结构化查询语言(SQL)是操作数据的黄金标准。它于1974年被引入,此后发展成为ISO标准(ISO/IEC 9075)。最新的修订是SQL:2016。
作为在关系型数据库中提取和操作数据的一种方式,SQL似乎一直存在。而且SQL将永远存在。当我在大学时,我清楚地记得问我的数据库教授:"你期望谁会使用SQL?一个做报告的秘书吗?" 他的回答很简单,"是的"。基于这个答案,我可能只是认为你是一个想要使用Spark的秘书)。
当几个月后,我在Oracle Pro*C中使用SQL时,我意识到SQL正在成为一个强大的工具。Pro*C是一种嵌入式SQL编程语言,允许你将SQL嵌入到你的C应用程序中。快进到最近的技术,如Java和JDBC,你仍然可以考虑到SQL的巨大存在。SQL仍然在填充你的JDBC记录集。
基于SQL的流行和广泛使用,在Spark中嵌入SQL是完全有意义的,特别是因为你正在操作结构化和半结构化的数据。在本章中,你将在Spark和Java中使用SQL。我不会教授SQL;如果你的SQL有点生疏,你仍然能够跟随这些例子。
你将首先在Spark中操作一个SELECT语句。你将决定全局或局部视图的范围。你将同时混合使用SQL和数据框架API。在这之后,你将看到你如何在一个不可变的上下文中DROP/DELETE数据。最后,我将分享一些外部资源来帮助你更进一步。
LAB 本章的例子可以在GitHub上找到,网址是https://github.com/jgperrin/net.jgp.books.spark.ch11。
使用Spark SQL工作
在本节中,您将发现如何在您的应用程序中直接使用SQL。Spark的SQL是基于标准SQL的。您将执行一个简单的SELECT语句,其中包括基本的WHERE、ORDER BY和LIMIT子句。
在关系型数据库中,视图驻留在数据库中,而你的应用程序代码会调用该视图。在这种情况下,视图是一个代表数据框架的逻辑结构。当你想在Spark中使用SQL时,需要记住的诀窍是,你需要定义一个视图,而视图就是你要查询的元素。让我们看这一个例子。
