这一章可能是本书的基石。你通过前11章所收集的所有知识已经把你带到了这些关键问题上。"一旦我有了这些数据,我怎样才能转化它,我又能用它做什么?"
Apache Spark是关于数据转换的,但确切地说,什么是数据转换?如何以可重复和程序化的方式进行这种转换?把它看成是一个工业过程,它将确保你的数据得到充分和可靠的转换。
在本章中,你将进行行级别的转换:在原子级别上操作数据,逐个字段,逐列。为了进行实验,你将使用美国人口普查局关于美国所有州和地区的所有县的人口报告。你将提取信息,这样你就可以建立一个不同的数据集。
一旦你知道如何在一个单一的数据集内转换数据,你将通过连接数据集,就像你对SQL数据库所做的那样。你将简单地看到各种类型的连接。附录M详细介绍了所有类型的连接,供你参考。你将使用两个额外的数据集:一个是来自美国教育部的高等教育机构名单,另一个是由美国住房和城市发展部维护数据文件。
最后,我将给你指出更多存在于资源库中但在书中没有描述的转换。
我相信使用官方来源的真实数据集可以帮助你更彻底地理解这些概念。这个过程肯定模拟了你在日常工作中正在或将要面对的问题。然而,与真实数据一样,你必须经历格式化和理解数据的这一环节。教你这个过程增加了本章的篇幅。
LAB 本章的例子可以在GitHub上找到,网址是:https://github.com/jgperrin/net.jgp.books.spark.ch12.
什么是数据转换?
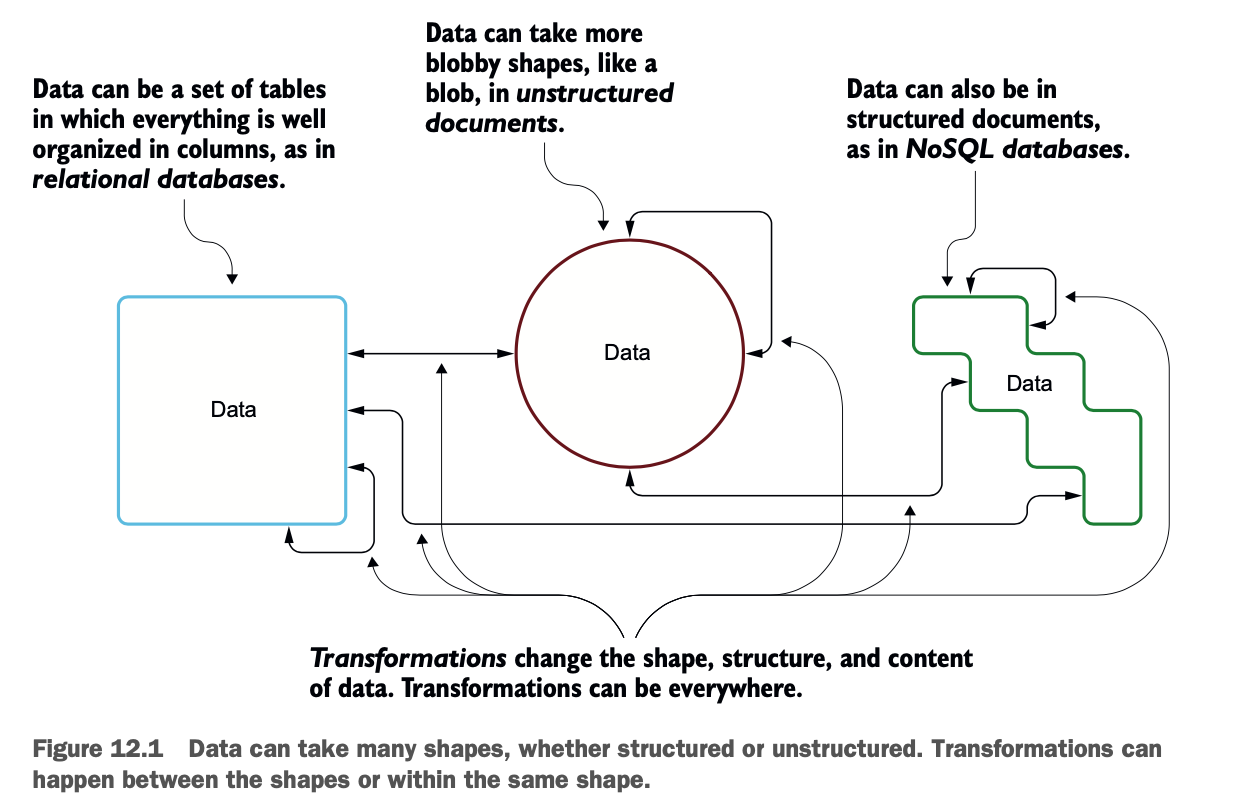
数据转换是将数据从一种格式或结构转换为另一种格式或结构的过程。在这个小节中,你将读到更多关于可以转换的数据类型以及你将能够执行的转换类型。数据可以有几种类型。
数据可以是结构化的、有组织的,比如关系型数据库中的表和列。
数据可以是文件的形式,以半结构化的方式存在。这些文件经常出现在NoSQL数据库中。
数据可以是原始的、完全非结构化的,像二进制大对象(blob)或文档。
数据转换可以将数据从一种类型改变为另一种类型,也可以在同一类型中改变。转换可以适用于数据的几个方面。
在记录层面:你可以直接修改记录(或行)中的值。
在列层面:你可以在Dataframe中创建和删除列。
在数据框架的元数据/结构中。
图12.1总结了可以进行转换的地方。
Apache Spark是任何数据转换的良好候选者;数据的大小 其实并不重要。当数据是结构化的时候,Spark就会大放异彩,但对于更多的blobby(来自blob)和晦涩难懂的数据,Spark也可以轻松扩展。第9章在你从照片中摄取元数据时给了你一个想法。
 在下一节中,你将在记录层面上转换数据,然后在更大的文件层面上转换。
在下一节中,你将在记录层面上转换数据,然后在更大的文件层面上转换。
记录级转换的过程和例子
在本节中,你将在记录层面上转换数据。这意味着你将从一个Dataframe中提取原始数据,并通过计算生成新的数据。要做到这一点,你将遵循一个正确的方法:数据发现、数据映射、数据转换本身(转换的设计和执行),最后是数据验证。
为了充分掌握这个转换过程,你将对来自美国人口普查局(https://factfinder.census.gov)的人口数据进行一些分析。
LAB 数据可在资源库的data/census目录中找到。该实验室是#200,可以在net.jgp.books.sparkInAction.ch12.lab200 recordtransformation包中找到。
你要把人口普查局的数据集从原始数据转化为新的数据集,其作用如下。
使得县和州的情况更加明显
衡量2010年统计的人口和同年估计的人口之间的差异
估计2010年和2017年之间的人口增长情况
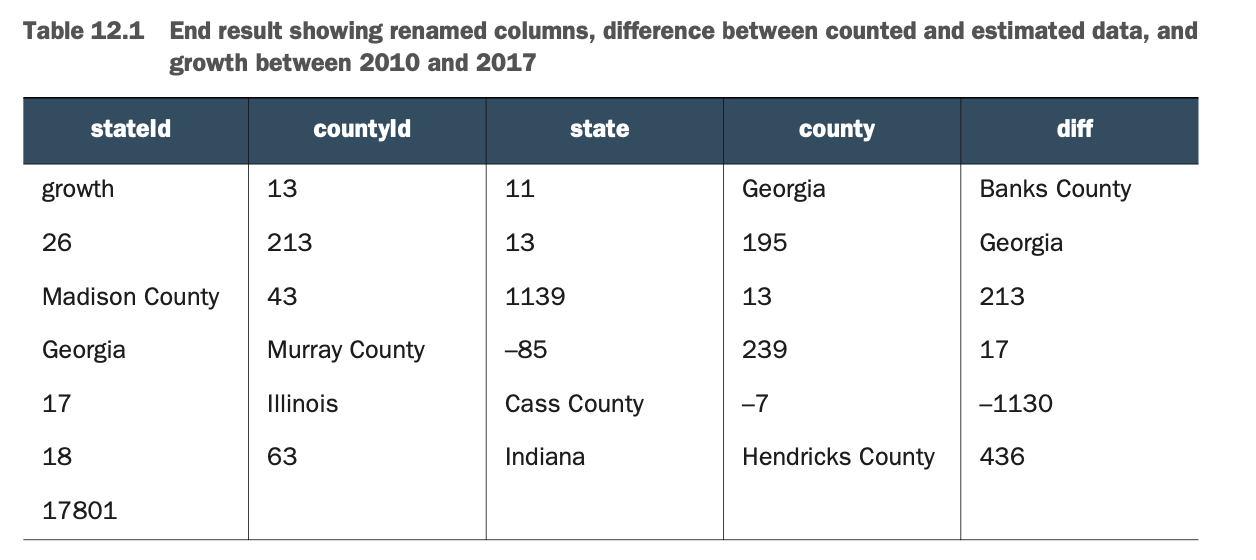
表12.1说明了预期的结果。我把丑陋的ASCII-art形式的输出变成了一个更漂亮、更可读的表格
更漂亮、更易读的表格 在这个输出表中,你可以看到以下内容。
各州和各县非常清楚
2010年统计的人口和其在差异栏中的估计值之间的差异
2010年和2017年之间的估计增长
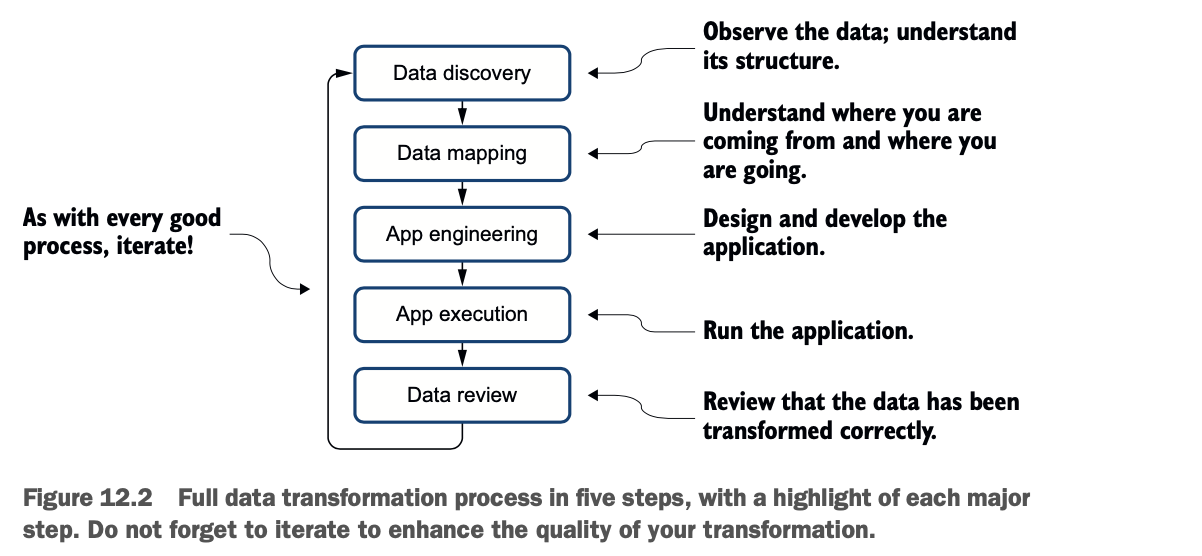
 让我们使用Apache Spark来运行这个实验。然而,在我们跳入代码之前,我们需要遵循一个简单的五步流程。数据转换可以分为这些步骤。
让我们使用Apache Spark来运行这个实验。然而,在我们跳入代码之前,我们需要遵循一个简单的五步流程。数据转换可以分为这些步骤。
1 数据发现
2 数据映射
3 应用程序工程/编写
4 应用程序的执行
5 数据审查
图12.2以图形的方式说明了这个过程,并对每个步骤作了一些提示。
 让我们通过一个例子来详细说明所有这些步骤。
让我们通过一个例子来详细说明所有这些步骤。
数据发现以了解其复杂性
