本章的重点是整个文档的转换。Spark将摄取一个完整的文档,对其进行转换,并以另一种格式提供给它。
在上一章中,你阅读了关于数据转换的内容。下一个合乎逻辑的步骤是转换整个文档及其结构。举个例子,JSON对于传输数据来说是很好的,但当你必须遍历它来做分析时,就会非常痛苦。类似地,加入的数据集有很多数据冗余,以至于要有一个合成视图是很痛苦的。Apache Spark可以帮助处理这些情况。
在结束本章之前,我将教你更多关于Spark为数据转换提供的所有这些静态函数。它们有很多,给你每个例子都需要另一本书!因此,我希望你能掌握这些静态函数。因此,我希望你有工具来浏览它们。附录G将是你的伙伴。
最后,我将为你指出更多存在于资源库中但在书中没有描述的转换。
和前几章一样,我相信使用官方来源的真实数据集会帮助你更彻底地理解概念。在本章中,我也在有意义的地方使用了简化数据集。
LAB 本章的例子可在GitHub上找到:https://github.com/jgperrin/net.jgp.books.spark.ch13。
转化整个文档及其结构
在本节中,你将开始转换整个文档。首先,你将对一个JSON文档进行扁平化处理,当你想进行分析时,这是一个有用的操作。一个JSON文档的嵌套组成将使分析更加困难。扁平化将打破这种结构。