在这个例子中,你要对世界上的国家进行一些分析操作。为了帮助你完成这个任务,你将使用一个数据集,其中包含1980年到2010年按领土(国家、大陆和一些国家的细分)划分的世界人口。该数据集来自美国能源部,可以从https://openei.org/doe-opendata/dataset/population-by-country-1980-2010 或 https://catalog.data.gov/dataset/population-by-country-1980-2010。
包含该数据的文件是populationbycountry19802010millions.csv,可在本章项目的数据目录中找到。它由第一个未命名的列和1980至2010年每年的31个列组成。人口的数值以百万为单位。下面的列表显示了该文件前15行的摘要。

 我尽可能多地看数据的摘要,甚至在摄取之前。当你看清单11.1时,你可以看到以下情况:
我尽可能多地看数据的摘要,甚至在摄取之前。当你看清单11.1时,你可以看到以下情况:
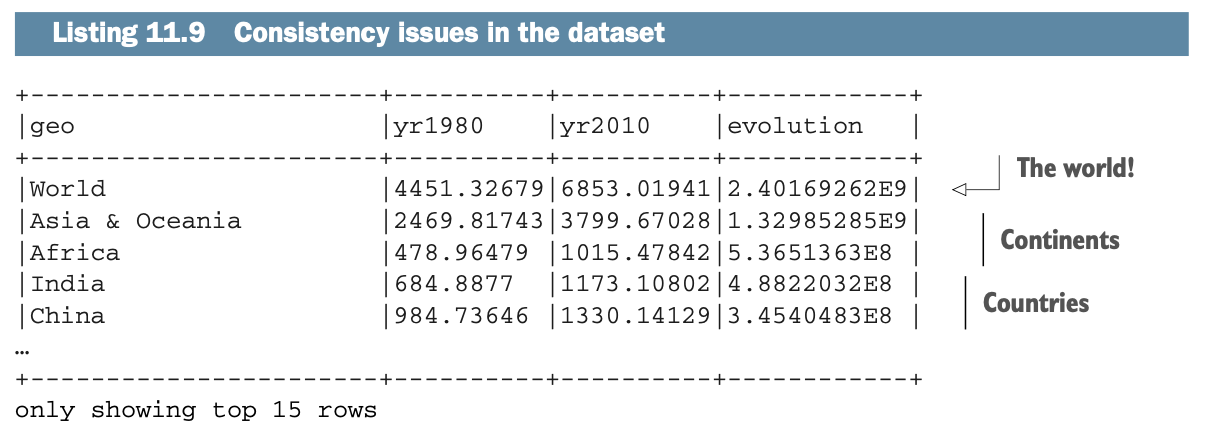
即使数据集被称为国家,它也混合了大洲(例如北美)、领土(例如圣皮埃尔和密克隆,一个法国领土,战略性地放在加拿大前面)和国家(例如墨西哥、加拿大和美国)。
数据并不总是一致的。当南极洲,和或阿鲁巴的数据不可用时,你会看到NA。
巴哈马是在引号中,因为使用了逗号。
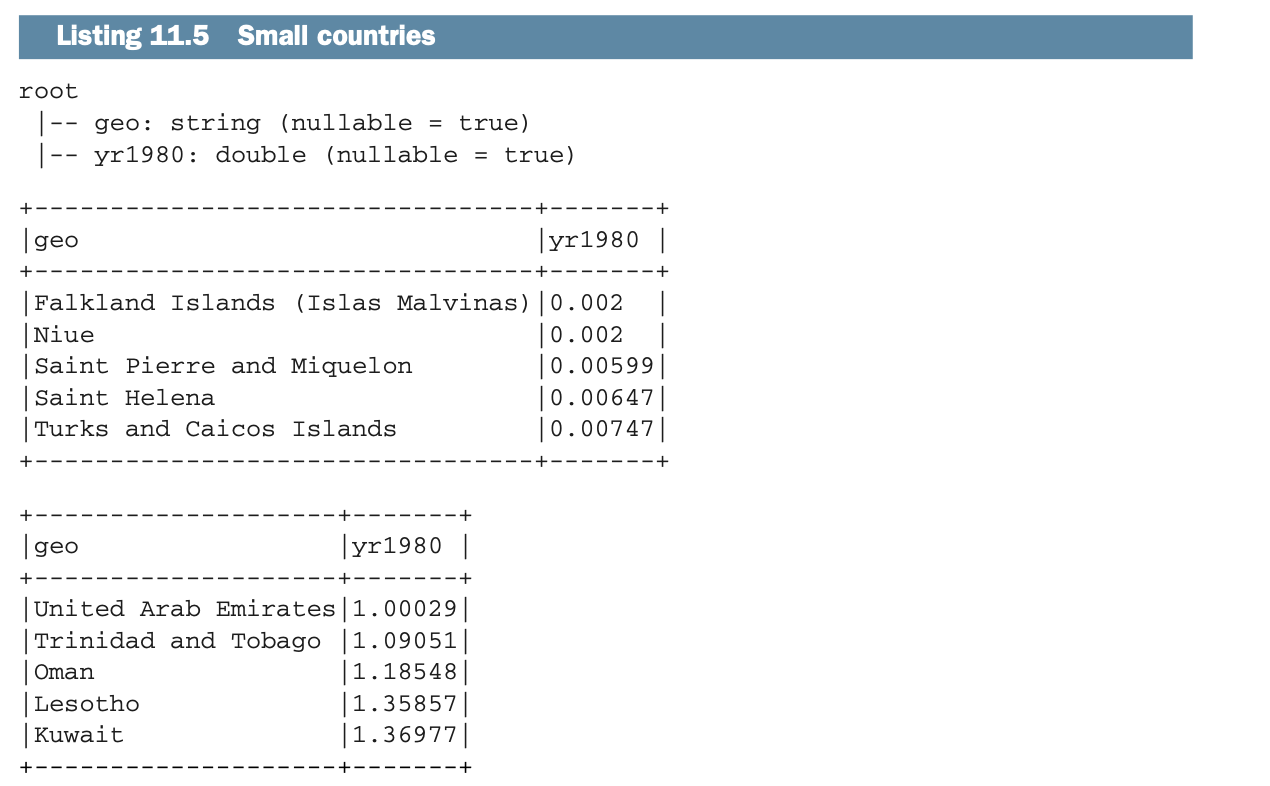
图11.1说明了你将要使用的视图。让我们在下面的列表中按升序显示截至1980年人口低于100万的五个最小的地区。

 在你钻研代码之前,先想一想为了得到这样的结果你会产生什么样的SQL。你有一个表或视图(让我们称之为geodata)和两列(geo和yr1980)。为了得到人口在100万以下的前五个最小的地区,你会同意我的以下SQL语句吗?