在本小节中,你将执行一个典型的数据发现:你将查看数据并了解其结构。这是在数据映射之前的一个基本操作。通过查看数据(例如,打开一个CSV或JSON文件),你会得到其复杂性的要点。理想情况下,数据会有一个关于结构的解释,说什么字段代表什么。如果没有解释,就要求解释;但不幸的是,根据我的经验,要准备好进行反向工程。
图12.3显示了我们在数据转换过程中的位置。
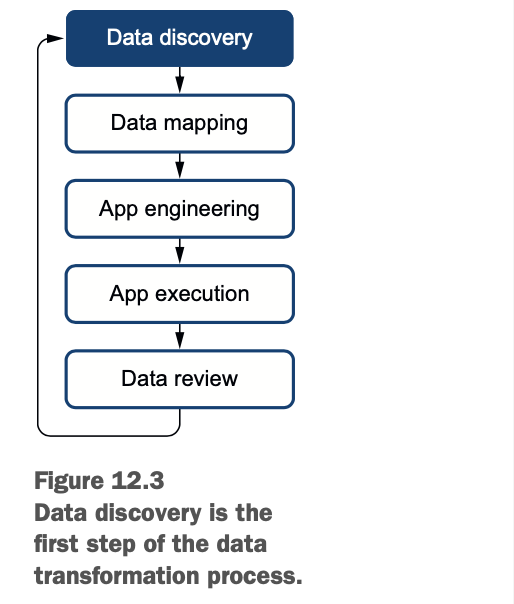 就像每个数据转换项目一样,你要从观察数据和它的结构开始(也叫数据发现)。之后,你将建立映射,编写转换代码,运行代码,最后分析结果。
就像每个数据转换项目一样,你要从观察数据和它的结构开始(也叫数据发现)。之后,你将建立映射,编写转换代码,运行代码,最后分析结果。
下面的列表显示了数据的一个小摘要,它的原始形式是CSV。
它的原始形式,CSV。该文件在/data/census/PEP_2017_PEPANNRES.csv。
 表12.2将数据显示为一个表格。这无疑是有帮助的,但要进入下一步,我们需要对应一个Schema。
表12.2将数据显示为一个表格。这无疑是有帮助的,但要进入下一步,我们需要对应一个Schema。
 表12.3提供了模式(或元数据)。这个表是通过查看人口普查局提供的元数据描述文件建立的。这个文件在资源库中。/data/census/PEP_2017_PEPANNRES_metadata.csv。第一列(字段名)和第二列(定义)是随人口普查局的数据集而来的。第三列包含注释,将帮助你建立映射。
表12.3提供了模式(或元数据)。这个表是通过查看人口普查局提供的元数据描述文件建立的。这个文件在资源库中。/data/census/PEP_2017_PEPANNRES_metadata.csv。第一列(字段名)和第二列(定义)是随人口普查局的数据集而来的。第三列包含注释,将帮助你建立映射。
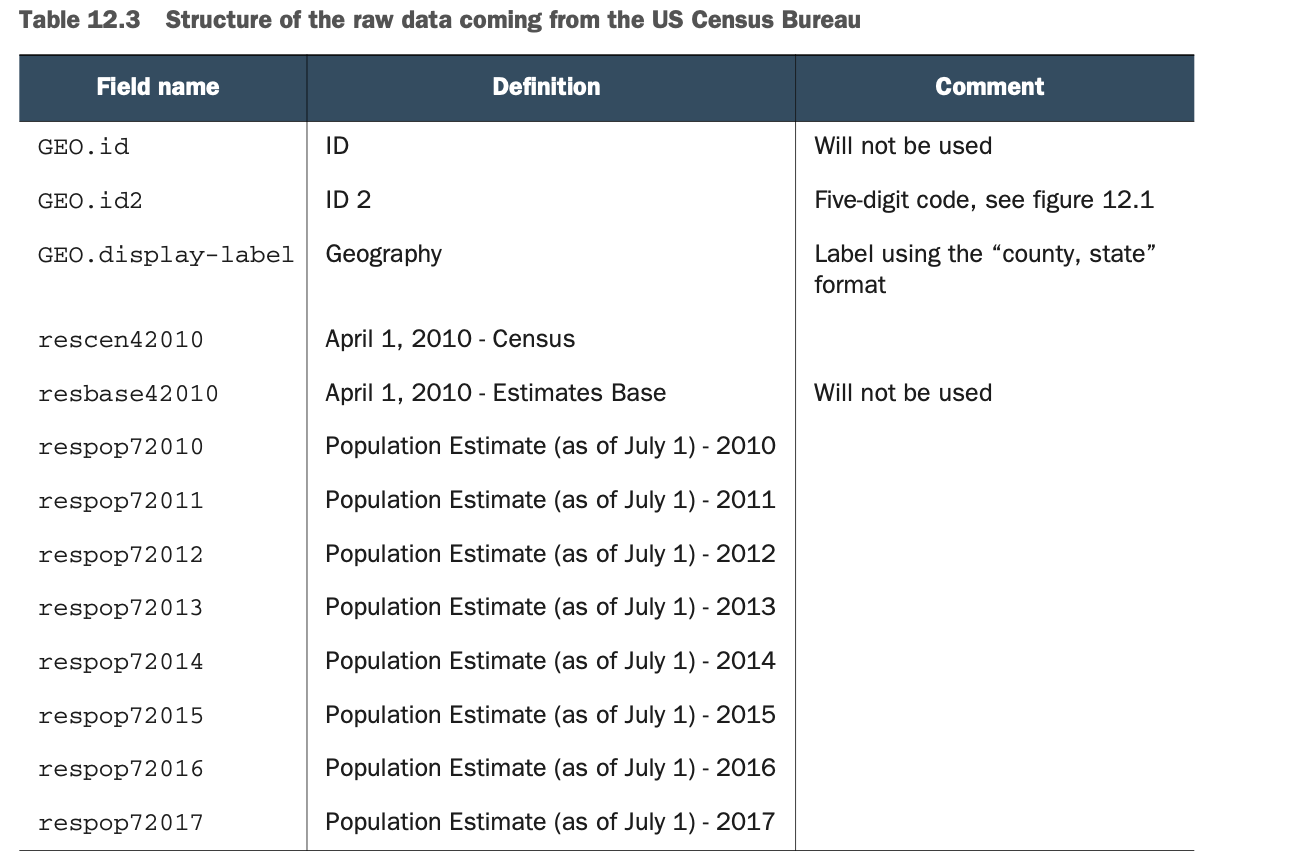 图12.4解释了人口普查局使用的id2字段的结构。
图12.4解释了人口普查局使用的id2字段的结构。

数据映射
现在你已经分析了数据及其结构,现在是时候在原点和目的地之间映射数据了。这个操作被称为数据映射,在你开发应用程序之前是必不可少的:它将来源映射到目的地的数据和结构。你实际上是在进行转换过程。图12.5显示了你在这个过程中的位置。
 在开始映射过程之前,让我们看看表12.4中的预期结果(类似于表12.1)。在这个表中,你可以看到州和县,测得的(由人口普查局的代理人)数据和他们在diff栏中的初始估计之间的差异,以及2010年和2017年之间的增长。
在开始映射过程之前,让我们看看表12.4中的预期结果(类似于表12.1)。在这个表中,你可以看到州和县,测得的(由人口普查局的代理人)数据和他们在diff栏中的初始估计之间的差异,以及2010年和2017年之间的增长。
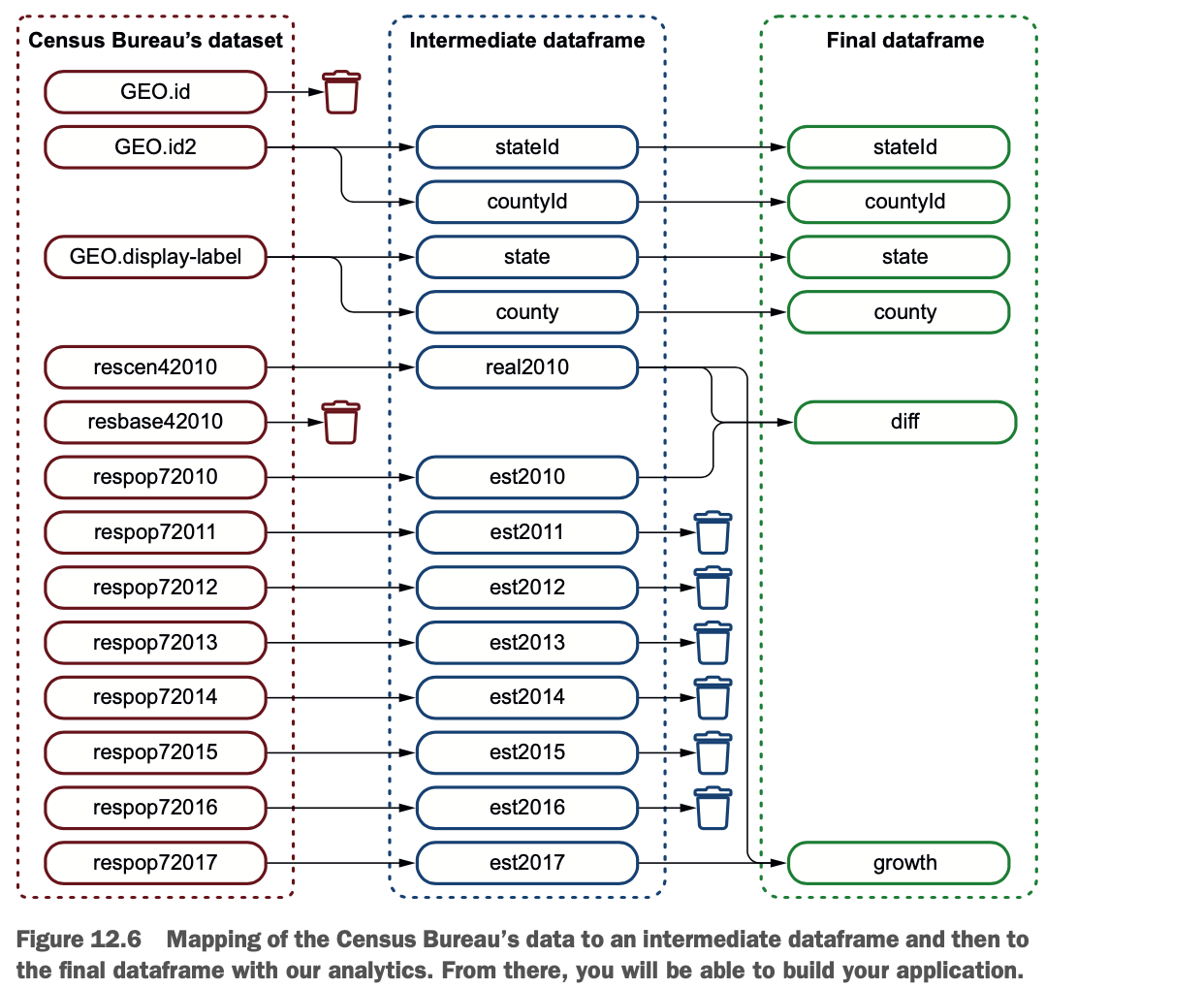
 映射过程帮助你弄清你要用数据做什么。这个过程如图12.6所示。
映射过程帮助你弄清你要用数据做什么。这个过程如图12.6所示。
在这种情况下,我正在使用一个中间的Dataframe。中间Dataframe与其他Dataframe一样,但不提供直接的业务价值。使用中间Dataframe是一个好主意,因为它可以提供以下内容。
一个更干净的数据版本,按你喜欢的格式排列
一个你可以应用所有数据质量规则的Dataframe(更多关于数据质量的内容在第14章)。
一个可缓存或检查点的Dataframe,你将能够更快地重用它。
(更多关于缓存和检查点的内容见第16章)
 性能不会因为使用中间Dataframe而受到负面影响。如果你对数据进行缓存或检查点,性能可以得到提升。第16章提供了更多关于性能调整的细节。
性能不会因为使用中间Dataframe而受到负面影响。如果你对数据进行缓存或检查点,性能可以得到提升。第16章提供了更多关于性能调整的细节。
当一切都在内存中时,缓存的意义何在?
如果你有足够的内存,所有的东西都储存在内存中,对吗?那么你为什么要缓存数据呢?这似乎是一个合理的问题,你可以问。
请记住。Spark是惰性的,不会执行所有的操作(转换),除非你明确要求它(通过一个动作)。
如果你打算在不同的分析中重复使用一个数据框架,那么使用cache()方法来缓存你的数据是一个好主意。这将提高性能。第16章详细介绍了这些操作。
下面的图片说明了当你不缓存数据时会发生什么:操作1、2、3和4每次都要重新进行。
每次运行分析管道时都要执行数据准备步骤;这可以通过使用cache()方法来优化。
下面的图片说明了缓存数据框架的效果:操作1、2、3和4只做一次。
数据准备步骤只做一次。两个分析管道都将使用缓存的Dataframe,从而获得更好的性能。
表12.5显示了中间Dataframe的内容,有质量数据。