在这一节的后面,你将进行相反的操作:基于两个CSV文件建立一个嵌套的文档。这个用例在构建数据管道时相当常见--例如,从一个系统/数据库中获取数据,从中构建一个JSON文档,并将该文档存储在NoSQL数据库中。
图13.1展示了一个典型的场景:你可以从IBM Db2等面向交易的数据库中提取订单数据,并在Elasticsearch等面向文档/搜索的数据库中存储一个代表订单的文档。这样的系统可以用来减轻终端用户对订单的检索,而不增加交易数据库服务器的负载。
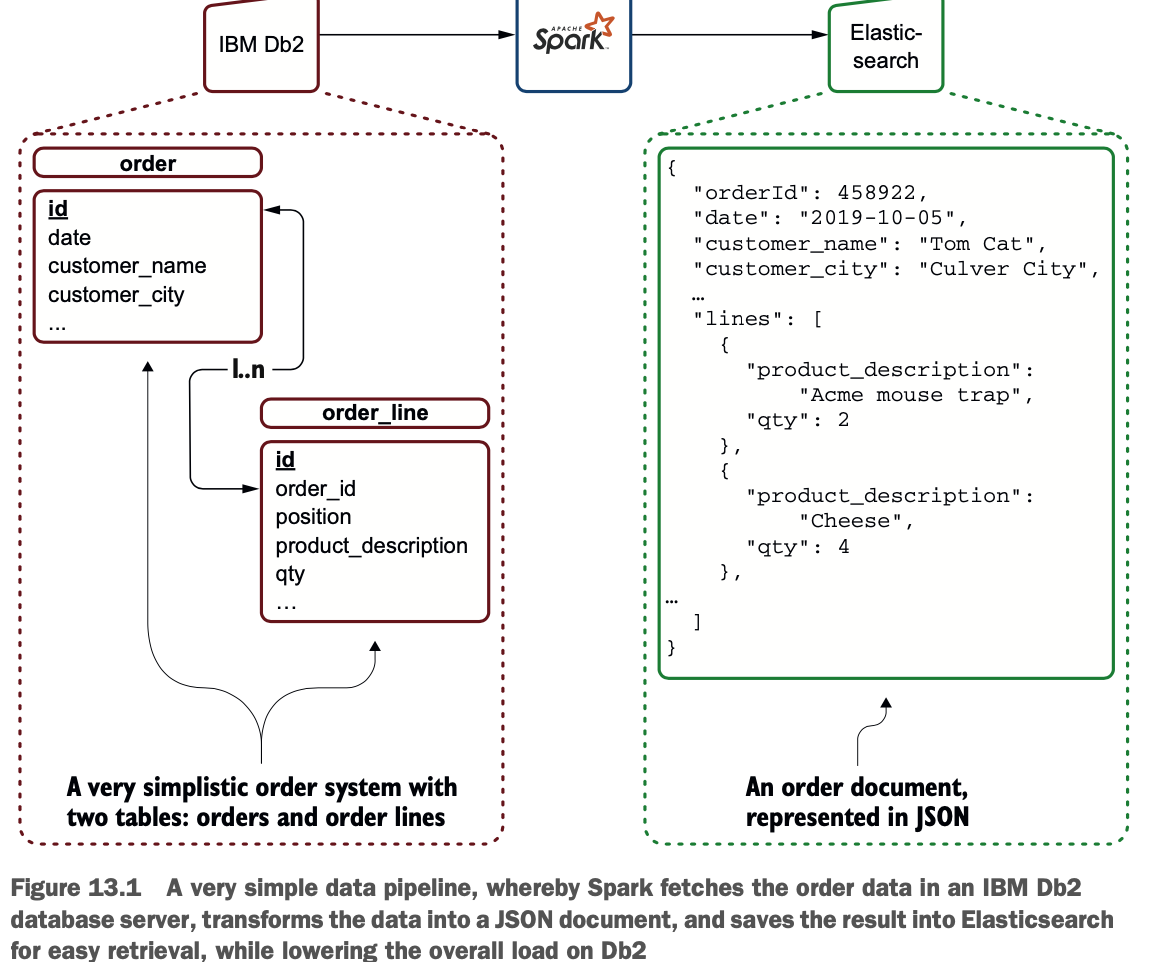
扁平化你的JSON文档
如你所知,JSON是一种分层格式;简而言之,数据被组织成一个树状结构。在本小节中,你将练习扁平化JSON文档:将JSON和它的分层数据元素转换为表格格式。
JSON文档可以包含数组、结构,当然也包括字段。这使得JSON相当强大,但当你想进行分析操作时,这个过程会变得很复杂。因此,扁平化将嵌套的结构变成一个扁平的、类似表格的结构。
为什么要对JSON文档进行扁平化?如果你想执行聚合(group by)或连接,JSON并不理想;访问嵌套数据并不容易。
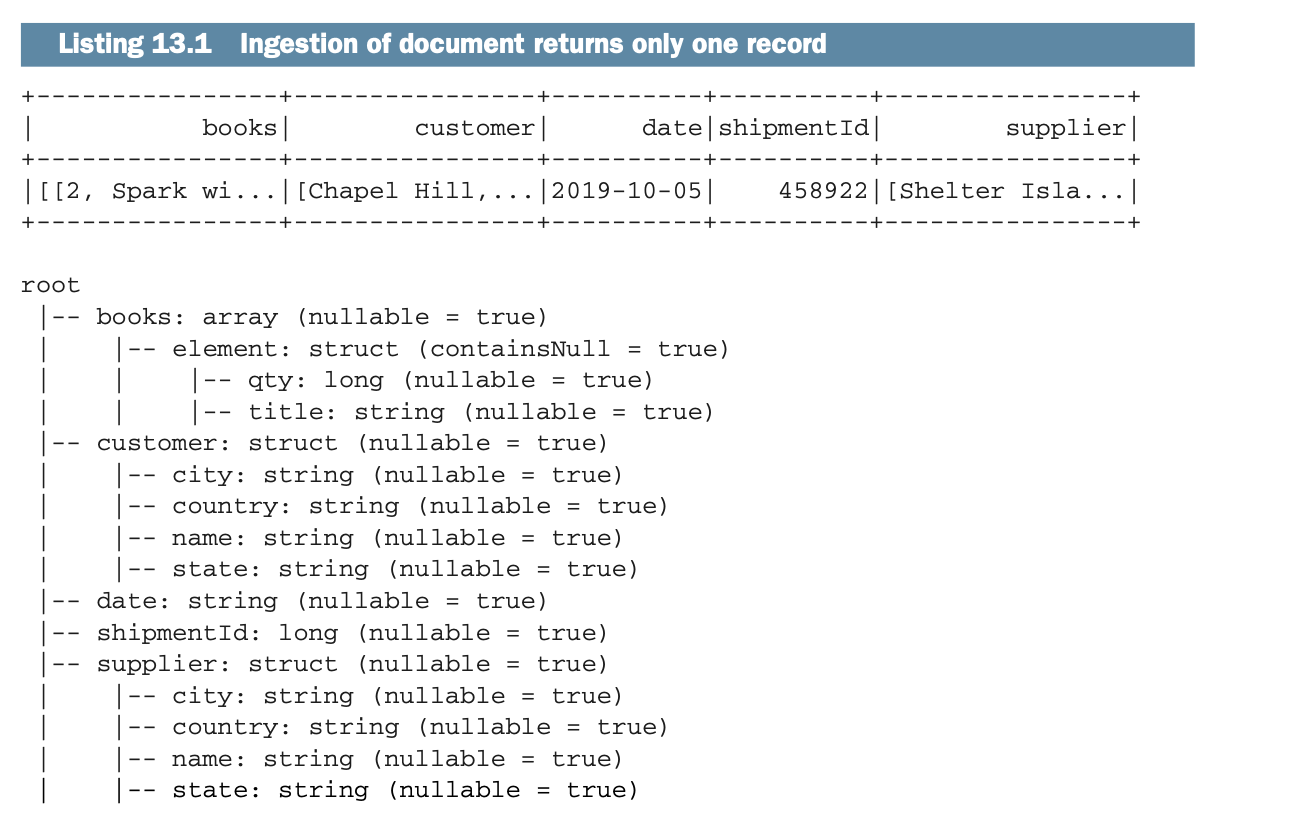
让我们来看看这个(假的)发货单。正如你所看到的,该文档以两个字段开始,接着是两个结构(或对象),以及一个由三本书组成的数组。