在你钻研代码之前,先想一想为了得到这样的结果你会产生什么样的SQL。你有一个表或视图(让我们称之为geodata)和两列(geo和yr1980)。为了得到人口在100万以下的前五个最小的地区,你会同意我的以下SQL语句吗?
SELECT * FROM geodata WHERE yr1980 < 1 ORDER BY 2 LIMIT 5请注意,这个SQL例子不一定能在所有的数据库上工作。最近的Oracle数据库将使用FIRST_ROWS,而Informix(在12.1版之前)将使用FIRST。如果你的SQL技能有点生疏,下面的列表为你分割了行动。

哪种味道的SQL?
如你所知,尽管有规范化的努力,每个数据库供应商在SQL规范方面都有细微的差异。Apache Spark也不例外。它是基于Apache Hive的SQL语法(http://mng.bz/ad2X),但有一些限制。Apache Hive的SQL,或HiveQL,是基于SQL-92的。
到现在为止,还没有官方的Apache Spark SQL参考手册。
让我们看看当我们必须在Spark中使用这个查询时会发生什么,如列表11.4中所示。在这个例子中,有什么值得注意的?你正使用一个Schema摄取一个文件,就像在第7章中一样。尽管文件中有很多列,但Schema只定义了前两列;这将给Spark一个提示,让它放弃其他列。
为了在Spark中实现类似表的SQL用法,你必须创建一个视图。范围可以是本地的(对会话),就像你刚才做的那样,或者是全局的(对应用程序)。你可以在下一节中找到更多关于本地范围和全局范围的细节。
注意,在这个实验室中,数据将被加载到Spark中,然后你将限制查询所显示的数据。

 创建一个本地临时视图是相当简单的:使用Dataframe中createOrReplaceTempView()的方法。参数将是你的表/视图名称。正如我前面所说,你可以使用geodata(或任何你喜欢的东西)。
创建一个本地临时视图是相当简单的:使用Dataframe中createOrReplaceTempView()的方法。参数将是你的表/视图名称。正如我前面所说,你可以使用geodata(或任何你喜欢的东西)。