 现在,映射已经完成,你已经准备好编写你的应用程序。
现在,映射已经完成,你已经准备好编写你的应用程序。
编写转换代码
我知道--这是你一直在等待的小节。让我们写代码,操作更多的API,然后停止分析,如图12.7所示。
 我本可以直接跳到编写代码,但我强烈地感觉到,优秀的专业人士是不会走捷径的,尤其是在培养良好的习惯方面。因此,尽管这可能是本章中涉及纯编码时最重要的一节,但在涉及整个数据转换过程时,它并不是最重要的。
我本可以直接跳到编写代码,但我强烈地感觉到,优秀的专业人士是不会走捷径的,尤其是在培养良好的习惯方面。因此,尽管这可能是本章中涉及纯编码时最重要的一节,但在涉及整个数据转换过程时,它并不是最重要的。
第一步是建立这个中间的Dataframe。
1 删除你不需要的列。GEO.id和resbase42010。
2 分割ID(GEO.id2)和GEO.display-label列。
3 重命名这些列。
下面的列表显示了建立中间Dataframe的代码。像往常一样,我省略了导入语句,这样你就不会被你使用的库所迷惑。

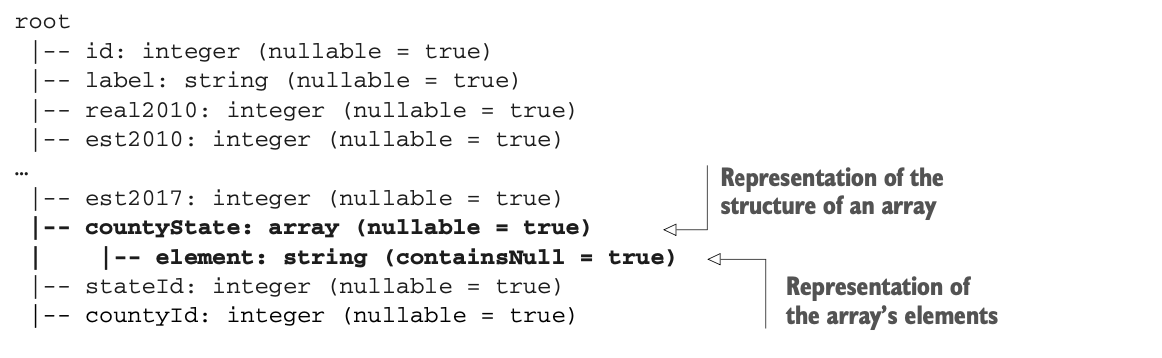
 让我们在这里停一下,分析一下你所建立的数据和结构。在这个阶段,模式看起来是这样的:
让我们在这里停一下,分析一下你所建立的数据和结构。在这个阶段,模式看起来是这样的:
 label列已经用split()静态方法进行了分割。 split()将在一列的值上应用正则表达式,并创建一个值数组。图12.8说明了split()的使用。
label列已经用split()静态方法进行了分割。 split()将在一列的值上应用正则表达式,并创建一个值数组。图12.8说明了split()的使用。
 当你摄取初始文件时,数据看起来像这样。
当你摄取初始文件时,数据看起来像这样。
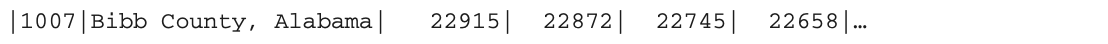 看看县和州的名称是如何体现的,Bibb County,Alabama。在你使用split()函数后,字符串被转换为一个数组,正如值周围的方括号([])所表示的那样。[Bibb County,Alabama]。因此,ASCII表的表示方法类似于这样:
看看县和州的名称是如何体现的,Bibb County,Alabama。在你使用split()函数后,字符串被转换为一个数组,正如值周围的方括号([])所表示的那样。[Bibb County,Alabama]。因此,ASCII表的表示方法类似于这样:
 图12.9提醒了你id是如何组成的。为了从id列中提取stateId,你可以简单地除以1000,然后转换成一个int。为了让Spark做这件事,你将调用expr()方法,它在这种情况下计算出一个类似SQL的表达式。
图12.9提醒了你id是如何组成的。为了从id列中提取stateId,你可以简单地除以1000,然后转换成一个int。为了让Spark做这件事,你将调用expr()方法,它在这种情况下计算出一个类似SQL的表达式。
.withColumn("stateId", expr("int(id/1000)"))同样地,为了提取县的id,你可以检索1000的modulo(取余):
.withColumn("countyId", expr("id%1000"))清单12.3继续构建中间Dataframe,通过提取 countyState 数组的元素。因此,你的数据集不会有嵌套的元素,而只有线性化的数据可以建立,就像一个基本的表格。你看到县(或路易斯安那州的教区)是countyState数组的第一个(索引为0)元素,而州是同一数组的第二个(索引为1)元素:

 正如你所看到的,getItem()方法返回一个数组中的某一列元素。如果你要求一个不存在于数组中的项目(例如,第四个),getItem()将返回null--我希望你会同意,这比处理ArrayIndexOutOfBoundsException要好。
正如你所看到的,getItem()方法返回一个数组中的某一列元素。如果你要求一个不存在于数组中的项目(例如,第四个),getItem()将返回null--我希望你会同意,这比处理ArrayIndexOutOfBoundsException要好。
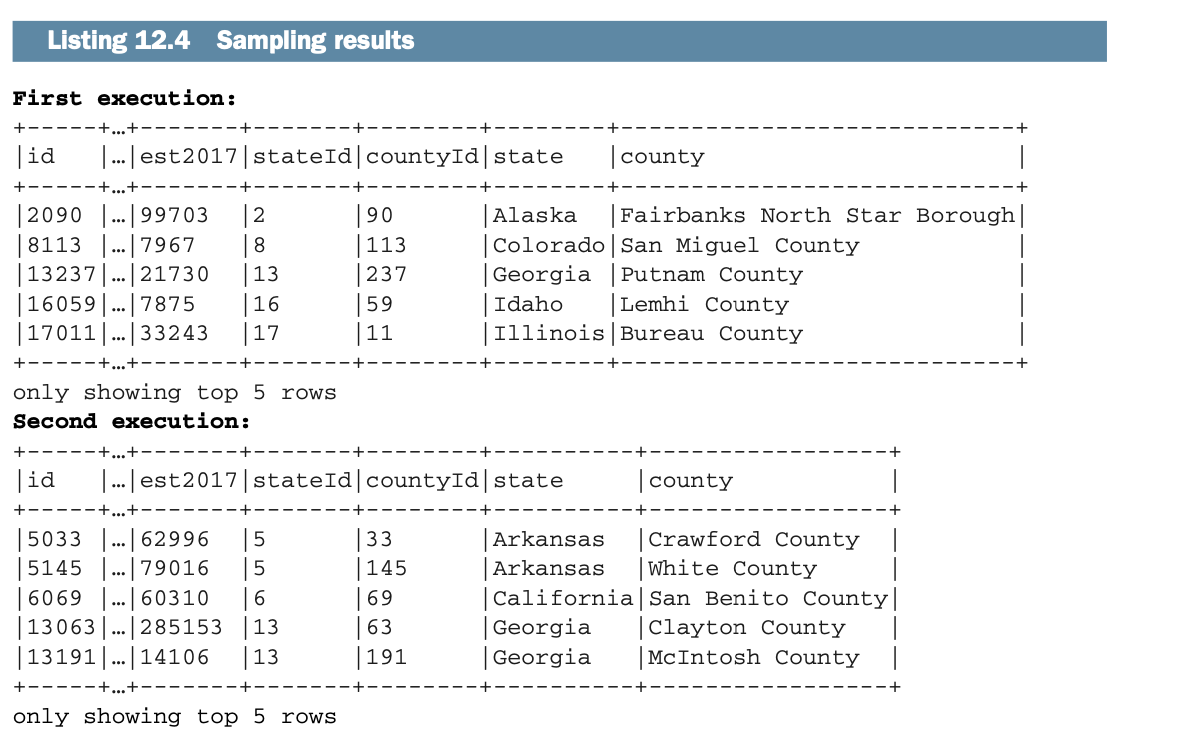
你可能已经注意到在show()之前使用了sample()方法:这允许你从你的数据集中提取一个随机的样本(没有统计替换;见下面的侧边栏)。参数是一个介于0和1之间的双数,表示你想洗掉的行的百分比。sample()方法还有其他形式,你可以指定你是否需要替换(见边栏)或指定一个随机种子。欲了解更多信息,请跳转到http://mng.bz/dxQX。
下面的列表说明了两次执行采样的结果。
更换还是不更换?这是个统计学问题!
