。然而,在资源库中,你会发现每个例子的初始化(否则,它将无法工作,对吗?)
无论你打算使用stream还是批处理数据,在创建Spark会话方面都没有什么不同。
一旦你有了会话,你可以通过使用readStream()方法要求会话从流中读取数据。基于流的类型,它将需要额外的参数。这里你正在从一个目录(由load()方法定义)中读取一个文本文件(如用format()方法指定)。请注意,format()的参数是一个字符串值,而不是一个枚举值,但没有什么禁止你在某个地方有一个小的实用类(例如,有常量)。
到目前为止,这是很容易的,不是吗?你启动一个会话,为了建立一个DataFrame,你从一个流中读取它。然而,在一个流中,数据可能在那里,也可能不在那里,也可能不来了。因此,应用程序需要等待数据的到来,有点像一个服务器在等待请求。写入数据是通过数据框架的writeStream()方法和StreamingQuery对象完成的。
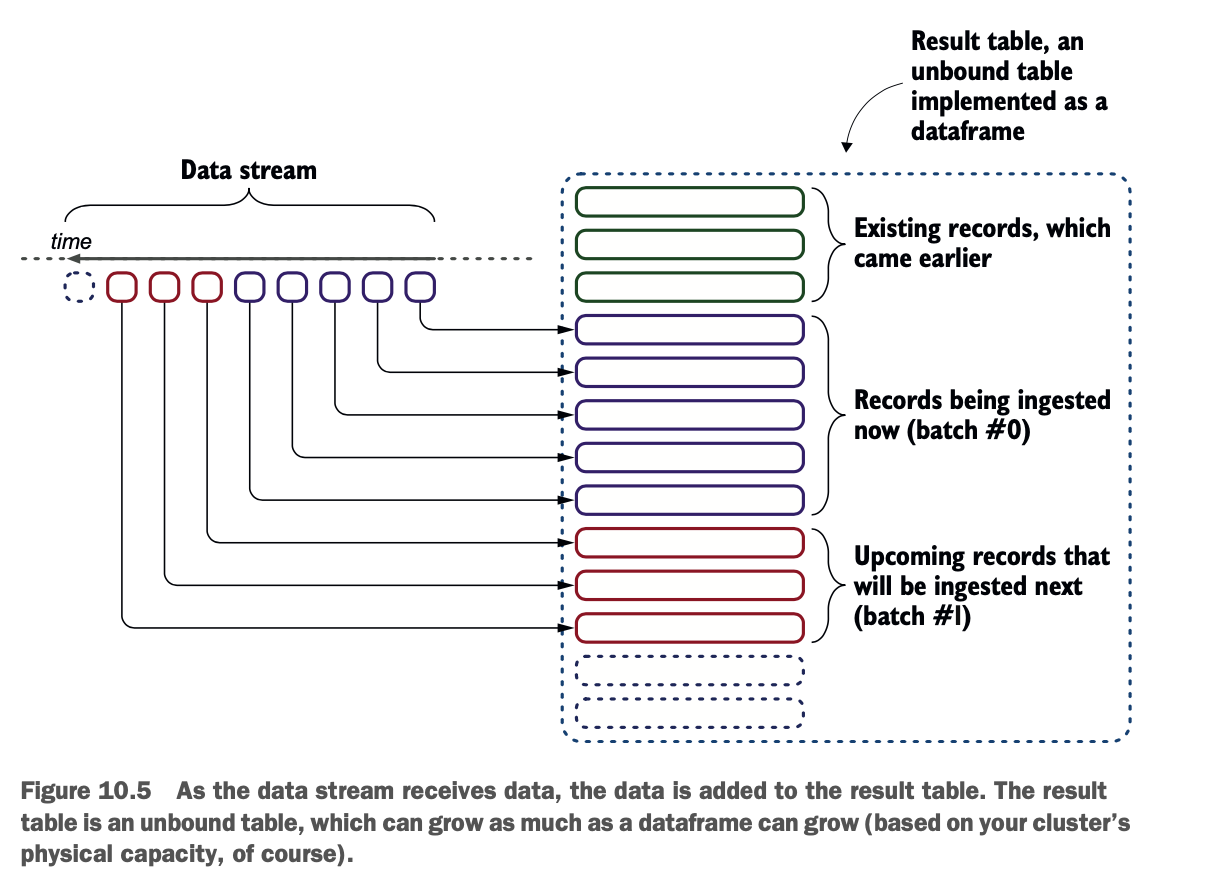
你首先从你用作流的DataFrame定义你的流式查询对象。该查询将开始填充一个结果表,如图10.5所示。结果表会随着数据的进入而增长。
为了建立你的查询,你将需要指定以下内容:
输出模式(见附录P中的输出模式列表)。在这个实验室中,你只显示两个接收之间的更新。
格式,基本上说的是你要对收到的数据做什么。在这个实验室中,你要在控制台中显示它(而不是通过日志记录)。在文献中,当提到输出格式时,你经常会读到sink的内容。你也可以参考附录P,了解不同的汇和它们的描述。
选项。在向控制台显示的情况下,truncate设置为false意味着记录不会被截断到一定的长度,numRows指定你将最多显示三条记录。这相当于在非流式(批处理)模式下对一个数据帧调用show(3, false)。
 在指定了输出模式、格式和选项之后,你就可以开始查询了。
在指定了输出模式、格式和选项之后,你就可以开始查询了。