 如果你在Spark中摄取这个文档,然后显示Dataframe并显示其Schema,你将得到只有一条记录,如以下列表所示。
如果你在Spark中摄取这个文档,然后显示Dataframe并显示其Schema,你将得到只有一条记录,如以下列表所示。
LAB 你可以通过使用 net.jgp.books.sparkInAction.ch13.lab100_json_shipment 包中的 lab #100 来重现这个输出。检查JsonShipmentDisplayApp.java。
扁平化这个文件包括将结构转换为字段,并将数组爆炸成不同的行。
去规范化的文档
在JSON形式中,文档被规范化了,就像关系型数据库可以被规范化一样。例如,你可以使用第三正常形式(3NF)来减少数据的重复。这主要是通过使用更多的表、标识符和表之间的关系来实现的。这些概念是由E.F. Codd在1971年提出的;更多信息请跳转到https://en.wikipedia.org/wiki/Third_normal_form。
去规范化包括相反的操作,以方便分析。扁平化JSON是一种去规范化的操作。
图13.2说明了JSON和关系表之间的平行关系。
根据图13.2,如果你想通过使用SQL来计算这批货物中发送的标题数量,你会进行这样的操作。
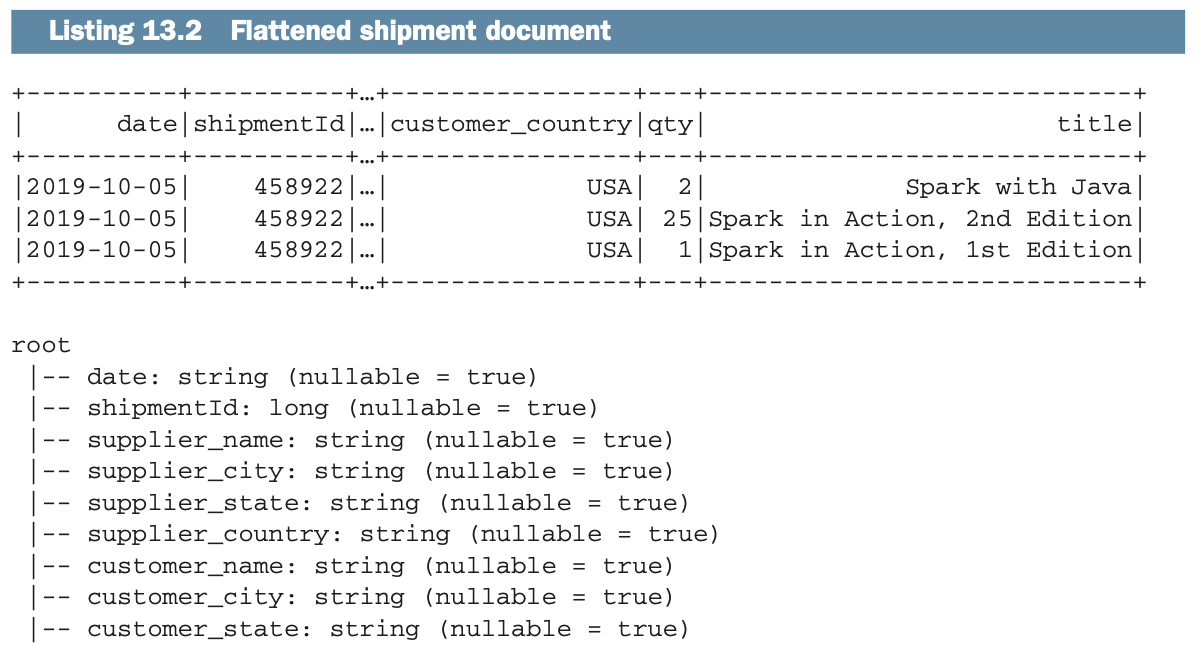
SELECT COUNT(*) AS titleCount FROM shipment_detail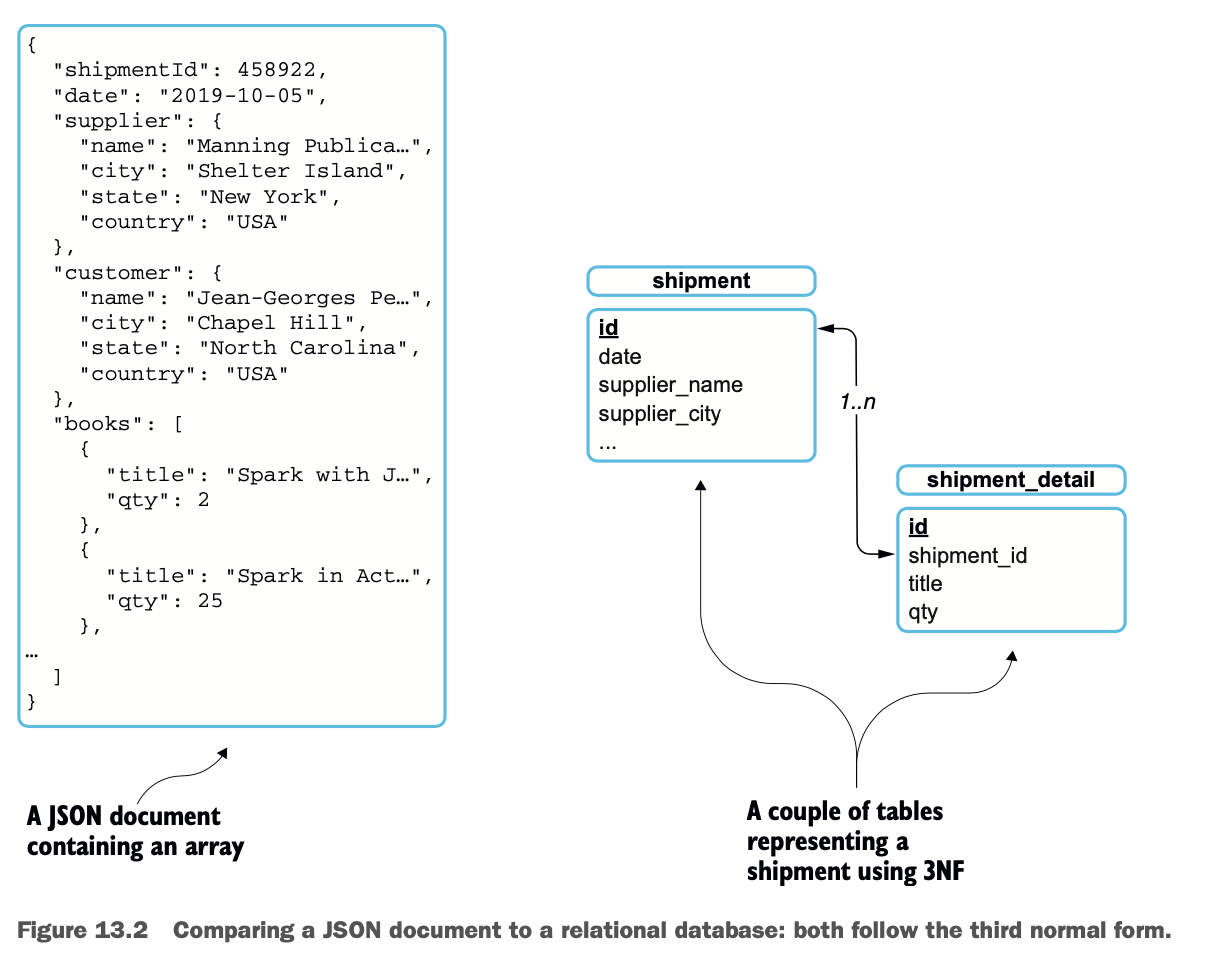 使用Spark,一种方法是先将文件扁平化,得到类似下面的列表。
使用Spark,一种方法是先将文件扁平化,得到类似下面的列表。
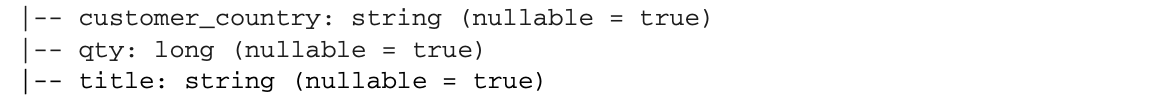 现在你已经看到了这个目标,让我们来看看如何执行这个操作。图13.3描述了你将如何用Spark转换这个文档。
现在你已经看到了这个目标,让我们来看看如何执行这个操作。图13.3描述了你将如何用Spark转换这个文档。
 清单13.3显示了执行这一转换的代码。在你创建了一个会话并接收了文件后,你将做以下工作来准备数据。
清单13.3显示了执行这一转换的代码。在你创建了一个会话并接收了文件后,你将做以下工作来准备数据。
1 将结构中的列映射到你文件的顶层。这将打破嵌套。
2 删除你不需要的列。
3 对书籍列进行扩展,使每本书成为一条记录。
现在你的数据集已经准备好了,你可以应用SQL查询来计算书名的数量,正如你在第11章中学到的那样。

 在这种情况下,你将需要把你的转换一分为二。Spark不会意识到你刚刚创建的项目列,而这是需要继续的:
在这种情况下,你将需要把你的转换一分为二。Spark不会意识到你刚刚创建的项目列,而这是需要继续的:
 请注意,explode()是一个有用的方法:它为给定数组或map列中的每个元素创建一个新行,这确实是操作数据框架中嵌套字段的最简单方法。现在你已经成功地平铺了一个JSON文档,让我们看看如何创建一个嵌套文档。
请注意,explode()是一个有用的方法:它为给定数组或map列中的每个元素创建一个新行,这确实是操作数据框架中嵌套字段的最简单方法。现在你已经成功地平铺了一个JSON文档,让我们看看如何创建一个嵌套文档。
构建用于传输和存储的嵌套文档
在上一小节中,你扁平化了一个JSON文档以方便分析。在本节中,你将做相反的事情:从两个链接的数据集中建立一个嵌套文档。当你必须发送结构化的文档时,这很有用--例如,符合快速医疗互操作性资源(FHIR)标准的索赔。
你将建立一个方法,你将能够重复使用,以嵌套的方式轻松组合数据集。这个方法叫做nestedJoin()。嵌套文件可用于传输和存储,但也有许多其他用例。
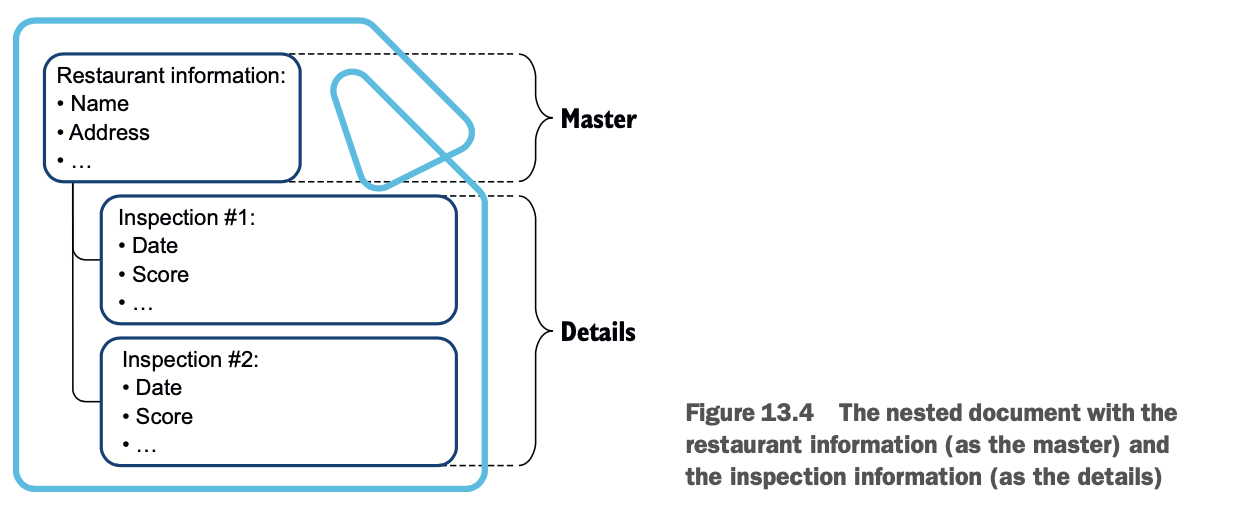