德克萨斯大学奥斯汀分校统计和数据科学系的副教授玛丽-帕克对统计学中的替换问题做出了以下人云亦云的解释。
替换式抽样。考虑一个由土豆袋组成的群体,每个土豆袋有12、13、14、15、16、17或18个土豆,而且所有的值都是同样可能的。假设在这个种群中,每个数字都有一个麻袋:整个种群有七个麻袋。如果我以替换方式抽取两个样本,那么我首先挑选一个(例如14)。我有1/7的概率选择这一个。然后我替换它。然后我再选一个。每一个人仍然有1/7的概率被选中。而这里正好有49种可能性(假设我们区分了第一种和第二种)。它们是(12,12)、(12,13)、(12,14)、(12,15)、(12,16)、(12,17)、(12,18)、(13,12)、(13,13)、(13,14),等等。
无替换抽样。考虑相同的土豆袋种群,每个土豆袋有12、13、14、15、16、17或18个土豆,所有的值都是同样的可能性。假设在这个种群中,每个数字都有一个麻袋:整个种群有七个麻袋。如果我在不替换的情况下抽取两个样本,那么我首先挑选一个(比如14)。我有1/7的概率选择这一个。然后我再选一个。这时,只剩下六种可能性:12、13、15、16、17和18。所以这里只有42种可能性(同样,假设你区分了第一种和第二种)。它们是(12,13)、(12,14)、(12,15)、(12,16)、(12,17)、(12,18)、(13,12)、(13,14)、(13,15),依次排列。
有什么区别呢?
当你用替换法取样时,两个样本值是独立的。实际上,这意味着你在第一个样本上得到的东西并不影响你在第二个样本上得到的东西。这也意味着,通过替换,当你对一个Dataframe进行采样时,你可以得到同一行的两次数据。Spark的sample()方法默认是没有替换的。
要了解更多,请跳到https://web.ma.utexas.edu/users/parker/sampling/repl.htm。

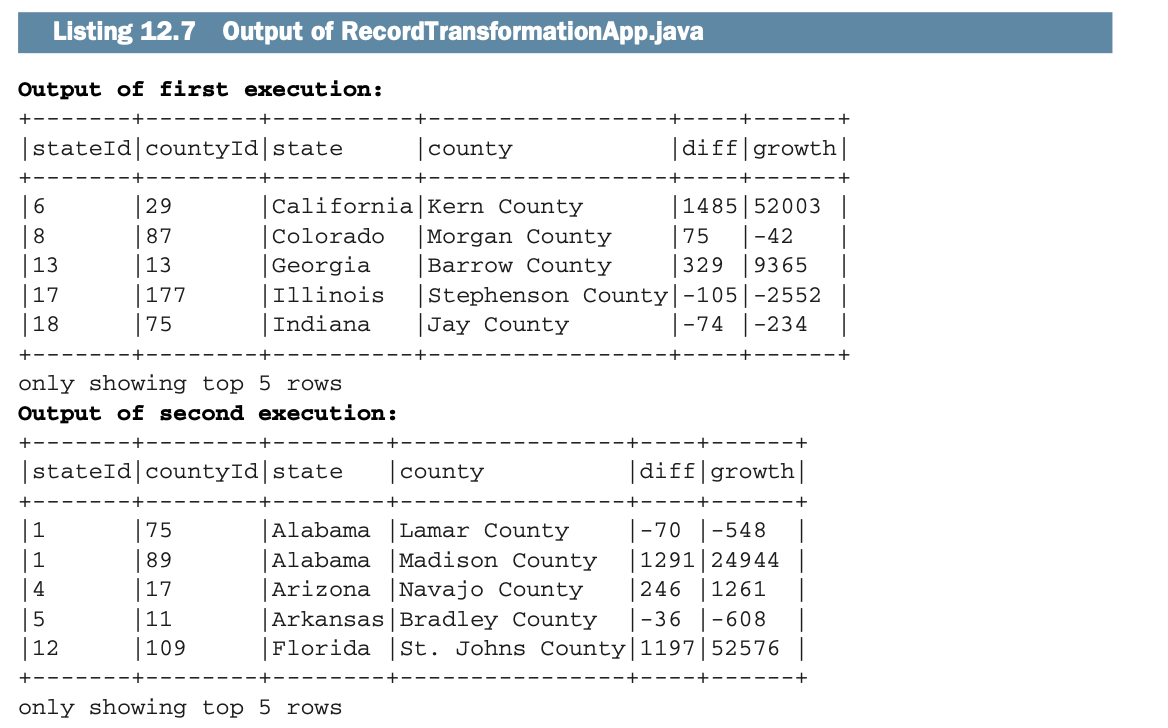
 正如你所看到的,你再一次使用了expr()方法,以类似于SQL的语法来计算我们需要的值。数据转换的第四步是运行你的应用程序(如图12.10所示),这在你的IDE中相当容易。这里没有必要描述它。
正如你所看到的,你再一次使用了expr()方法,以类似于SQL的语法来计算我们需要的值。数据转换的第四步是运行你的应用程序(如图12.10所示),这在你的IDE中相当容易。这里没有必要描述它。
 执行后,你应该得到类似于以下列表的东西。
执行后,你应该得到类似于以下列表的东西。
 让我们进入流程的最后一步,验证转换后的数据。
让我们进入流程的最后一步,验证转换后的数据。
审查你的数据转换,以确保一个高质量的过程
在这个小节中,让我们看看Spark如何帮助你审查你的数据,如图12.11所示。在一个过程中,质量是如此重要的一个组成部分,它不应该被削弱。
 Spark并没有提供专门的工具来审查你的数据。我鼓励你建立数据单元测试,以确保转换的行为方式是你想要的。尽管如此,正如下面列表中所打印的那样,由于sample()方法的存在,多次运行该应用程序将产生不同的输出。
Spark并没有提供专门的工具来审查你的数据。我鼓励你建立数据单元测试,以确保转换的行为方式是你想要的。尽管如此,正如下面列表中所打印的那样,由于sample()方法的存在,多次运行该应用程序将产生不同的输出。
 在这些例子中,我只show()数据。如果你想对数据有一个更精细的观察,你将需要导出它。第17章解释了如何将数据导出到文件和数据库。
在这些例子中,我只show()数据。如果你想对数据有一个更精细的观察,你将需要导出它。第17章解释了如何将数据导出到文件和数据库。
那么排序呢?