当然,现在,你的应用程序需要等待数据的到来。它通过查询的awaitTermination()方法来实现。它可以带或不带参数。没有参数,该方法将永远等待。有了参数,你可以指定方法等待的时间。在这些实验中,我一直使用一分钟。
你已经实现了从流中的第一次摄取。在下一节中,你将 从流中提取一条完整的记录,而不仅仅是一条原始的数据线。


请注意,在Spark v3.0预览版2中,来自StreamingQuery的start()现在抛出了一个超时异常,这需要做异常处理。
获取记录,而不是行
在前面的例子中,你摄取了行,如Conrad,Alex,Gutwein,34,998-04-4584。虽然数据是在Spark中,但使用起来并不方便。它是原始的,你将不得不重新解析它,没有数据类型。. . . 让我们通过使用一个模式将原始行变成一个记录。
LAB 这是 net.jgp.books.spark.ch10.lab210_read_record fromstream 包中的 lab#210。该应用程序是 ReadRecordFromFileStreamApp。
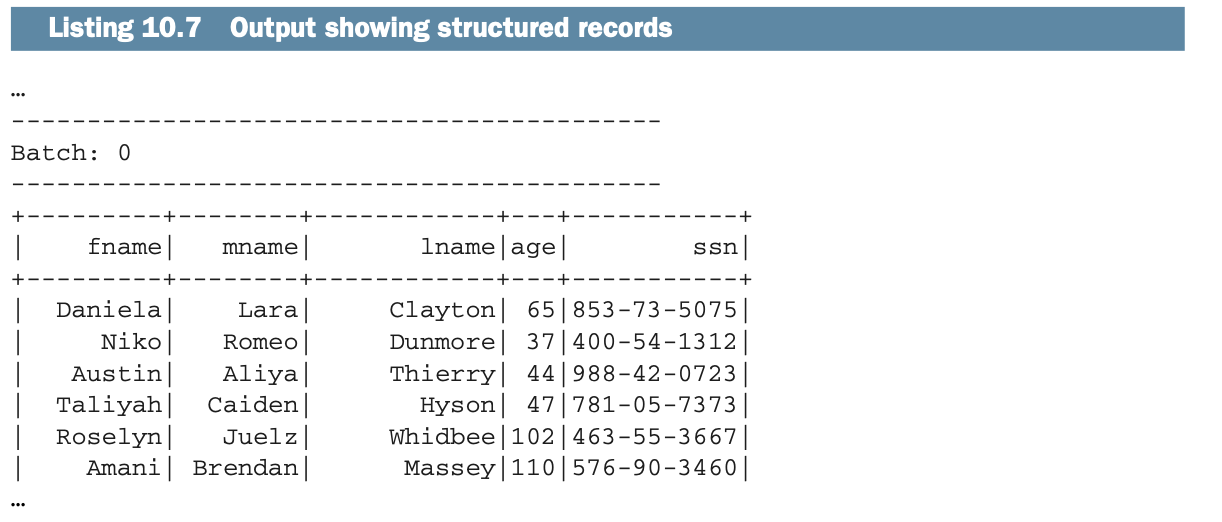
下面的列表显示了ReadRecordFromFileStreamApp的输出。该输出有明显的分离记录。获得这样的输出是相当容易的。
 你可以直接在Eclipse(或你喜欢的IDE)中执行这个实验,也可以通过以下方式在命令行中执行。
你可以直接在Eclipse(或你喜欢的IDE)中执行这个实验,也可以通过以下方式在命令行中执行。
$ mvn clean compile install
$ mvn exec:exec@lab210列表10.8中显示的记录摄取应用程序,与列表10.5中的原始行摄取应用程序有些不同。你必须告诉Spark你想要记录并指定Schema。

 该模式必须与你用于生成器的模式相匹配,当然也可以是你系统中的真实Schema。
该模式必须与你用于生成器的模式相匹配,当然也可以是你系统中的真实Schema。