你的下一个操作是使用Spark会话的sql()方法。在那里你可以使用你在清单11.3中设计的相同的SQL语句。不需要修改。结果是以Dataframe的形式出现的,所以你可以使用show()方法进行调试,也可以使用其他API。
在下一节中,你将了解一些关于本地和全局视图的区别。
本地视图和全局视图的区别
在上一节中,你针对一个本地视图运行了你的第一个Spark语句。Spark也提供全局视图。让我们来看看有什么区别。
LAB 反映本节内容的实验室(实验室#200)名为SimpleSelectGlobalViewApp,位于net.jgp.books.spark.ch11.lab200_simple_select globalview包中。
接下来的列表说明了你想要的结果:显示居民少于100万的五个最小的地区(如上一节)。你还将显示居民人数超过100万的五个最小的地区。
 无论你使用的是本地视图还是全局视图,视图都只是临时的(临时使用)。当会话结束时,本地视图被删除;当所有会话结束时,全局视图被删除。
无论你使用的是本地视图还是全局视图,视图都只是临时的(临时使用)。当会话结束时,本地视图被删除;当所有会话结束时,全局视图被删除。
列表11.6中代码的第一部分与列表11.4相似。你打开一个会话并摄入文件,但是当需要创建视图时,你将调用Dataframe的createOrReplaceGlobalTempView()方法(而不是createOrReplaceTempView())。当你在SQL语句中使用视图时,你将不得不在表名前加上global_temp表空间,因为你是在全局空间。在这种情况下,这意味着你将使用 global_temp.geodata。
图11.2显示了该视图是一个全局视图。
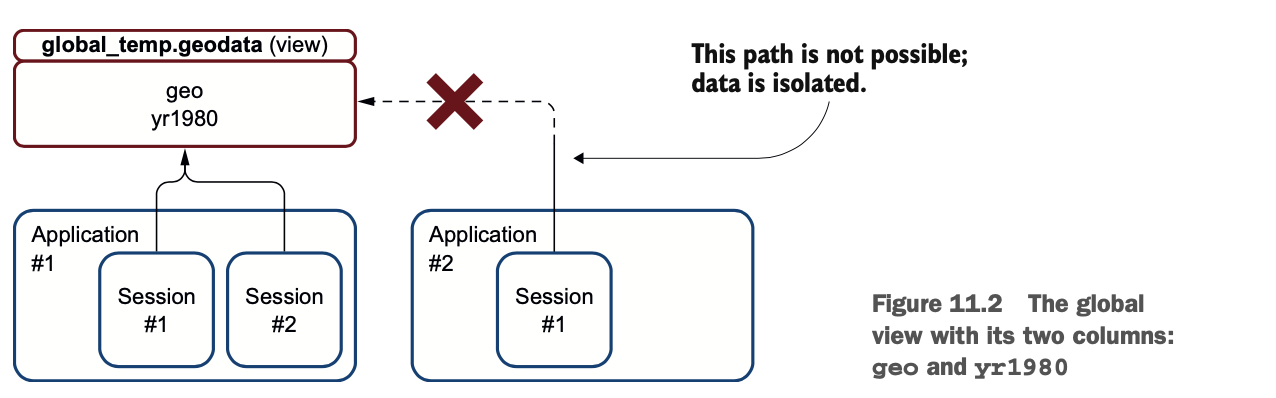
 当你创建一个新的会话时,你的数据在两个会话中仍然可用,这时你可以使用全局视图。
当你创建一个新的会话时,你的数据在两个会话中仍然可用,这时你可以使用全局视图。