在我们结束这个正式的转换之前,让我们看看另一种审查数据和准备报告的方式:排序。
当然,Apache Spark支持对任何数量的列进行排序,无论是升序(默认)还是降序。清单12.8说明了你如何对数据进行排序。sort()方法被应用在Dataframe上。sort()可以接受多列,每一列可以用以下方式排序。
升序,使用asc()
以空值为先的升序,使用asc_nulls_first()
升序,最后为空值,使用asc_nulls_last()。
降序,使用desc()
以空值为先的降序,使用desc_nulls_first()
降序,最后为空值,使用desc_nulls_last()。
 例子中的源代码有注释。为了限制对应用程序的干扰,请随时取消注释,以便更清楚地看到数据。
例子中的源代码有注释。为了限制对应用程序的干扰,请随时取消注释,以便更清楚地看到数据。
总结你的第一次Spark转换
如果你一直在按顺序阅读本书,这并不是你的第一次数据转换。然而,这是你第一次正式的、面向过程的、按部就班的数据转换。现在是提醒你注意这五个步骤的最佳时机。
1 数据发现
2 数据映射
3 应用程序工程/编写
4 应用程序的执行
5 数据审查
在下一章中,你将学习如何像转换记录一样轻松地转换整个文档。
连接数据集
关系型数据库的最佳理念之一是连接。连接是对表之间关系的利用。这种建立关系和连接数据的想法其实并不新鲜(它是在1971年这个伟大的年份被引入的),但已经有所发展。连接是Spark API的一个组成部分,正如你对任何关系型数据库的期望一样。对连接的支持实现了数据帧之间的关系。
在本节中,你将建立一个美国高等教育机构(学院、大学)的列表,其中包括它们的邮政编码、县名和县的人口。这个数据集的一个用途是列出拥有最多学院的县,并计算出每个居民拥有的学院比例。然后,如果你喜欢这种大学氛围和文化,你可以更容易地选择你想住的地方。
与本节相关的实验室是#300,可以在net.jgp.books .sparkInAction.ch12.lab300_join包中找到。
仔细看看要加入的数据集
本小节描述了你将在本实验室中使用的数据集。和上一节一样,让我们从数据发现开始。你有三个数据集供你使用。
美国高等教育机构的名单,由美国教育部的中学后教育办公室(OPE)提供。这份名单被称为 "经认证的中学后教育机构和课程数据库"(DAPIP)。
由美国人口普查局提供的美国所有县和州的名单,以及它们的人口估计。这个列表包含了每个县的唯一标识符,基于联邦信息处理标准(FIPS,https://en.wikipedia.org/wiki/FIPS_county_code)。每个县都有一个FIPS ID。
一个映射列表,将每个邮政编码分配给一个县的ID。这个列表来自美国住房和城市发展部(HUD)。
图12.12给出了这三个数据集的关系表示以及它们之间的联系。
在数据发现阶段,你可以看一下数据的形状。这时你会注意到,在高等教育机构数据集中没有邮政编码:你必须从地址中提取。图12.13说明了如何从地址中提取邮政编码。
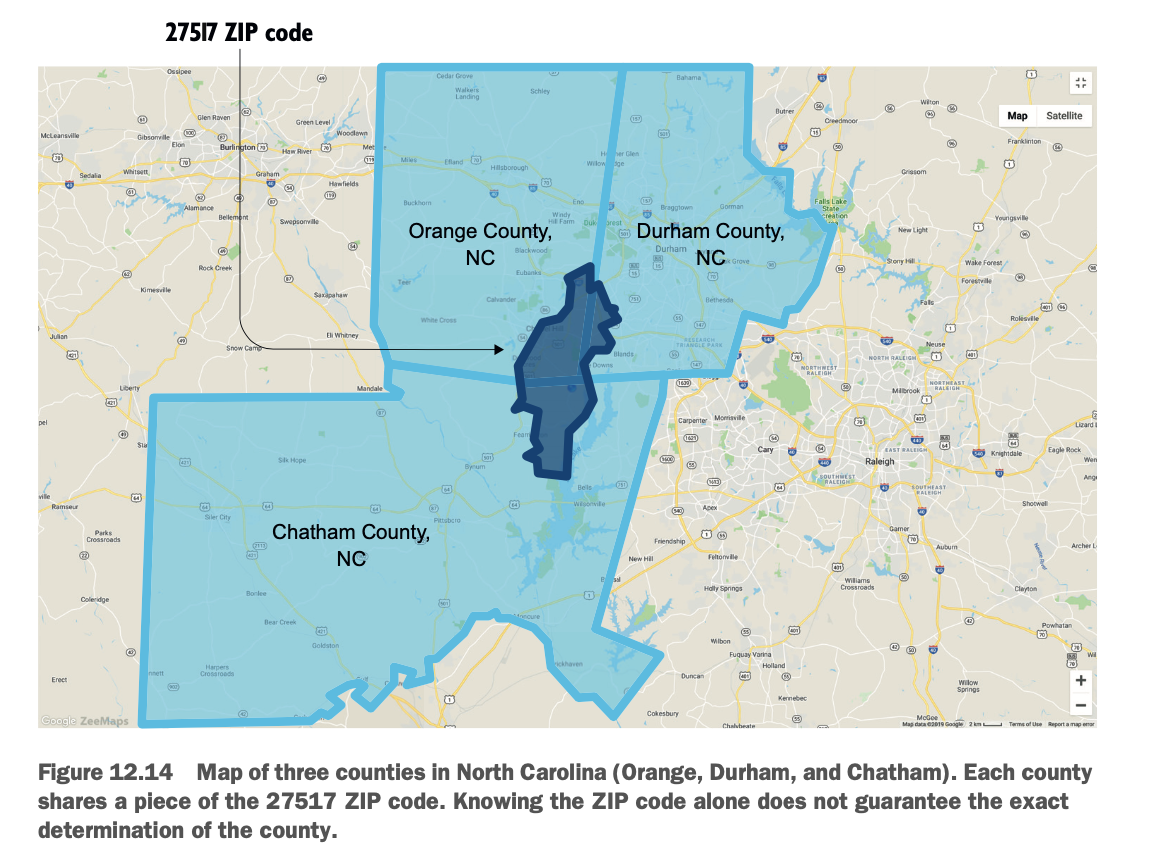
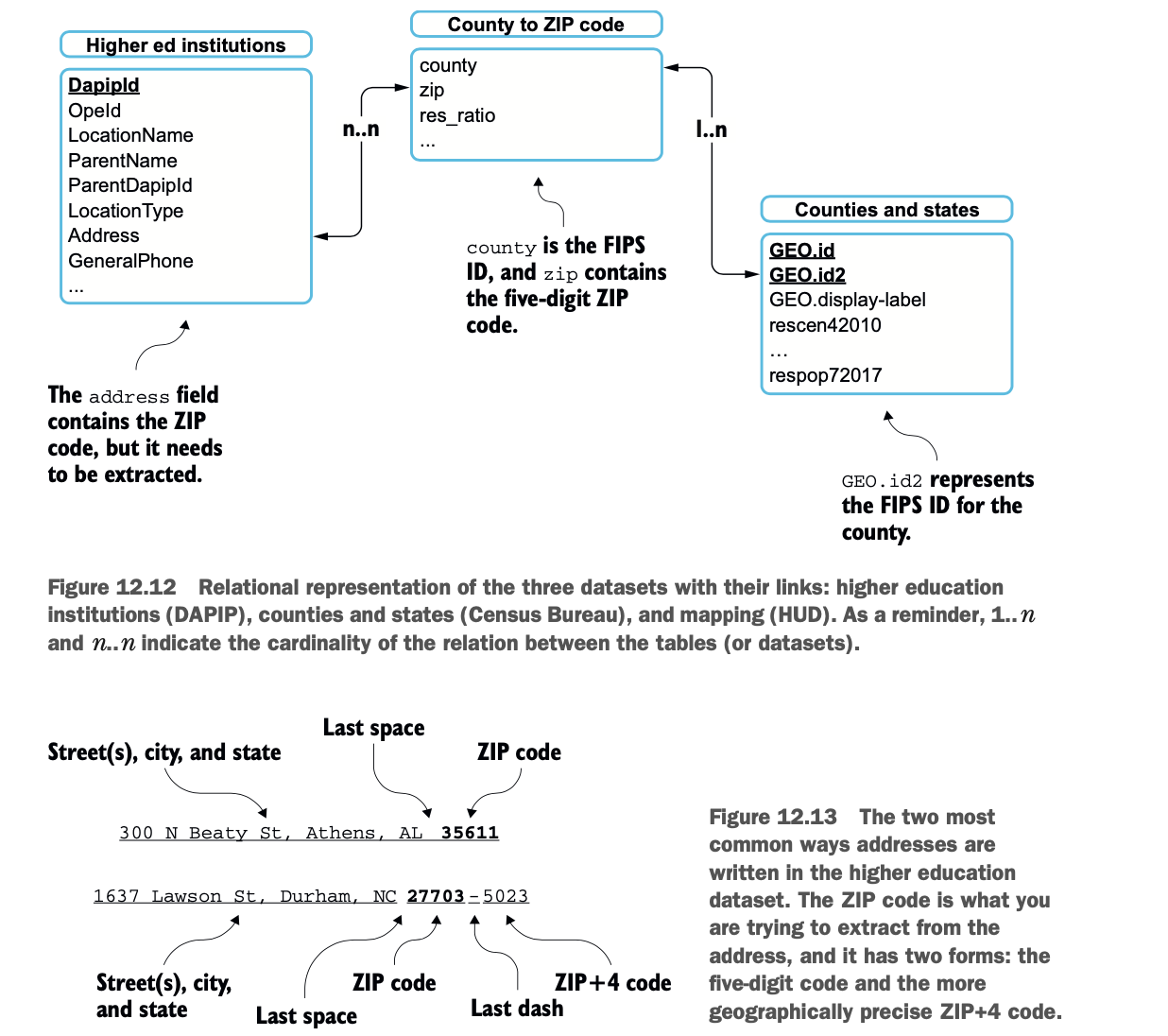 另一个发现使事情变得有点复杂:邮政编码是由美国邮政服务(USPS)建立的,不是一个县的细分。因此,有时一个邮政编码会覆盖几个县。图12.14显示了一个共享邮政编码的三个县的地图。
另一个发现使事情变得有点复杂:邮政编码是由美国邮政服务(USPS)建立的,不是一个县的细分。因此,有时一个邮政编码会覆盖几个县。图12.14显示了一个共享邮政编码的三个县的地图。
HUD的数据集给了你一个县和几个邮政编码之间的映射。唯一可以更精确区分的方法是对照美国邮政的地理信息系统(GIS),但这并不公开。因此,我将假设一个邮政编码地区的机构将惠及与该邮政编码相连的所有县;例如,位于邮政编码27517的英语学习机构将被列入奥兰治、达勒姆和查塔姆三个县。这并不完全准确,但可以说该研究所的影响力在这三个县。