从网络流中摄取数据
数据也可能以网络流的形式出现。Spark的结构化流媒体可以像处理文件流一样轻松地处理网络流,正如你在上一节中读到的。在这一节中,你将通过网络,启动应用程序。
LAB 这是第300号实验室。它可以在GitHub上找到:https://github.com/jgperrin/net.jgp.books.spark.ch10。该应用程序是 net.jgp.books.spark.ch10.lab300_read_network_stream 包中的 ReadLinesFromNetworkStreamApp。
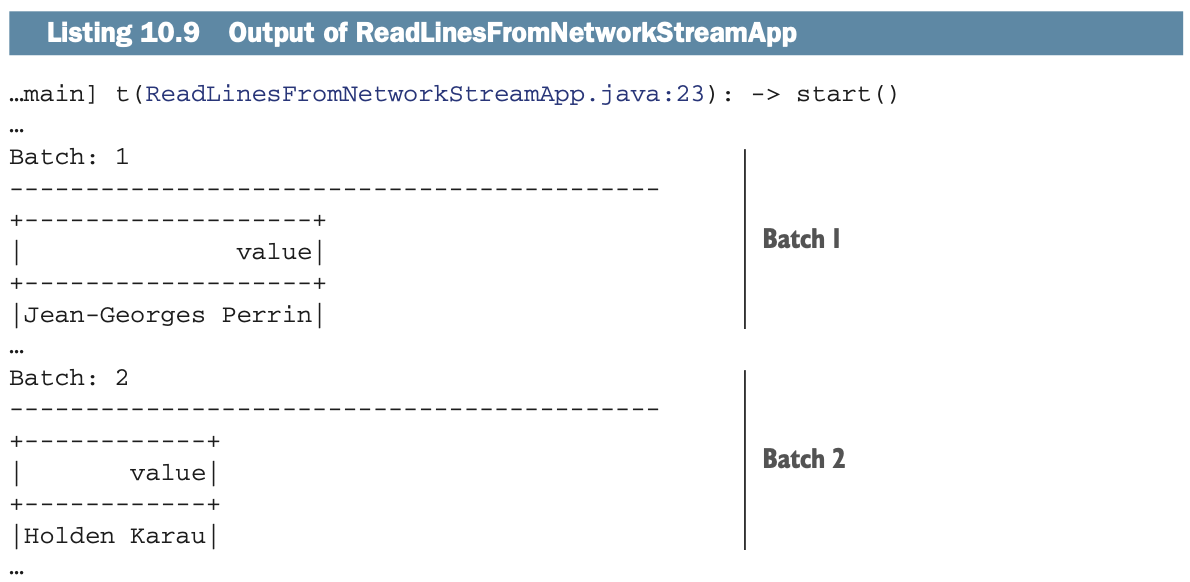
实验程序将在收到结果时在流上显示,如以下列表所示。在处理结束时,你可以看到查询的一个小状态。
 要建立网络流,你将需要一个叫NetCat(或nc)的小工具,它随任何UNIX(包括macOS)发行版一起提供。如果你运行的是Windows,如果nc.exe不是系统的一部分,可以考虑看看https://nmap.org/ncat/。
要建立网络流,你将需要一个叫NetCat(或nc)的小工具,它随任何UNIX(包括macOS)发行版一起提供。如果你运行的是Windows,如果nc.exe不是系统的一部分,可以考虑看看https://nmap.org/ncat/。
nc是一个操纵TCP和UDP的多功能工具。它经常被描述为网络工具中的瑞士军刀。为了你的心理健康,我不会介绍该工具的所有选项。你将在9999端口启动nc作为一个服务器。
你需要在启动其他东西之前启动nc。要做到这一点,只需输入以下内容。
$ nc -lk 9999-l选项指定nc应该监听,而-k表示你可以有更多的连接。
一旦nc运行,你就可以启动你的Spark应用程序。一个常见的错误是在启动nc之前启动Spark。你可以用mvn exec:exec@lab300来运行它。