在第120号实验室中,你不打算处理健康护理,而是处理餐馆数据。你要建立一个主文件来定义一个餐厅,并以嵌套的方式详细说明所有的检查。这些数据来自北卡罗来纳州的奥兰治县。它遵守Yelp定义的当地检查员价值-输入规范(LIVES)格式。图13.4说明了你要建立的文档。
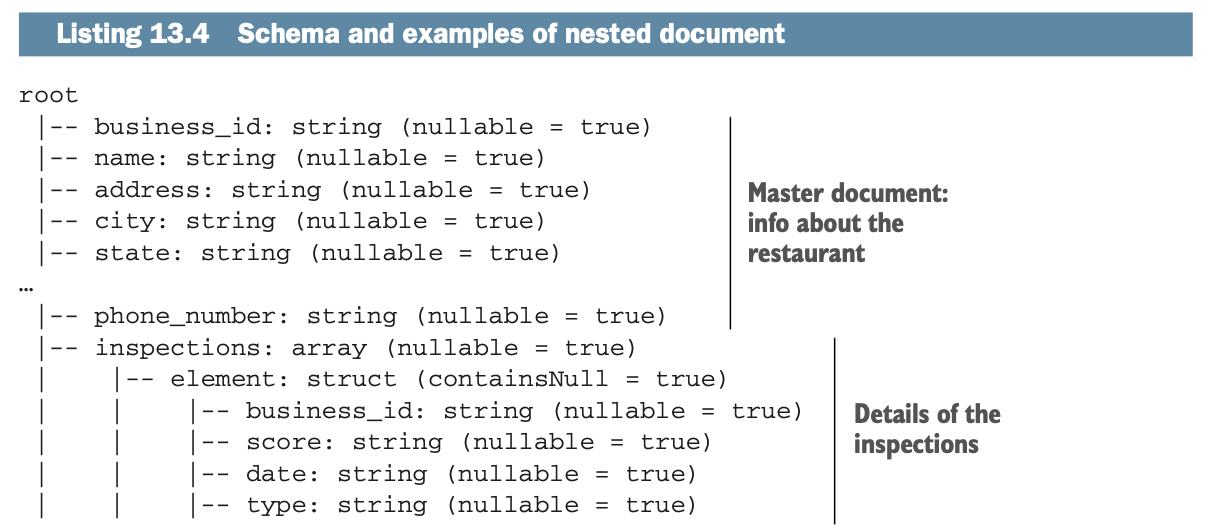
 数据集和要建立的数据集的Schema将看起来像下面的列表。
数据集和要建立的数据集的Schema将看起来像下面的列表。
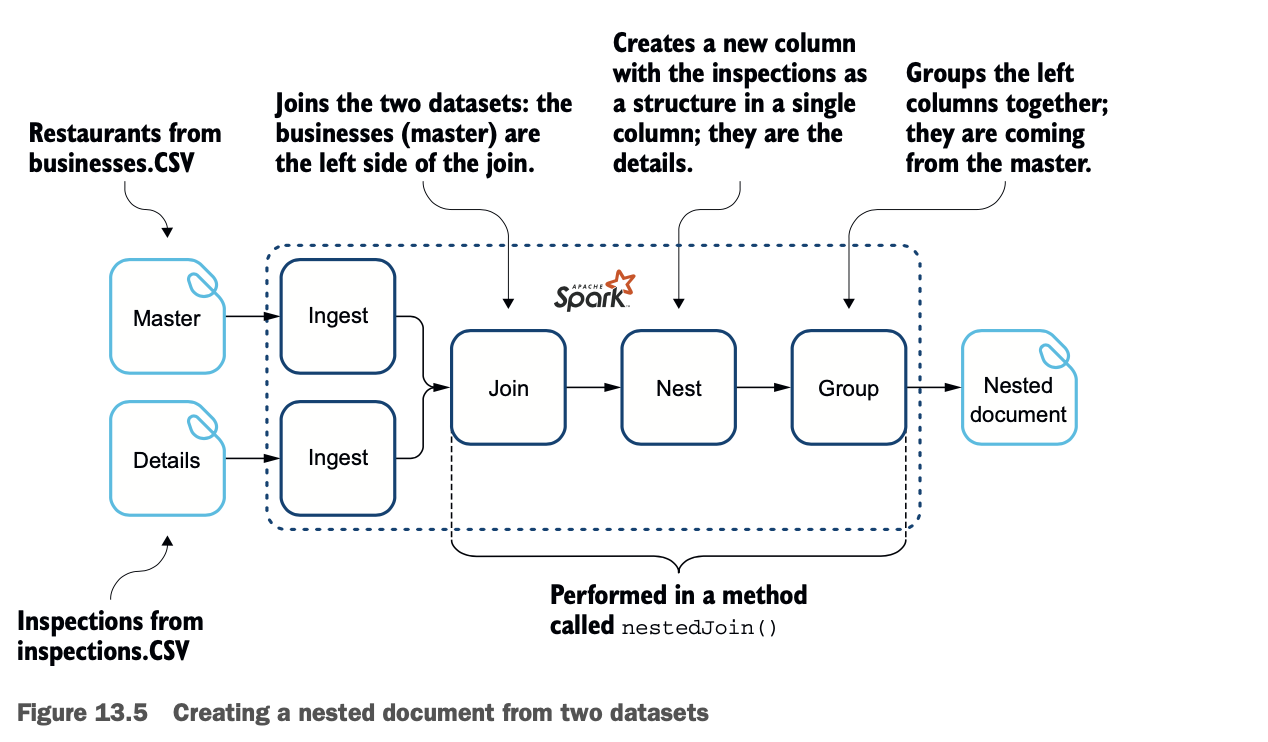
 检查以单元格中的嵌套文件形式出现。图13.5描述了这个过程。
检查以单元格中的嵌套文件形式出现。图13.5描述了这个过程。
 代码的第一部分很简单。正如你在下面的列表中看到的,你在一个Dataframe中加载两个数据集,然后调用nestedJoin()方法。
代码的第一部分很简单。正如你在下面的列表中看到的,你在一个Dataframe中加载两个数据集,然后调用nestedJoin()方法。

 让我们研究一下nestedJoin()方法。Spark将做以下工作。
让我们研究一下nestedJoin()方法。Spark将做以下工作。
在两个Dataframe之间进行连接
为每个检查创建一个嵌套结构
将餐厅中的行组合在一起
在详细研究这些操作之前,让我们看看你可以在实验室中使用的一个辅助函数。这个函数,getColumns(),从一个Dataframe中建立一个Column实例的数组。