现在你已经分析了数据并完成了数据发现,你可以开始转化数据了。
建立每个县的高等教育机构名单
现在你将按照你刚刚完成的数据发现,建立每个县的高等教育机构名单。让我们先看看输出结果,然后一步一步地进行数据的转换。
最终的列表将看起来像下一个列表。为了让表格适应并仍然能够阅读,我在列的末尾使用了省略号。
 我将把应用程序分解成小片段,这样你就可以专注于每个片段。你将做以下工作。
我将把应用程序分解成小片段,这样你就可以专注于每个片段。你将做以下工作。
1 加载并清理每个数据集。
2 在机构数据集和映射文件之间进行第一次连接。
3 在结果数据集和人口普查数据之间执行第二个连接,以获得县的名称。
Spark的初始化
建立我们列表的第一步是导入所需的库并初始化Spark。你还将导入几个静态函数来帮助你进行转换。这在下一个列表中完成。
如果你已经依次读了这本书,这可能是你第一百万次做这个操作了。尽管如此,看看你将要使用的静态函数吧。
 载入和准备数据
载入和准备数据
你将用来转换数据的静态函数
建立我们的高等教育名单的第二步是加载和准备所有的数据集。这个操作实际上是将所有的数据摄入Spark中。你将加载和清理以下内容。
人口普查数据(列表12.11)。
高等教育机构(列表12.12)。
县代码和邮政编码之间的映射(列表12.13)。
人口普查数据看起来应该是这样的。
 清单12.11加载了人口普查CSV文件,删除了你不需要的列,并将各列重命名为更友好的名称。
清单12.11加载了人口普查CSV文件,删除了你不需要的列,并将各列重命名为更友好的名称。
注意文件的编码是Windows/CP-1252,因为有些县有重音字符(例如,波多黎各的Cataño Municipio)。你也在推断模式,这在你连接列的时候变得很重要(连接在类似的数据类型下更有效率)。
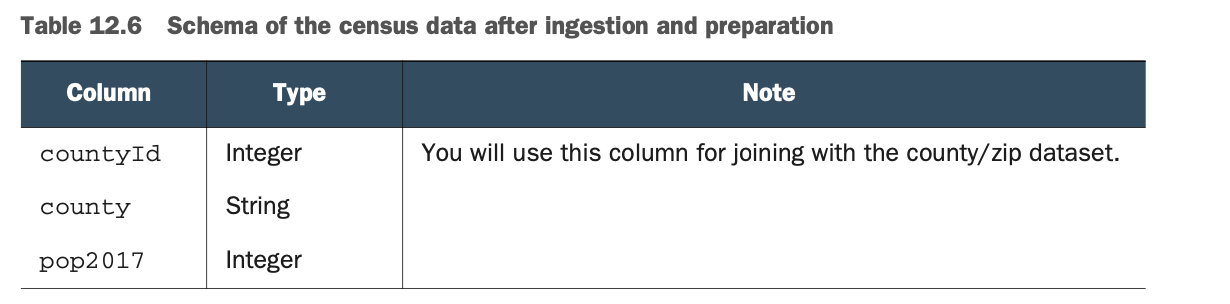
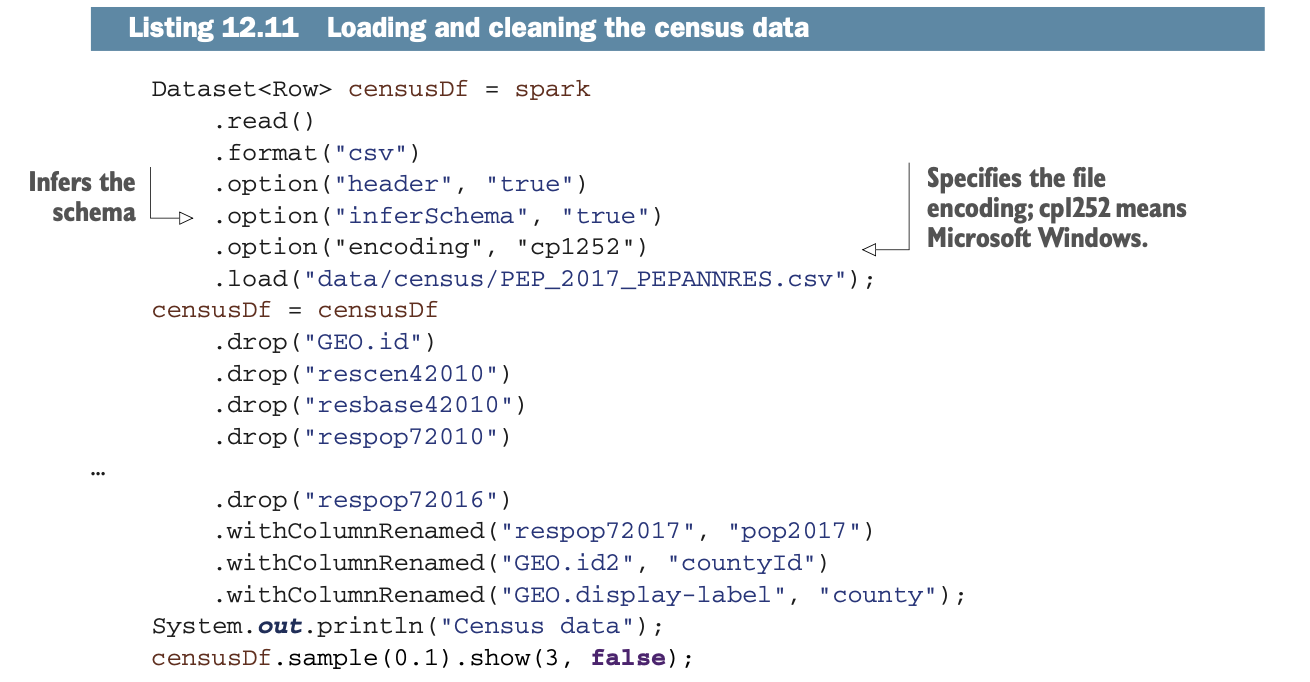 表12.6显示了该Schema。
表12.6显示了该Schema。
 我们来加载第二个数据集,即高等教育机构。摄取和准备之后,你的数据集应该看起来像这样:
我们来加载第二个数据集,即高等教育机构。摄取和准备之后,你的数据集应该看起来像这样:
 在这个数据集中,你将不得不从地址中提取邮政编码。图12.15说明了通过使用数据帧API和函数来提取正确信息的过程。为了从地址中提取邮政编码,你要做以下工作。
在这个数据集中,你将不得不从地址中提取邮政编码。图12.15说明了通过使用数据帧API和函数来提取正确信息的过程。为了从地址中提取邮政编码,你要做以下工作。
1 隔离地址字段。
2 在每个空格处分割(分离)该字段的每个元素。这将创建一个数组 这将创建一个数组,存储在addressElements列中。
3 计算数组中元素的数量,并将结果存储在 addressElementCount列中。
4 一个格式良好的地址(在这个数据集中)的最后一个元素是邮政编码。你将 你将把它存储在zip9列中。在这一步,你可以有一个五位数的邮政编码或一个九位数的邮政编码。数字的邮政编码,或者使用九位数字的邮政编码(也称为ZIP+4)。
5 根据破折号分割zip9列,并将结果存储在 zips列中。
6 最后,取zips列的第一个元素。
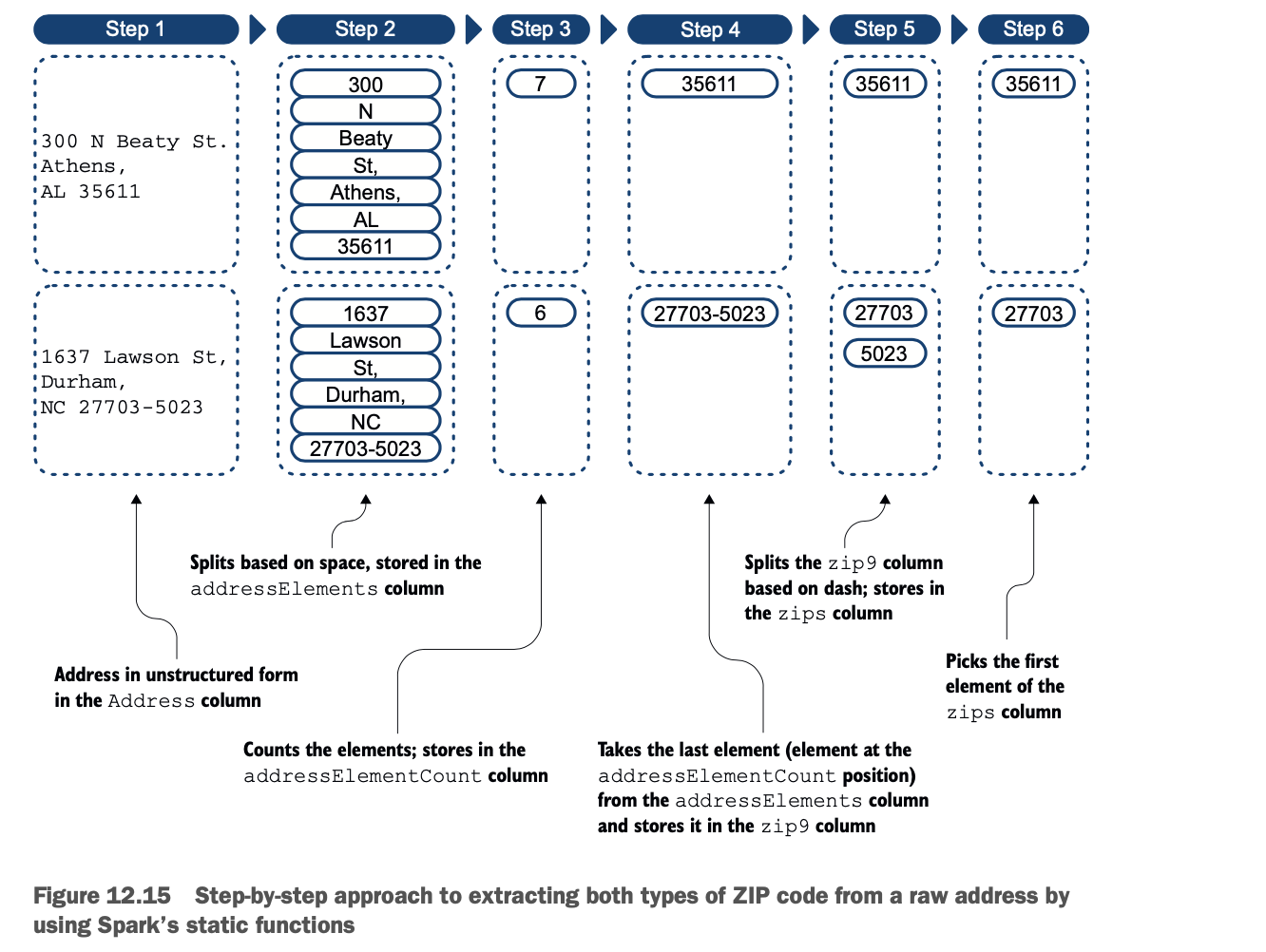 下面的列表显示了加载和准备数据的过程。
下面的列表显示了加载和准备数据的过程。

这是一个SQL数组
是的,这是个技巧! 在清单12.11中,你正在计算元素的数量,你直接使用这个值,而不是减一的值。这是因为 element_at() 使用一个 SQL 数组,它的第一个元素在索引 1,而不是 0(像 Java 数组)。