为什么你需要多个Spark会话?
当你用newSession()启动一个新的会话时,你将得到独立的SQL配置、临时表和注册函数。你仍然会共享底层的SparkContext和缓存数据。
用例可以是增加数据的隔离,进程的隔离,在Spark前面有一个服务器为不同的用户处理不同的请求,特定的会话调整,等等。不用说,运行多个会话并不是一个常见的情况。
混合使用Dataframe的API和Spark SQL
在前面的章节中,你看到了如何将SQL与Dataframe一起使用。现在,你不必妥协,可以很容易地结合SQL和数据框架API,以建立更强大的应用程序。
LAB 反映本节内容的实验室(lab # 300)名为SqlAndApiApp,位于net.jgp.books.spark.ch11.lab300SqlAndApi包中。
在这个实验室中,你将通过使用Dataframe API来准备数据,你在以前的例子中看到过,并将在第12章中看到更多信息。然后,你将应用SQL查询来做一些基本分析。
你会发现在1980年至2010年期间,哪些国家的人口流失最多。
你会发现同期领土的最高增长。
输出结果类似于以下列表。
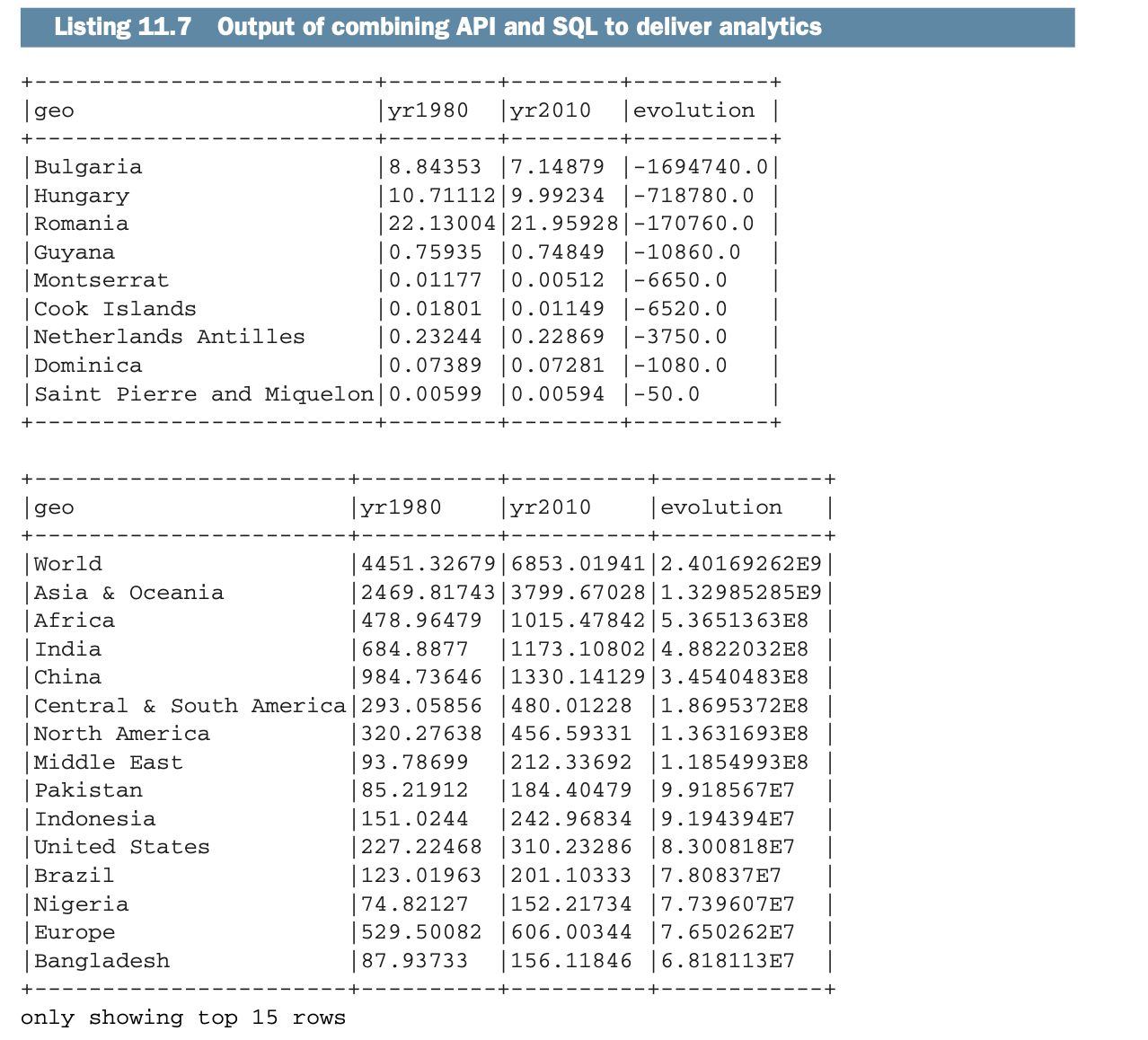
让我们看看,作为一个数据工程师,你如何提取这些结果,并使用Spark把它们交给分析师(甚至是政治分析师)。在下面的列表中说明了API和SQL的结合过程。


 该应用程序使用Dataframe API删除了一些我们不需要的列(1981年至2009年的所有列,因为我们关注的是1980年和2010年)。然后,它再一次使用Dataframe API创建一个新的列,显示1980年至2010年之间的人口变化。
该应用程序使用Dataframe API删除了一些我们不需要的列(1981年至2009年的所有列,因为我们关注的是1980年和2010年)。然后,它再一次使用Dataframe API创建一个新的列,显示1980年至2010年之间的人口变化。
在这个阶段,你有一个经过清理和格式化的数据集。你可以通过使用SQL查询并显示结果。
不要DELETE它!