在你启动了Spark应用程序后,你可以回到运行nc的终端,开始在终端窗口中输入。如果你想得到与列表10.9相同的显示,你将不得不输入Jean-Georges Perrin, Holden Karau, 和Matei Zaharia(但我相信你已经明白了)。下面的列表显示了代码。

 正如你所看到的,你不需要从本章的第一个例子(清单10.5)中修改太多;你只需要指定格式、主机和端口。
正如你所看到的,你不需要从本章的第一个例子(清单10.5)中修改太多;你只需要指定格式、主机和端口。
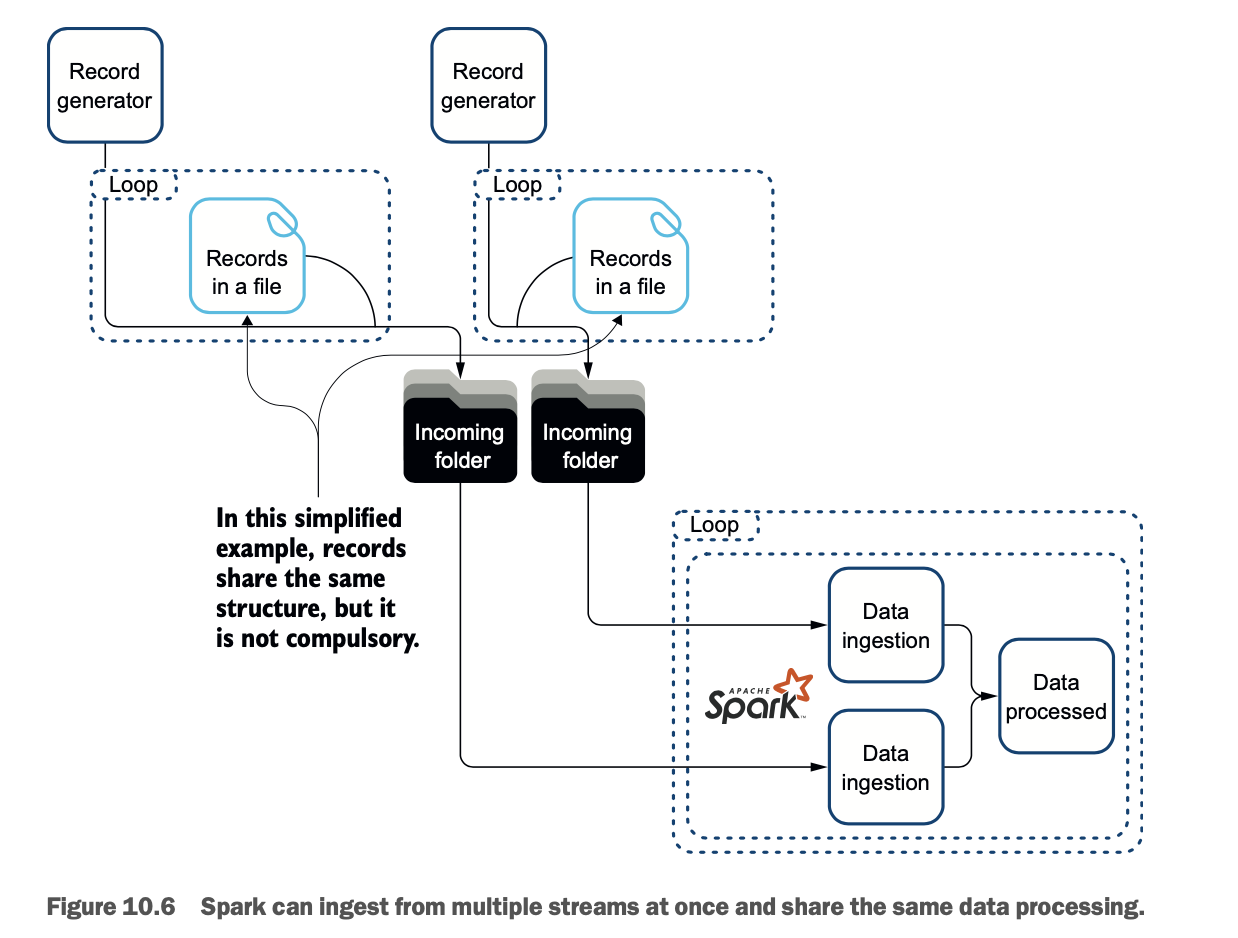
处理多个数据流
当然,在现实生活中,你永远不会像前几节那样只有一个数据流进来,对吗?本节将向你展示如何使用同时到来的两个数据流。
LAB 本实验室使用 net.jgp.books.spark.ch10.lab400_read_records_from_multiple_streams 包中的 ReadRecordFromMultipleFileStreamApp。这是第400号实验室。
在这个例子中,数据将来自两个目录的两个流。为了简化,这两个数据流包含相同的记录。同一个处理器接收每个数据流并处理每个记录。该操作是对儿童、青少年和老年人之间的人口进行简单的分割。图10.6说明了这个过程。
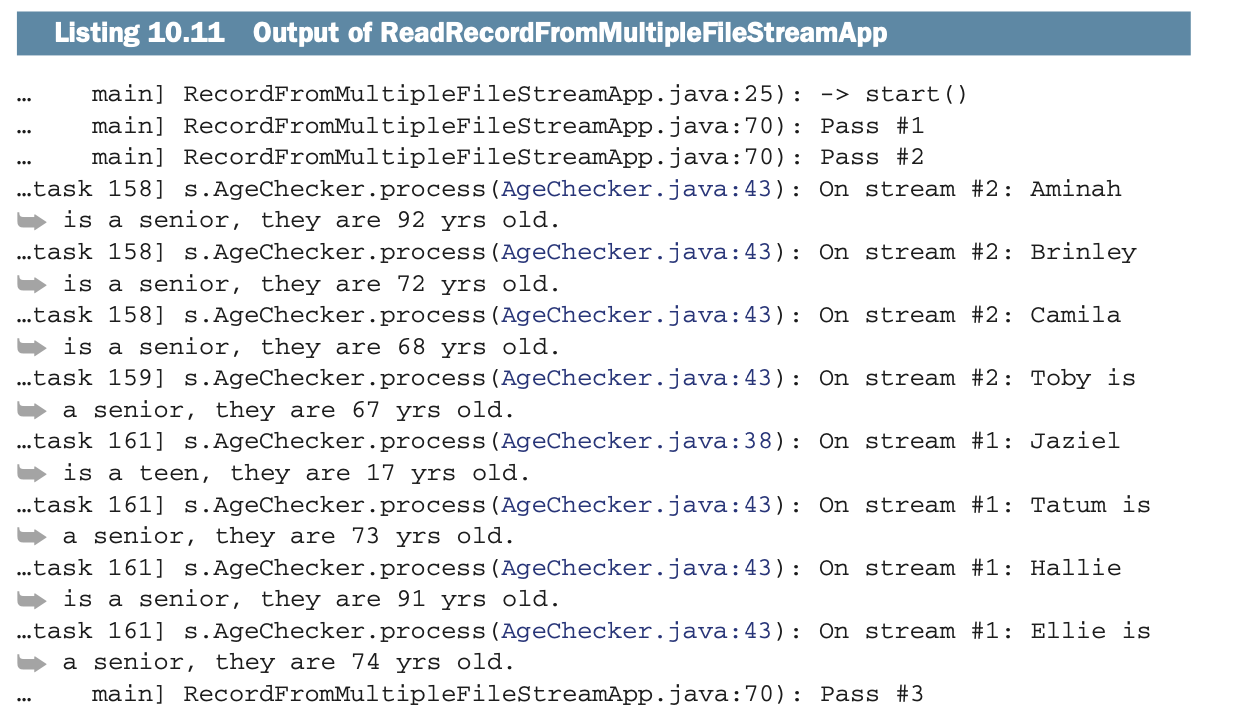
 输出看起来像下面的列表:
输出看起来像下面的列表:
 让我们专注于一个日志行,以充分了解发生了什么事。你可能知道Log4j是如何工作的,但由于每个人都会对它进行一些定制,我想确保你会对我使用的格式感到满意。我把一个日志条目分成几行。
让我们专注于一个日志行,以充分了解发生了什么事。你可能知道Log4j是如何工作的,但由于每个人都会对它进行一些定制,我想确保你会对我使用的格式感到满意。我把一个日志条目分成几行。