如果你试图获取第2个元素,你会得到一个异常:java.lang.ArrayIndexOutOfBoundsException。然而,这在第1个元素的情况下是显而易见的;对于其他元素则要非常小心
表12.7给出了生成的Dataframe的模式。
 最后,你可以加载最后一个数据集:由HUD提供的邮政编码与县的映射关系。数据框的输出将看起来像这样:
最后,你可以加载最后一个数据集:由HUD提供的邮政编码与县的映射关系。数据框的输出将看起来像这样:
 这个数据集的摄取相当容易,你可以在下面的列表中看到。
这个数据集的摄取相当容易,你可以在下面的列表中看到。
 与这个数据框架相关的模式在表12.8中。
与这个数据框架相关的模式在表12.8中。

进行连接
在前面的小节中,你加载了数据,并对其进行了准备,以便可以使用。在本小节中,你将执行连接并分析它们是如何工作的。你正处于建立一个与某个县相关的美国高等教育机构列表的最后一步。
你将首先在高等教育数据集和邮政编码与县的映射之间进行连接,以将FIPS县的ID添加到列表中。你的第二个连接将在新创建的数据框架和人口普查数据库之间进行,以添加县名。最后,你将进行清理操作,以符合预期的结果。
使用连接将FIPS县域标识符与高等教育数据集连接起来
你将首先在左边的高等教育数据集和右边的县/邮政编码映射文件之间执行一个连接。这个连接将使用邮政编码,其结果将把机构与FIPS县的标识符联系起来。
结果的Dataframe应该是这样的。
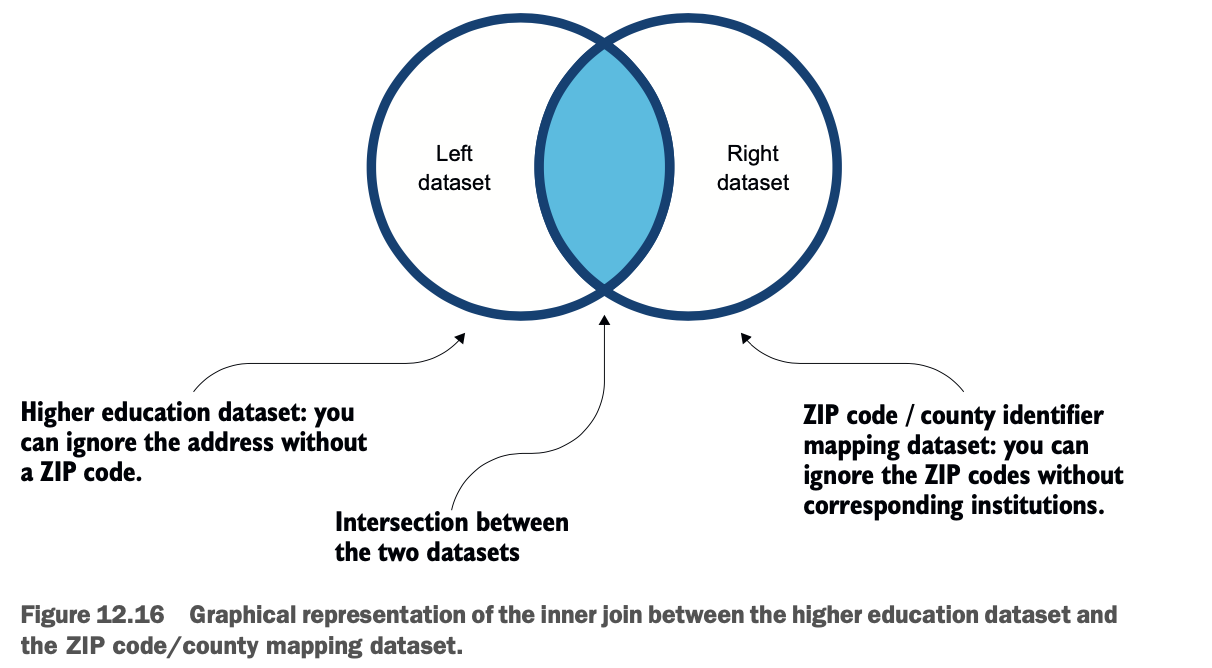
 在数据发现阶段,你可能已经注意到,有些地址没有邮政编码。你可能不想把这些机构带过去;你也不希望没有机构的地区。因此,你可以做一个内联,如图12.16所示。
在数据发现阶段,你可能已经注意到,有些地址没有邮政编码。你可能不想把这些机构带过去;你也不希望没有机构的地区。因此,你可以做一个内联,如图12.16所示。
 下面的列表显示了执行连接的代码。
下面的列表显示了执行连接的代码。
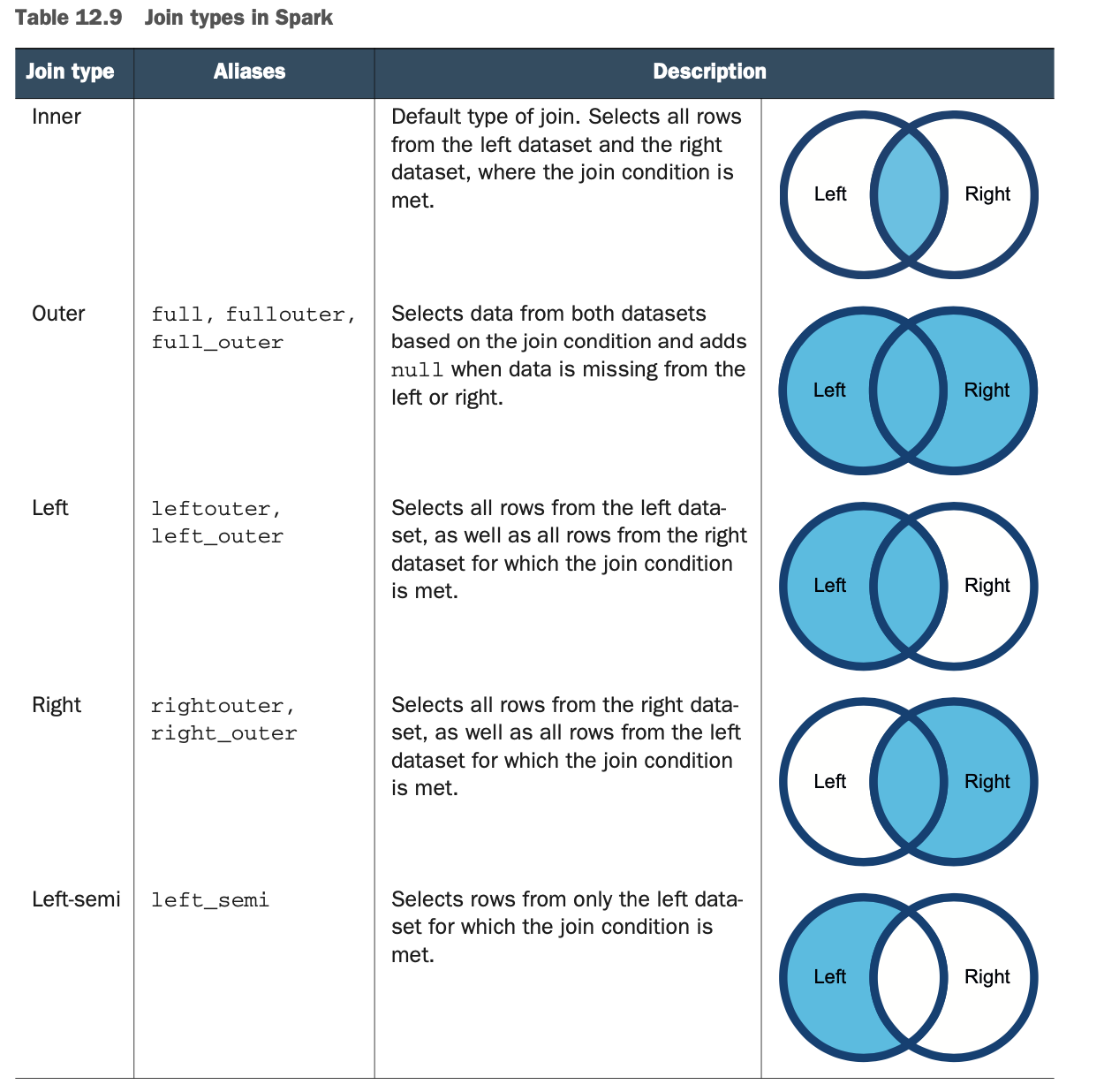
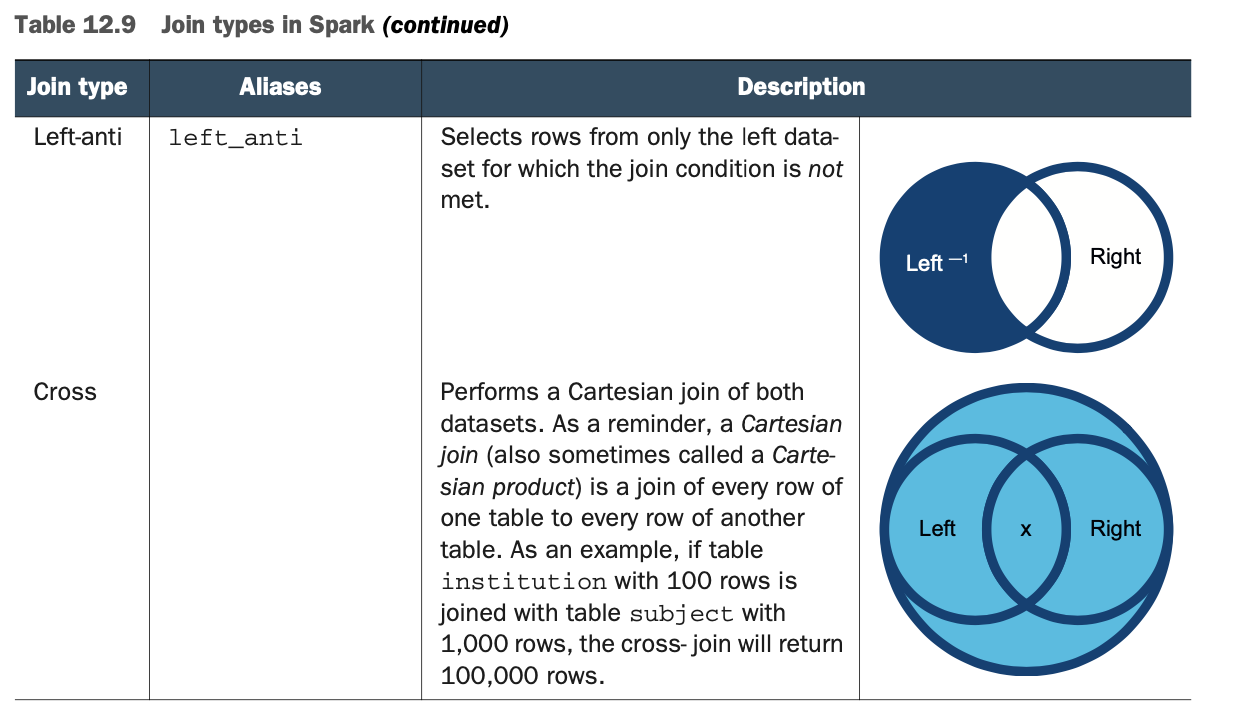
 就这样吧! 我承认有很多准备工作才走到这一步,但连接仍然很简单。join()方法有几种形式(见附录M和http://mng.bz/rP9Z)。 也有相当多的连接类型。表12.9中总结了连接类型。本章资源库中的第940号实验室在几个数据帧上执行了所有可能的连接。关于连接操作的完整参考资料可在附录M中找到。
就这样吧! 我承认有很多准备工作才走到这一步,但连接仍然很简单。join()方法有几种形式(见附录M和http://mng.bz/rP9Z)。 也有相当多的连接类型。表12.9中总结了连接类型。本章资源库中的第940号实验室在几个数据帧上执行了所有可能的连接。关于连接操作的完整参考资料可在附录M中找到。
 在这个阶段,你的institPerCountyDf 数据框架看起来像这样。
在这个阶段,你的institPerCountyDf 数据框架看起来像这样。
 如果你看一下Schema,如表12.10,你会看到你仍然有两个名为zip的列。这种奇怪的现象还在继续,因为你可以看到它们有不同的数据类型:一个是字符串类型,另一个是整数类型。
如果你看一下Schema,如表12.10,你会看到你仍然有两个名为zip的列。这种奇怪的现象还在继续,因为你可以看到它们有不同的数据类型:一个是字符串类型,另一个是整数类型。
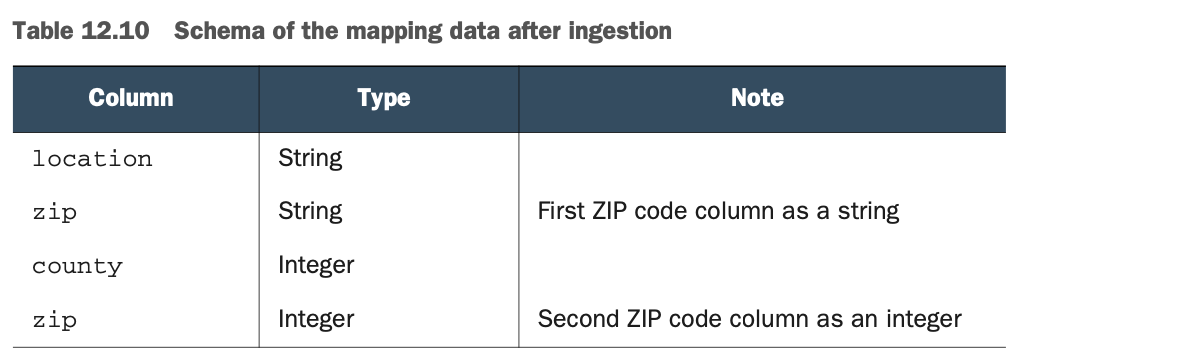 正如你所看到的,对于Spark来说,做以下事情是完全可以的。
正如你所看到的,对于Spark来说,做以下事情是完全可以的。
当两个(或更多)列是连接的结果时,有两个(或更多)列具有相同的名称,尽管这似乎有悖常理
在具有不同数据类型的列上进行连接