当你与数据和SQL打交道时,不仅要对它们进行SELECT,也要对它们进行DELETE。基本上,你可以参考CRUD(创建、读取、更新和删除)的首字母缩写,用于所有数据操作。本节涉及删除数据框中的数据。
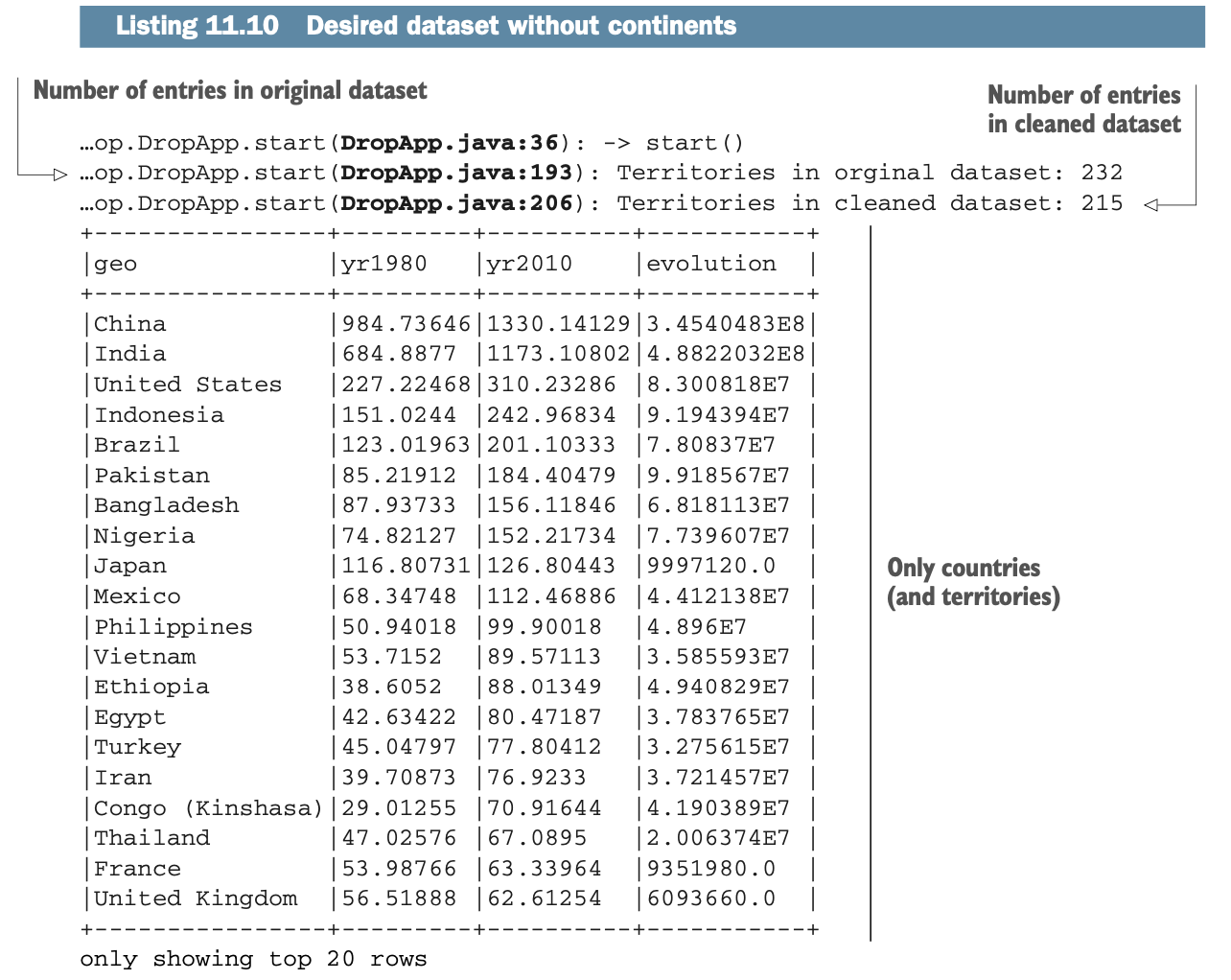
在前面的章节中,你使用了美国能源部的地理数据。该数据集混合了国家、地方领土、大陆和世界,所以它对分析来说并不完美。前一个实验室的输出(清单11.7,这里部分复制为清单11.9)说明了这种情况。
 正如你在第三章中读到的,Spark中的Dataframe是不可变的;数据不会改变。如果你没有准确记住所有的细微之处,那也没关系;数据不会改变;Spark会记录数据的变化,就像烹饪食谱一样,并将其存储在一个有向无环图(DAG)中,正如你在第四章中读到的那样。
正如你在第三章中读到的,Spark中的Dataframe是不可变的;数据不会改变。如果你没有准确记住所有的细微之处,那也没关系;数据不会改变;Spark会记录数据的变化,就像烹饪食谱一样,并将其存储在一个有向无环图(DAG)中,正如你在第四章中读到的那样。
那么,如果数据是不可变的,你怎么能改变一个Dataframe呢?你当然不能使用DELETE SQL语句;你不能修改数据(它是不可变的!)。下面的列表说明了你想要的东西:一个经过清理的数据集,它只包括国家和地区,没有大陆。
 方法很简单:你要创建一个新的Datafrmae,不包括你不想要的数据。
方法很简单:你要创建一个新的Datafrmae,不包括你不想要的数据。
LAB 基于11.3节的实验,你可以看看net.jgp.books.spark.ch11_lab400_delete包中的实验#400,DeleteApp。
清单11.11着重于前一个实验室(#300)的变化。当你想删除这些行时,下面是发生的情况:
正如你在前面的例子中所做的那样,你在第一个Dataframe中加载/测试数据(在清单11.10中没有显示)。这个数据框架被称为df。
你创建了一个视图,叫做geodata。
你在geodata上运行你的SQL语句,它就像一个过滤器。这里,它将排除世界和所有大陆,创建一个包含国家和地区的新数据集。
结果被存储在一个新的Dataframe中,称为cleanedDf。

进一步使用SQL
在前面的章节中,你看到了如何使用基本的SQL语句和将行从一个数据集到另一个数据集的一般机制。本节提供了有关资源的信息,以帮助你了解更多关于使用SQL与Spark的信息。
SparkSession.table()方法是值得一提的。该方法直接从会话中返回指定的视图作为一个Dataframe,使你能够避免传递对Dataframe本身的引用。
你可以在http://mng.bz/gVnG 找到一个Spark SQL指南。Databricks也提供了一个关于SQL的指南:http://mng.bz/eD6q。然而,它混合了Apache Spark和Delta Lake的SQL,Databricks数据库(在第17章使用)。
Spark的SQL是基于Apache Hive的语法。Apache Hive的语法可以在http://mng.bz/ad2X。 对兼容性的限制在http:// mng.bz/O90a 中描述。
摘要
Spark支持结构化查询语言(SQL)作为查询数据的语言。
Spark的SQL是基于Apache Hive的SQL(HiveQL),它是基于SQL-92的。
你可以在你的应用程序中混合API和SQL。
数据是通过Dataframe上的视图来操作的。
视图可以是本地的,也可以是全局的,或者在同一个应用程序的会话中共享。视图不会在应用程序之间共享。
由于数据是不可改变的,你不能删除或修改记录;你必须重新创建一个新的数据集。
然而,要从Dataframe中删除记录,你可以在过滤的Dataframe基础上建立一个新的Dataframe。