 清单13.6将使用这个函数并建立嵌套文档。你将使用几个静态函数。
清单13.6将使用这个函数并建立嵌套文档。你将使用几个静态函数。
struct(Column... cols) 创建一个Column,其数据类型是由作为参数传递的列构建的结构。
collect_list(Column col),作为一个聚合函数,返回一个对象的列表。它将包含重复的内容。
col(String name) 返回基于名称的列,相当于Dataframe的col()方法。
 第15章更详细地介绍了聚合。
第15章更详细地介绍了聚合。
静态函数背后的魔力
本节从高层次上描述了在本章和前几章中帮助你的静态函数。诸如expr(), split(), element_at()等函数每天都在帮助Spark开发者。
本节强调了静态函数的重要性。但它并不是对这些函数的参考,关于参考资料,请看附录G和网上的补充资料。
FAVORITE BOOKMARK
你可以在[Spark SQL, Built-in Functions](https://spark.apache.org/docs/latest/api/sql/index.html) 找到描述的静态函数。这是我收藏的关于Spark的五个页面之一。
从Spark v2.x开始,函数的一般语法使用蛇形大小写(关键字用下划线隔开);例如,format_string(),它可以格式化一个列。这与Java和Scala的函数相反,后者使用驼峰大小写,如toString()。
函数对一列整体工作,而不仅仅是一个单元。函数是多态的,这意味着它们可以有多个签名。
表13.1说明了函数的类别,可以将其分组。

进行更多的转换
正如你可以想象的那样,转变是无止境的。甚至可能有比用例更多的转换方式。表13.2中列出的例子来自我的团队、各种客户问题和难题,以及Stack Overflow上的问题。GitHub资源库包含更多的实验室,说明了一些你可能需要的常见操作。
表 13.2 总结了与本章相关联的、在 GitHub 仓库中可获得的额外例子,网址是 https://github.com/jgperrin/net.jgp.books.spark.ch13。

摘要
Apache Spark是一个使用转换构建数据管道的伟大工具。
Spark可以用来扁平化JSON文档。
你可以在两个(或多个)Dataframe之间建立嵌套文件。
静态函数是数据转换的关键。它们在附录G和可下载的补充资料中都有描述,可在本书的在线目录http://jgp.net/sia。
GitHub资源库包括更多的文档转换的例子 来帮助你处理一些常见的情况。