现在,如果你想删除其中一个zip列,你将不得不指定该原始列来删除它。如果你执行
institPerCountyDf.drop("zip");你将失去所有称为zip的列,并得到这个。
 如果你只想删除其中一列拉链,你可以指定原来的Dataframe并使用col()方法:
如果你只想删除其中一列拉链,你可以指定原来的Dataframe并使用col()方法:
institPerCountyDf.drop(higherEdDf.col("zip"));图12.17说明了zip的来源。

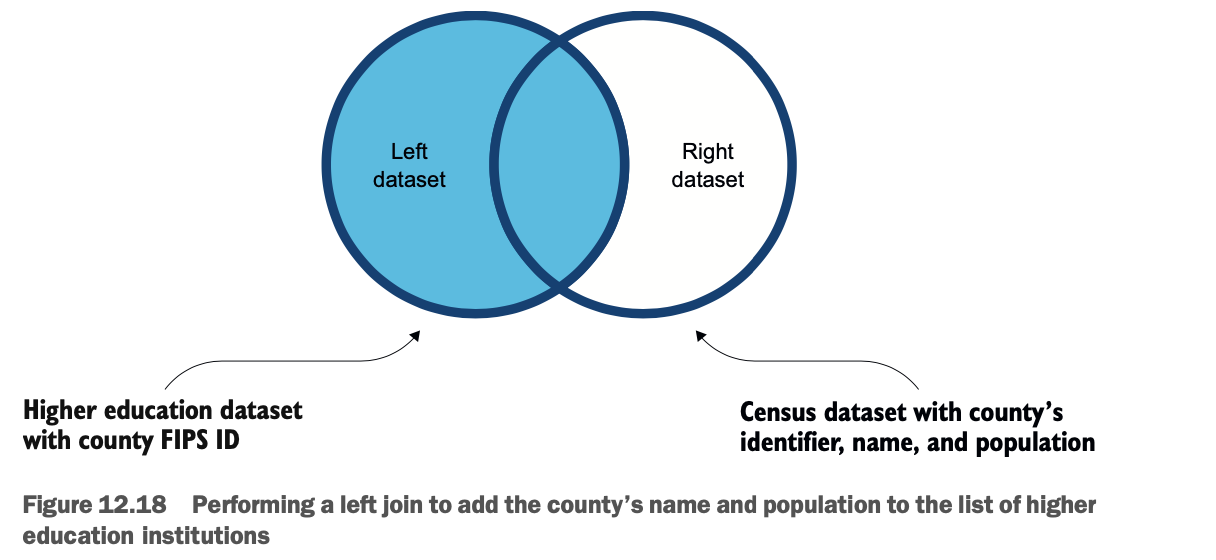
加入人口普查数据以获得县名
你的Dataframe现在包含了位置、邮政编码和FIPS县的ID。为了增加名称,你必须将人口普查数据加入到现有的数据集中。在这个连接操作之后,你将不得不放弃多余的列,正如你刚才所看到的,选择正确的列。
我们的最终结果将是这样的。
 为了执行这个任务,你将执行一个左连接,如图12.18所示。
为了执行这个任务,你将执行一个左连接,如图12.18所示。
 下面的列表显示了执行连接的代码。
下面的列表显示了执行连接的代码。
 再一次,你可以看到在Spark中的连接并不比关系型数据库复杂。最后,你可以清理多余的列,这些列在本实验室中是不需要的。你可以删除这些列。
再一次,你可以看到在Spark中的连接并不比关系型数据库复杂。最后,你可以清理多余的列,这些列在本实验室中是不需要的。你可以删除这些列。
高等教育数据集中的zip列。
绘图/住房数据集中的县级列。
CountyId列;不要混淆它来自哪个数据集。
下面的列表向你展示了如何做到这一点,以及如何通过使用distinct()删除重复的行。
 你已经完成了! 你现在可以使用这个新的数据集来进行分析和其他数据发现。该实验室包含了关于如何对数据进行分组(聚合在第13章)或对特定地理区域进行过滤的注释代码,以及更多。
你已经完成了! 你现在可以使用这个新的数据集来进行分析和其他数据发现。该实验室包含了关于如何对数据进行分组(聚合在第13章)或对特定地理区域进行过滤的注释代码,以及更多。
执行更多的转换
这一章很长,但它是本书的真正基石。要选择合适的例子,不把这一章变成一整本书,真的很不容易 在本章的资源库中还有很多实验,本节介绍这些应用。
表12.11总结了你将在GitHub资源库中找到的其他实验。

摘要
一个数据转换可以分为五个步骤。
数据发现
数据映射
应用程序工程/编写
应用程序的执行
数据审查
数据发现是对数据和其结构的研究。
数据映射在转换的原数据和目标数据之间建立了一个数据映射。
为了帮助数据发现和映射,应该有一个关于原数据和结构的定义。
静态函数是数据转换的关键。它们在附录G中有描述。Dataframe的cache()方法允许缓存,可以帮助提高性能。
expr()是一个方便的函数,它允许你在转换数据时计算一个类似SQL的语句。
一个Dataframe可以包含数值的数组。
Dataframe可以被连接在一起,就像关系数据库中的表一样。
Spark支持以下几种连接:内连接、外连接、左连接、右连接、左-半连接、左-反连接和交叉连接(笛卡尔)。
当在Dataframe中操作时,数组遵循SQL标准,从1开始索引。
你可以通过使用sample()从Dataframe中提取数据的样本。sample()方法支持统计学中的替换概念。
可以通过使用asc()、asc_nulls_first()、asc_nulls_last()、desc()、desc_nulls_first()和desc_nulls_last()在数据框架中对数据进行排序。
Spark可以连接Dataframe,每次两个,并支持内联、外联、左联、右联、左半联、左反联和交叉联。
更多的转换例子可以在GitHub仓库中找到,网址是https://github.com/jgperrin/net.jgp.books.spark.ch12。