 正如你从清单10.11的输出中看到的,几个线程同时活动,并行处理数据:被称为main的线程是驱动,任务158、159、161和163负责处理。结果在你的系统上会有所不同,但你可以分析这些,看看Spark启动了多少个任务。你不能控制线程的数量。
正如你从清单10.11的输出中看到的,几个线程同时活动,并行处理数据:被称为main的线程是驱动,任务158、159、161和163负责处理。结果在你的系统上会有所不同,但你可以分析这些,看看Spark启动了多少个任务。你不能控制线程的数量。
让我们看一下下面列表中的代码:


 Spark将加载出现在两个目录中的数据,并要求AgeChecker类来处理每一行。
Spark将加载出现在两个目录中的数据,并要求AgeChecker类来处理每一行。
接下来的列表显示了AgeChecker类。它是一个相当简单的类,继承了ForeachWriter<Row>。在这个实验室中,需要理解的关键方法是process(),它接收要处理的数据帧的单行或记录。

 为了运行这个应用程序,你需要同时在两个独立的终端中,运行每个生成器。你也可以在你的IDE中运行每个应用程序,但我真的建议在终端中运行,因为你的输出可能很乱,在IDE中很难阅读。
为了运行这个应用程序,你需要同时在两个独立的终端中,运行每个生成器。你也可以在你的IDE中运行每个应用程序,但我真的建议在终端中运行,因为你的输出可能很乱,在IDE中很难阅读。
在第一个终端中,运行这个:
$ mvn install exec:java@generate-records-in-files-alt-dir在第二个终端窗口中,运行与本章第10.2.1小节第一个例子中使用的完全相同的生成器:
$ mvn install exec:java@generate-records-in-files你现在可以启动你的Spark应用程序。你启动应用程序的顺序并不重要。然而,每个程序将只运行一分钟。你也可以通过mvn clean exec:exec@lab400来运行该实验室。
与本章以前的例子相比,注意你不再使用awaitTermination();它是一个阻塞操作。你将使用一个循环来检查流是否处于活动状态,使用isActive()方法。
区分离散化和结构化Stream
Spark提供了两种流媒体的方式。在本章中,你已经发现了结构化流。然而,Spark一开始就提供了另一种类型的流,叫做离散化流(或称DSream)。
简而言之,Spark v1.x使用了离散化流,它依赖于RDDs。然而,Spark v2.x现在专注于数据框架(见第三章)。对Stream API进行演进,使其也遵循DataFrame,是有意义的。这种转换极大地提高了性能。
结构化的Stream肯定是要走的路,因为这个API会随着时间的推移而增强。预计DStream API将停滞不前或在某个时候被淘汰。
结构化流在Spark v2.1.0中以alpha状态引入。从Spark v2.2.0开始,结构化Stream被认为是可以投入生产的。
关于离散化流的更多信息,请查看http://mng.bz/XplE。关于结构化流的更多信息,请查阅http://mng.bz/yzje。
摘要
无论你是在批处理还是流模式下,启动一个Spark会话都是一样的。
流式处理是一种不同于批处理的模式。一种看待流的方式,特别是在Spark中,是作为微批处理。
你通过使用readStream()方法和start()方法在数据帧上定义一个流。
你可以通过使用format()来指定摄取格式,并通过使用option()来指定选项。
流式查询对象,StreamingQuery,将帮助你查询流。
查询中数据的目的地被称为sink。它可以通过使用format()方法或forEach()方法来指定。
流的数据被存储在一个结果表中。
为了等待数据的到来,你可以使用awaitTermination(),它是一个阻塞方法,或者通过使用isActive()方法来检查查询是否处于活动状态。
你可以同时从多个数据流中读取数据。
forEach()方法将需要一个自定义写入器,让你以分布式方式处理记录。
Spark v1.x中的流被称为离散化流。